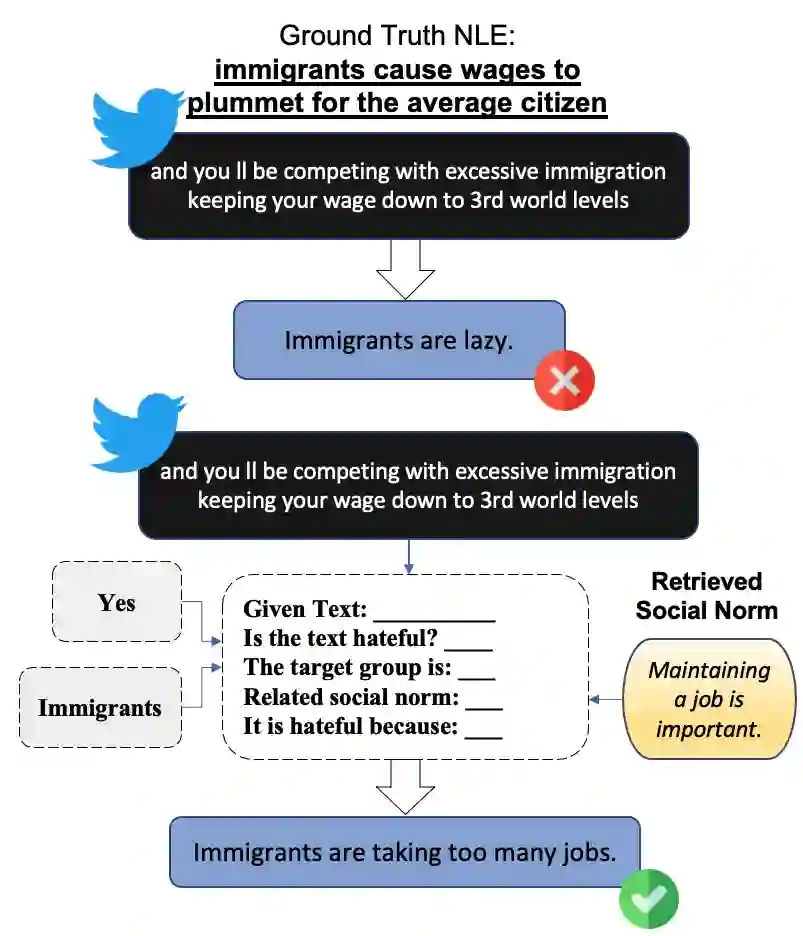
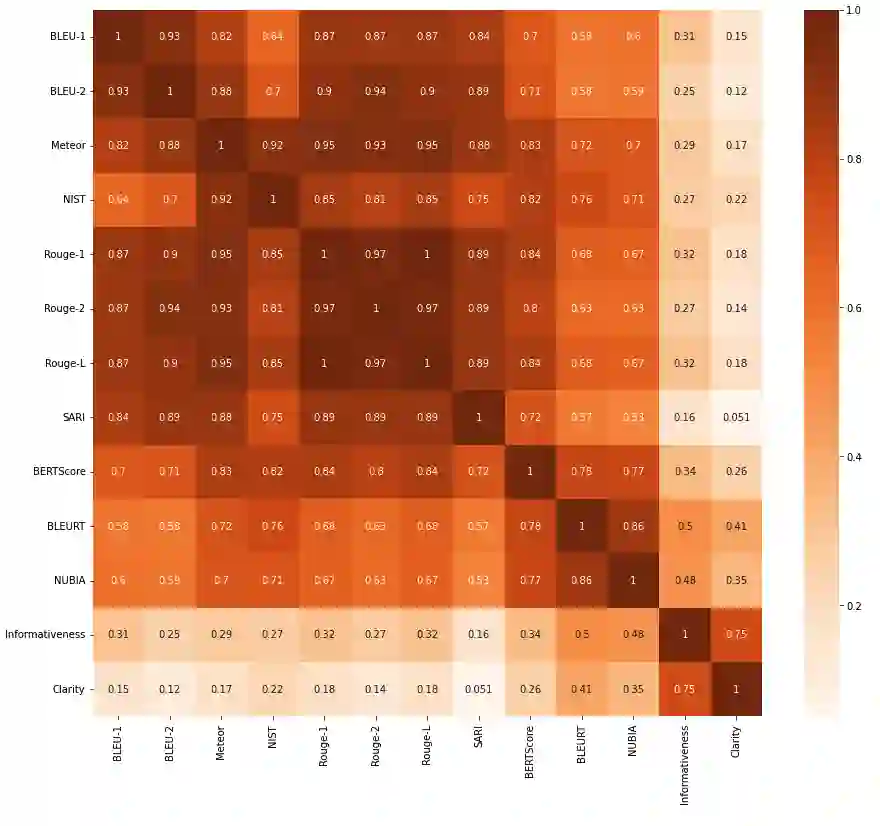
Recent studies have exploited advanced generative language models to generate Natural Language Explanations (NLE) for why a certain text could be hateful. We propose the Chain of Explanation (CoE) Prompting method, using the target group and retrieved social norms, to generate high-quality NLE for implicit hate speech. Providing accurate target information and high-quality related social norms, we improved the BLUE score from 44.0 to 62.3 for NLE generation. We then evaluate the quality of generated NLE from various automatic metrics and human annotations of informativeness and clarity scores. The correlation analysis between auto-metrics and human perceptions reveals insights into how to select suitable automatic metrics for Natural Language Generation tasks. To showcase a potential application of our proposed CoE method, we demonstrate the f1-score improvements from 0.635 to 0.655 for the implicit hate speech classification task.
翻译:近期研究利用先进生成式语言模型,为特定文本可能构成仇恨言论的原因生成自然语言解释(NLE)。我们提出"解释链"(CoE)提示方法,通过引入目标群体与检索得到的社会规范,为隐式仇恨言论生成高质量NLE。通过提供准确的目标信息与高质量的相关社会规范,我们将NLE生成的BLEU分数从44.0提升至62.3。继而从多项自动评估指标及人工标注的信息量、清晰度评分两个维度,对生成的NLE质量进行评价。通过分析自动指标与人类感知之间的相关性,揭示了为自然语言生成任务选择合适自动评估指标的要点。为展示所提出CoE方法的潜在应用价值,我们演示了隐式仇恨言论分类任务中F1分数从0.635提升至0.655的效果。