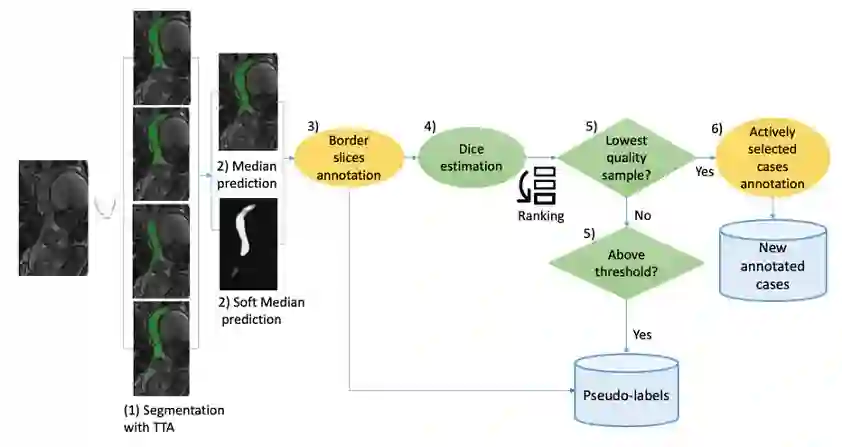
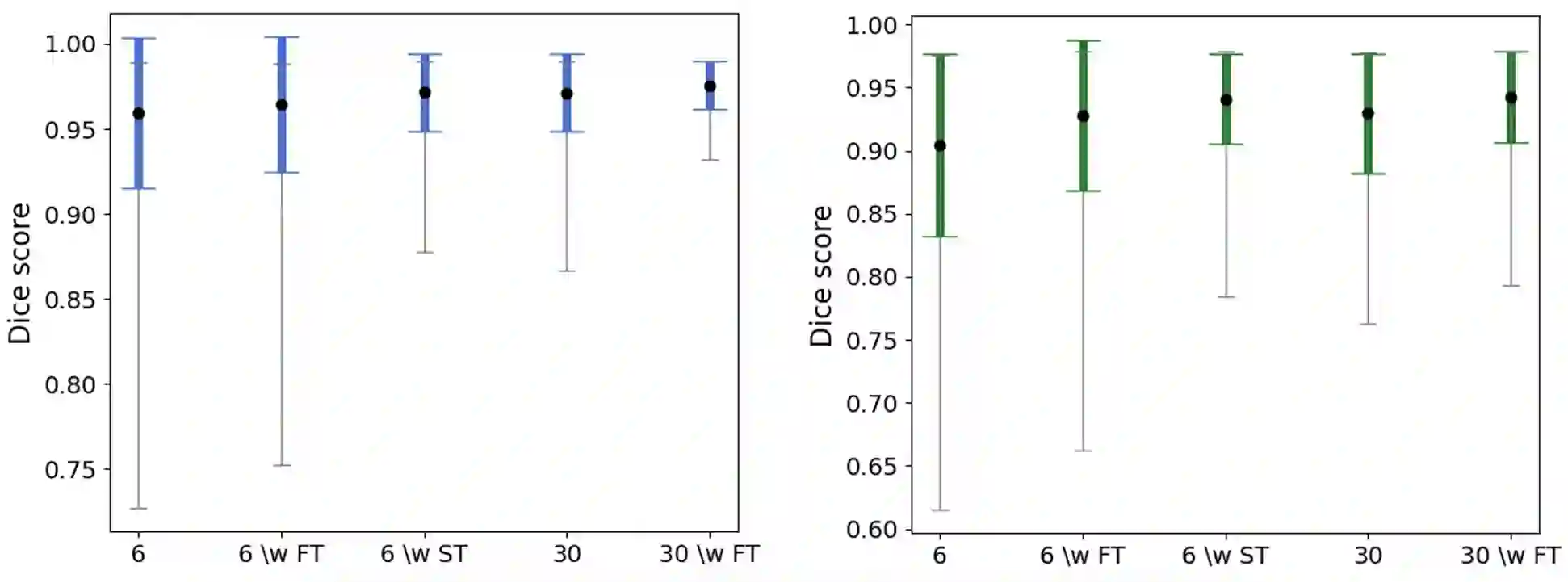
Deep learning techniques depend on large datasets whose annotation is time-consuming. To reduce annotation burden, the self-training (ST) and active-learning (AL) methods have been developed as well as methods that combine them in an iterative fashion. However, it remains unclear when each method is the most useful, and when it is advantageous to combine them. In this paper, we propose a new method that combines ST with AL using Test-Time Augmentations (TTA). First, TTA is performed on an initial teacher network. Then, cases for annotation are selected based on the lowest estimated Dice score. Cases with high estimated scores are used as soft pseudo-labels for ST. The selected annotated cases are trained with existing annotated cases and ST cases with border slices annotations. We demonstrate the method on MRI fetal body and placenta segmentation tasks with different data variability characteristics. Our results indicate that ST is highly effective for both tasks, boosting performance for in-distribution (ID) and out-of-distribution (OOD) data. However, while self-training improved the performance of single-sequence fetal body segmentation when combined with AL, it slightly deteriorated performance of multi-sequence placenta segmentation on ID data. AL was helpful for the high variability placenta data, but did not improve upon random selection for the single-sequence body data. For fetal body segmentation sequence transfer, combining AL with ST following ST iteration yielded a Dice of 0.961 with only 6 original scans and 2 new sequence scans. Results using only 15 high-variability placenta cases were similar to those using 50 cases. Code is available at: https://github.com/Bella31/TTA-quality-estimation-ST-AL
翻译:深度学习技术依赖于需要耗时标注的大规模数据集。为减轻标注负担,研究人员开发了自训练(ST)和主动学习(AL)方法,以及将两者以迭代方式结合的技术。然而,目前尚不清楚每种方法在何种情况下最为有效,以及何时将它们结合具有优势。本文提出一种新方法,通过测试时增强(TTA)将自训练与主动学习相结合。首先,对初始教师网络执行测试时增强。然后,基于最低估计Dice分数选择待标注样本。高估计分数的样本被用作自训练的软伪标签。所选标注样本与现有标注样本及带有边界切片标注的自训练样本一起进行训练。我们在具有不同数据变异特征的MRI胎儿体部和胎盘分割任务上验证了该方法。结果表明,自训练对两项任务均高度有效,能提升分布内(ID)和分布外(OOD)数据的性能。然而,当自训练与主动学习结合时,虽能改善单序列胎儿体部分割性能,却略微降低了分布内数据上多序列胎盘分割的性能。主动学习对高变异性胎盘数据有帮助,但对单序列体部数据而言并未优于随机选择。在胎儿体部分割序列迁移任务中,经过自训练迭代后结合主动学习与自训练,仅需6个原始扫描和2个新序列扫描即可达到0.961的Dice分数。仅使用15例高变异性胎盘案例的结果与使用50例相接近。代码获取地址:https://github.com/Bella31/TTA-quality-estimation-ST-AL