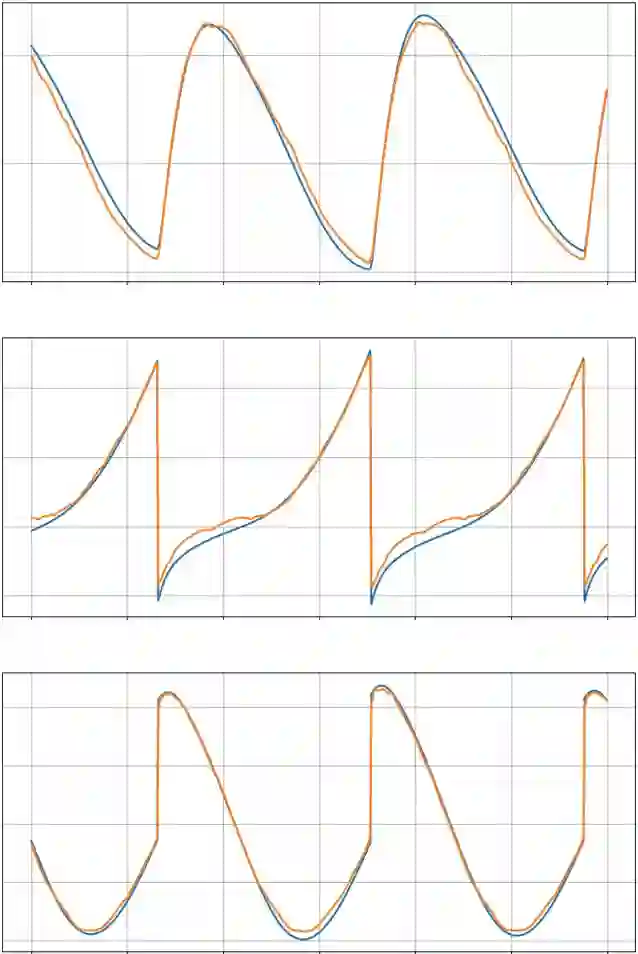
This paper presents a novel framework for learning robust bipedal walking by combining a data-driven state representation with a Reinforcement Learning (RL) based locomotion policy. The framework utilizes an autoencoder to learn a low-dimensional latent space that captures the complex dynamics of bipedal locomotion from existing locomotion data. This reduced dimensional state representation is then used as states for training a robust RL-based gait policy, eliminating the need for heuristic state selections or the use of template models for gait planning. The results demonstrate that the learned latent variables are disentangled and directly correspond to different gaits or speeds, such as moving forward, backward, or walking in place. Compared to traditional template model-based approaches, our framework exhibits superior performance and robustness in simulation. The trained policy effectively tracks a wide range of walking speeds and demonstrates good generalization capabilities to unseen scenarios.
翻译:本文提出了一种新颖的框架,通过将数据驱动的状态表征与基于强化学习的运动策略相结合,来实现鲁棒的双足行走。该框架利用自编码器从现有的运动数据中学习一个低维潜在空间,以捕捉双足运动的复杂动力学。随后,使用这种降维后的状态表征作为状态来训练基于强化学习的鲁棒步态策略,从而避免了启发式状态选择或使用模板模型进行步态规划的需要。结果表明,学习到的潜在变量是解耦的,并直接对应于不同的步态或速度,例如前进、后退或原地行走。与传统的基于模板模型的方法相比,我们的框架在仿真中表现出更优越的性能和鲁棒性。训练后的策略能够有效跟踪大范围的运动速度,并展现出对未见场景的良好泛化能力。