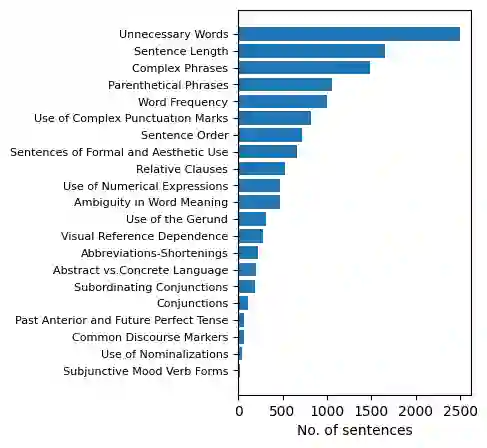
Text simplification, crucial in natural language processing, aims to make texts more comprehensible, particularly for specific groups like visually impaired Spanish speakers, a less-represented language in this field. In Spanish, there are few datasets that can be used to create text simplification systems. Our research has the primary objective to develop a Spanish financial text simplification dataset. We created a dataset with 5,314 complex and simplified sentence pairs using established simplification rules. We also compared our dataset with the simplifications generated from GPT-3, Tuner, and MT5, in order to evaluate the feasibility of data augmentation using these systems. In this manuscript we present the characteristics of our dataset and the findings of the comparisons with other systems. The dataset is available at Hugging face, saul1917/FEINA.
翻译:文本简化是自然语言处理中的关键任务,旨在使文本更易于理解,尤其适用于特定群体,如视力受损的西班牙语使用者——西班牙语在这一领域中属于资源匮乏的语言。目前,可用于构建文本简化系统的西班牙语数据集十分有限。本研究的主要目标是开发一个西班牙语金融文本简化数据集。我们基于既定的简化规则,构建了一个包含5,314组复杂句与简化句对的数据集。此外,我们将该数据集与GPT-3、Tuner和MT5生成的简化结果进行对比,以评估利用这些系统进行数据增强的可行性。本文介绍了该数据集的特征及与其他系统对比的发现。该数据集已在Hugging Face平台公开,标识为saul1917/FEINA。