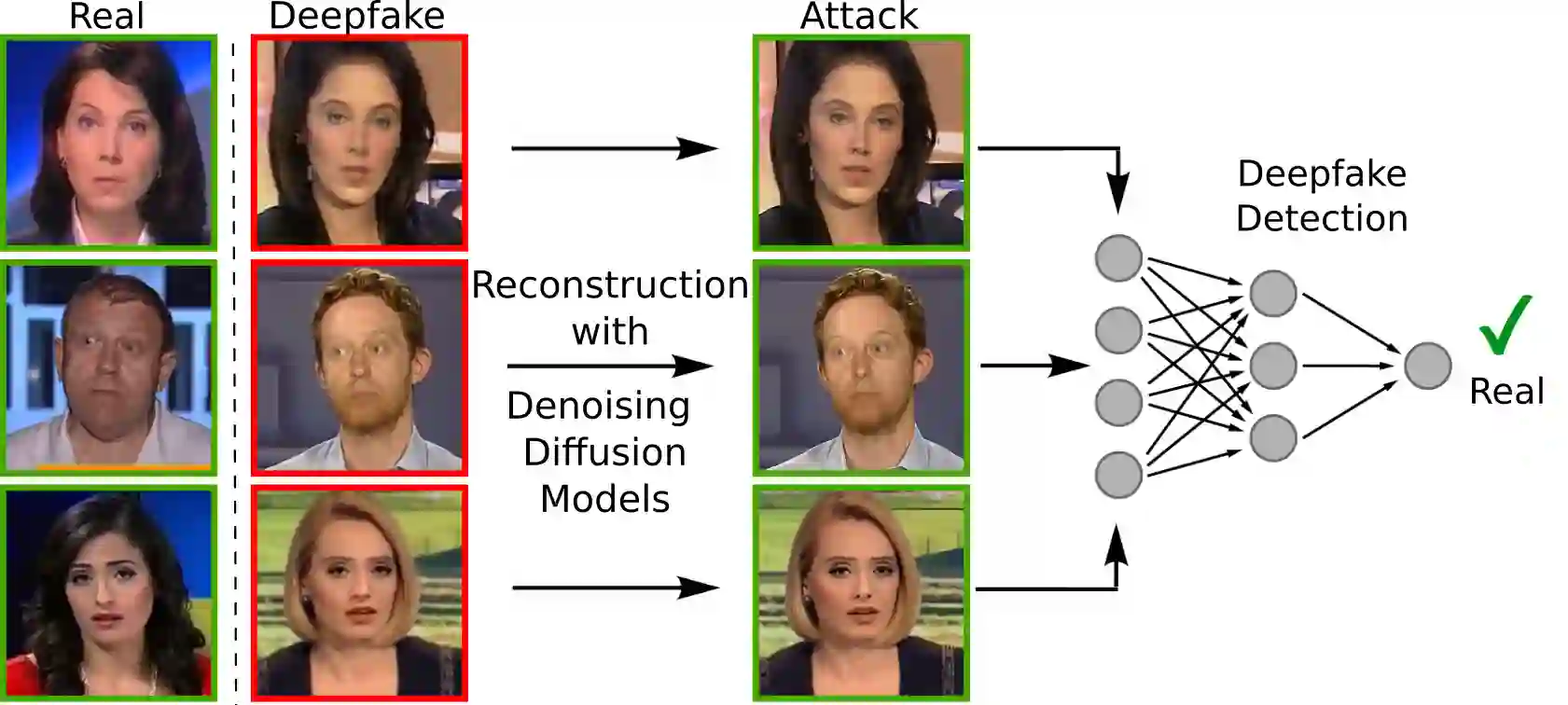
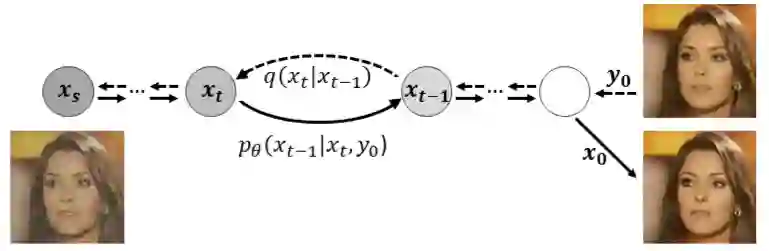
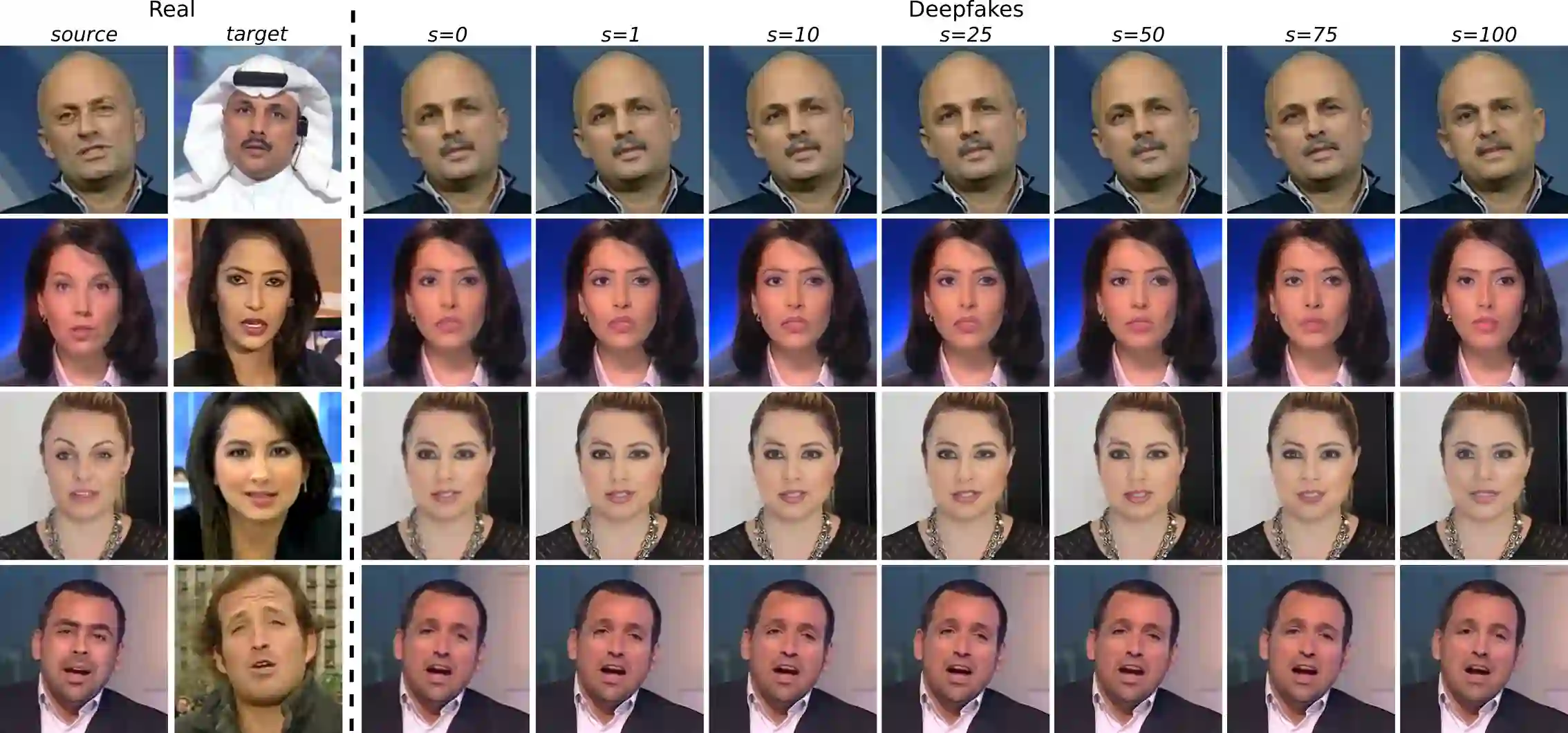
The detection of malicious deepfakes is a constantly evolving problem that requires continuous monitoring of detectors to ensure they can detect image manipulations generated by the latest emerging models. In this paper, we investigate the vulnerability of single-image deepfake detectors to black-box attacks created by the newest generation of generative methods, namely Denoising Diffusion Models (DDMs). Our experiments are run on FaceForensics++, a widely used deepfake benchmark consisting of manipulated images generated with various techniques for face identity swapping and face reenactment. Attacks are crafted through guided reconstruction of existing deepfakes with a proposed DDM approach for face restoration. Our findings indicate that employing just a single denoising diffusion step in the reconstruction process of a deepfake can significantly reduce the likelihood of detection, all without introducing any perceptible image modifications. While training detectors using attack examples demonstrated some effectiveness, it was observed that discriminators trained on fully diffusion-based deepfakes exhibited limited generalizability when presented with our attacks.
翻译:恶意深度伪造的检测是一个持续演变的问题,需要不断监测检测器,以确保其能够检测由最新涌现模型生成的图像篡改。本文研究了单图像深度伪造检测器对新一代生成方法——即去噪扩散模型(DDMs)所创建的黑盒攻击的脆弱性。实验基于FaceForensics++这一广泛使用的深度伪造基准数据集,该数据集包含采用多种人脸身份交换和人脸重演技术生成的篡改图像。攻击通过引导重建现有深度伪造图像实现,采用了一种我们提出的用于人脸恢复的DDM方法。研究结果表明,仅需在深度伪造图像的重建过程中使用单步去噪扩散,即可显著降低检测器识别率,且不引入任何可感知的图像修改。尽管使用攻击样本训练检测器展现出一定有效性,但观察到基于全扩散方法生成深度伪造图像训练的判别器,在面临我们的攻击时泛化能力有限。