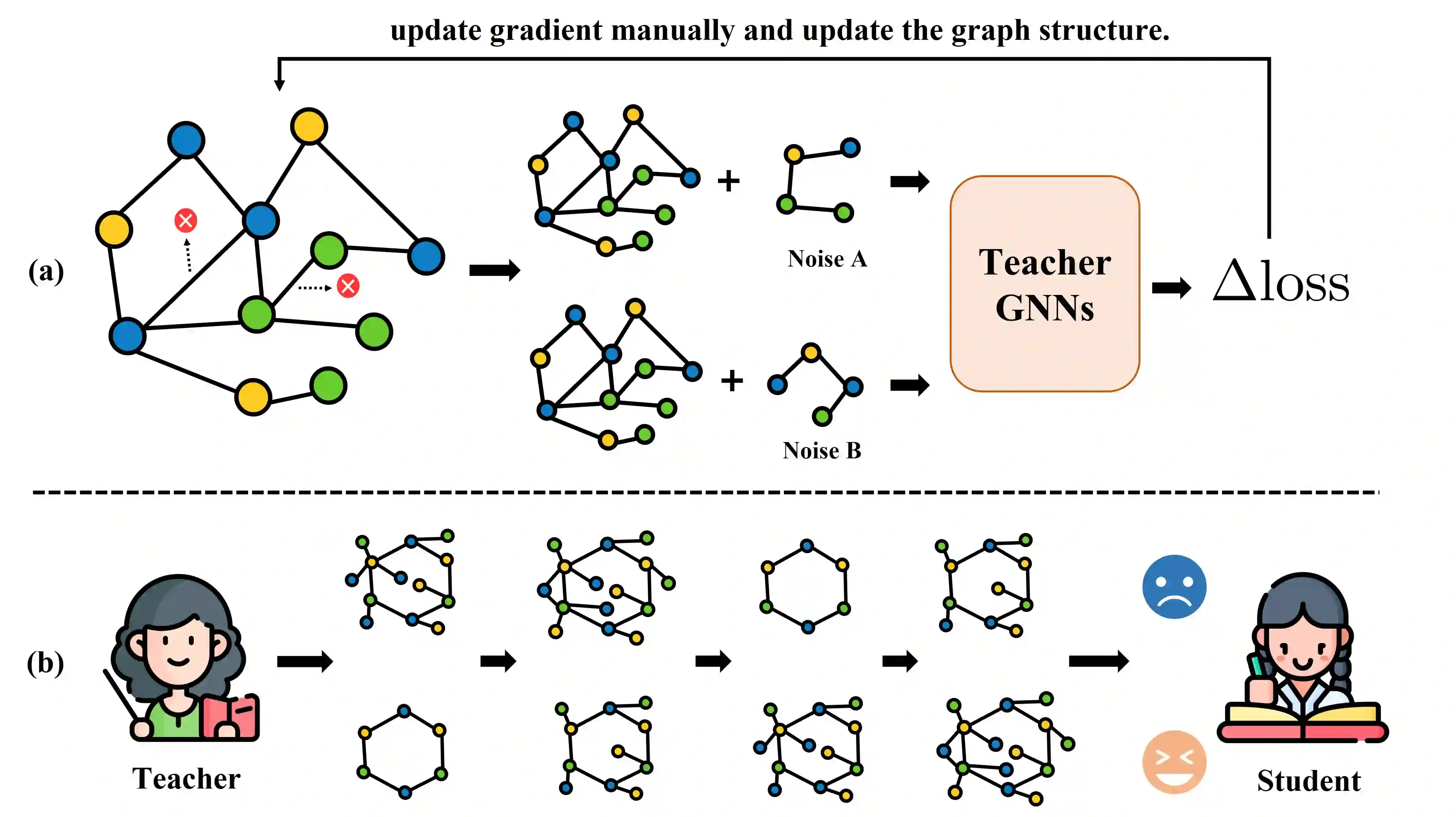
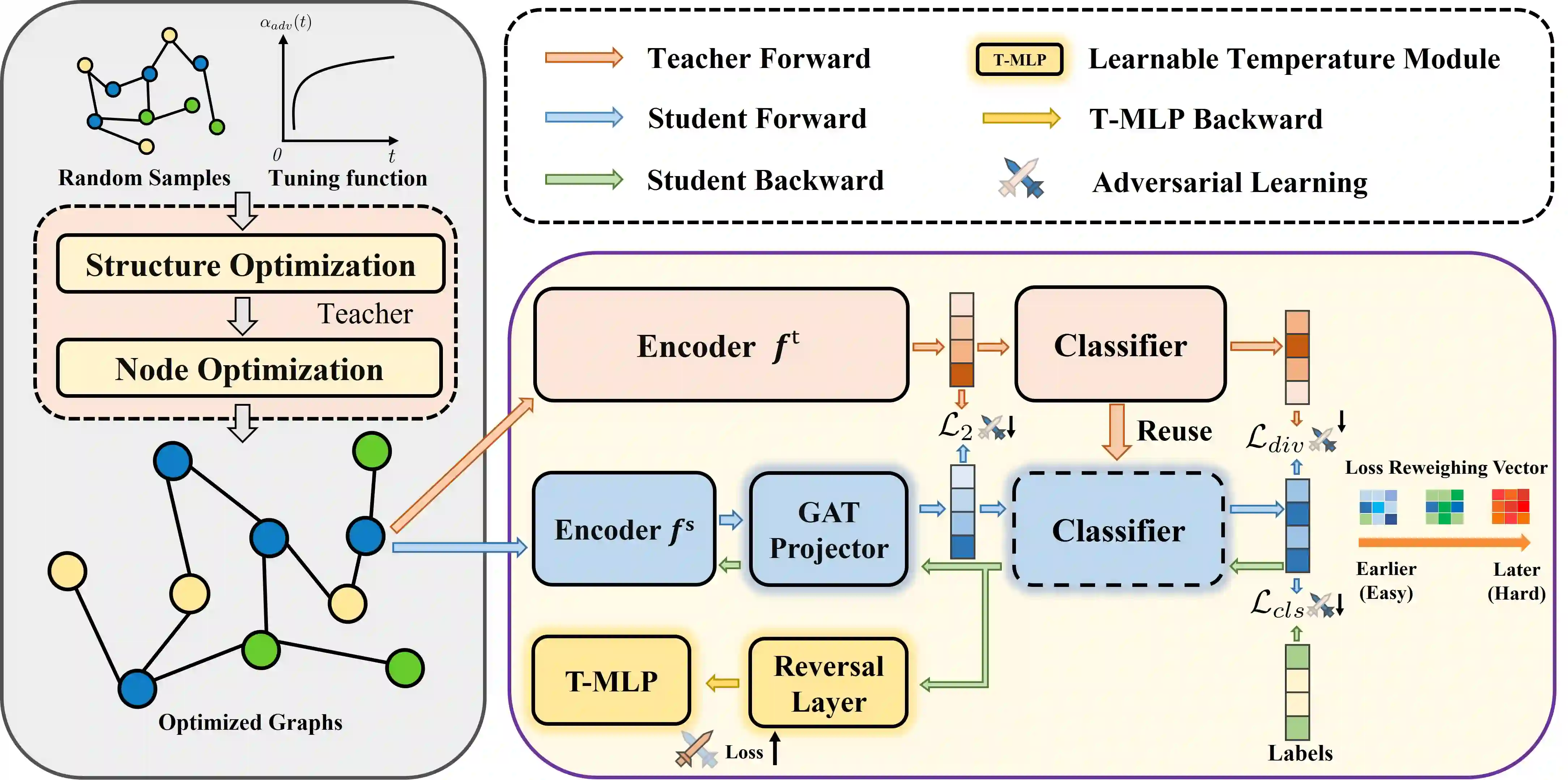
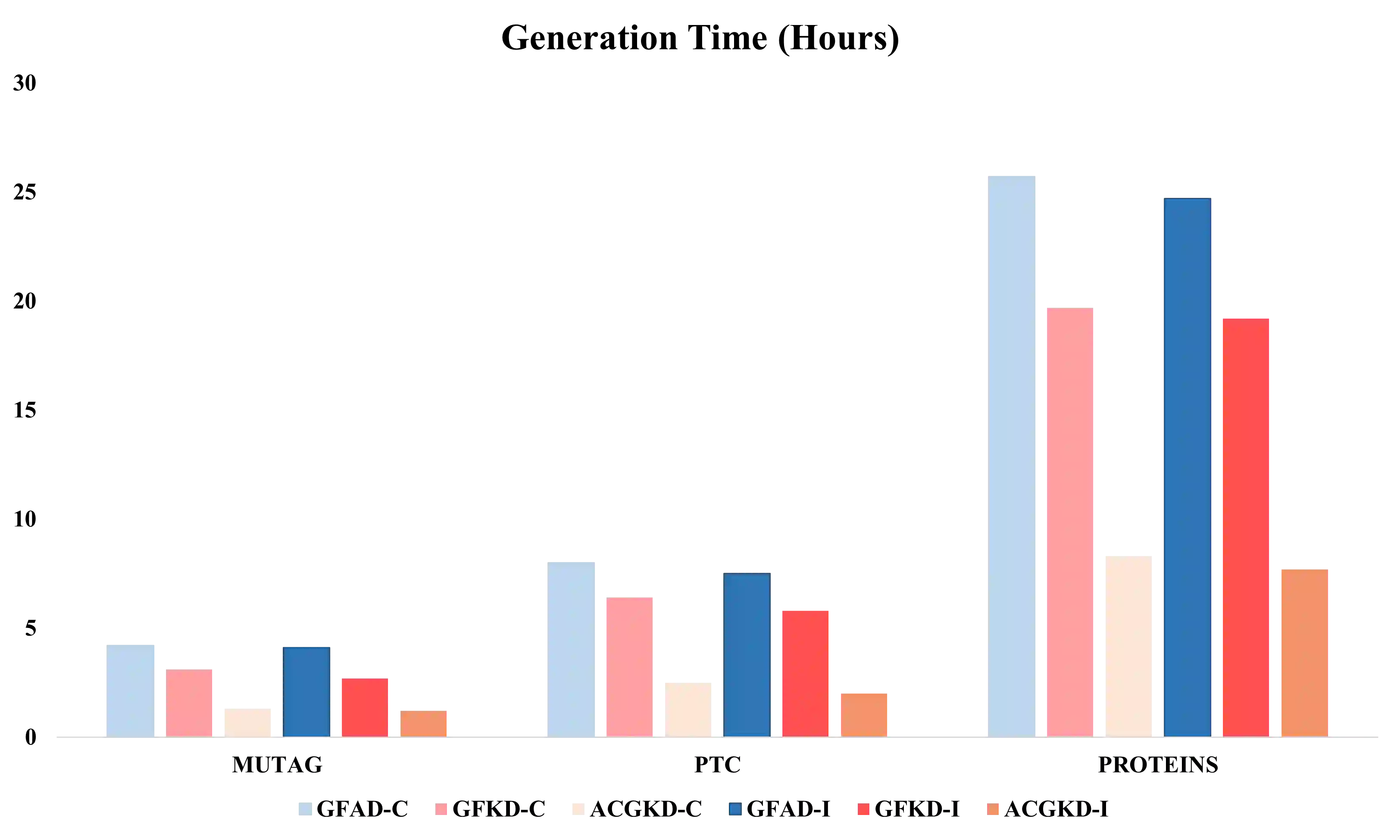
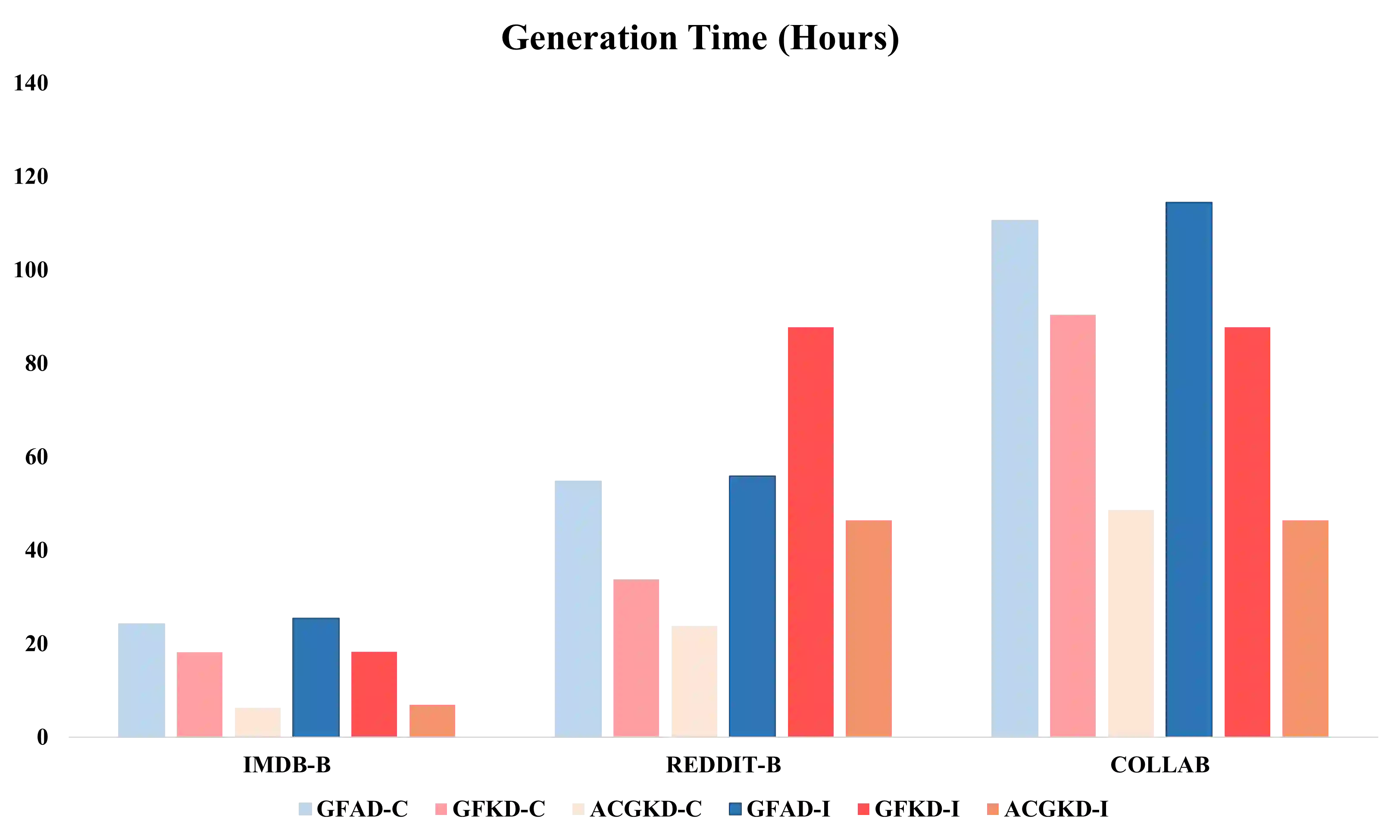
Data-free Knowledge Distillation (DFKD) is a method that constructs pseudo-samples using a generator without real data, and transfers knowledge from a teacher model to a student by enforcing the student to overcome dimensional differences and learn to mimic the teacher's outputs on these pseudo-samples. In recent years, various studies in the vision domain have made notable advancements in this area. However, the varying topological structures and non-grid nature of graph data render the methods from the vision domain ineffective. Building upon prior research into differentiable methods for graph neural networks, we propose a fast and high-quality data-free knowledge distillation approach in this paper. Without compromising distillation quality, the proposed graph-free KD method (ACGKD) significantly reduces the spatial complexity of pseudo-graphs by leveraging the Binary Concrete distribution to model the graph structure and introducing a spatial complexity tuning parameter. This approach enables efficient gradient computation for the graph structure, thereby accelerating the overall distillation process. Additionally, ACGKD eliminates the dimensional ambiguity between the student and teacher models by increasing the student's dimensions and reusing the teacher's classifier. Moreover, it equips graph knowledge distillation with a CL-based strategy to ensure the student learns graph structures progressively. Extensive experiments demonstrate that ACGKD achieves state-of-the-art performance in distilling knowledge from GNNs without training data.
翻译:无数据知识蒸馏是一种无需真实数据、通过生成器构建伪样本的方法,其通过强制学生模型克服维度差异并学习模仿教师模型在这些伪样本上的输出,实现知识从教师模型向学生模型的迁移。近年来,视觉领域的多项研究在此方向取得了显著进展。然而,图数据多变的拓扑结构与非网格特性使得视觉领域的方法难以直接适用。基于先前对图神经网络可微分方法的研究,本文提出了一种快速且高质量的无数据知识蒸馏方法。在保证蒸馏质量的前提下,所提出的图无数据知识蒸馏方法通过利用二元具体分布对图结构进行建模并引入空间复杂度调节参数,显著降低了伪图的空间复杂度。该方法实现了对图结构的高效梯度计算,从而加速了整体蒸馏过程。此外,该方法通过增加学生模型的维度并复用教师模型的分类器,消除了学生与教师模型间的维度模糊性。同时,该方法为图知识蒸馏引入了基于课程学习的策略,确保学生模型能够渐进式地学习图结构。大量实验表明,该图无数据知识蒸馏方法在无需训练数据的情况下,实现了从图神经网络中蒸馏知识的最先进性能。