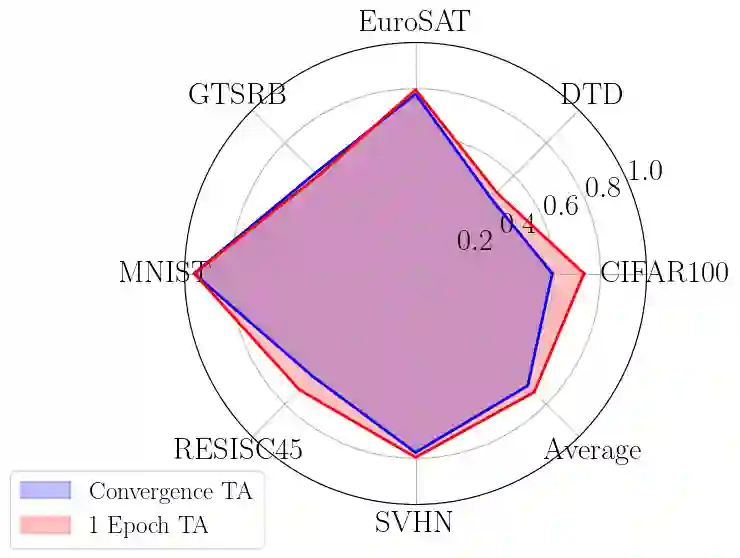
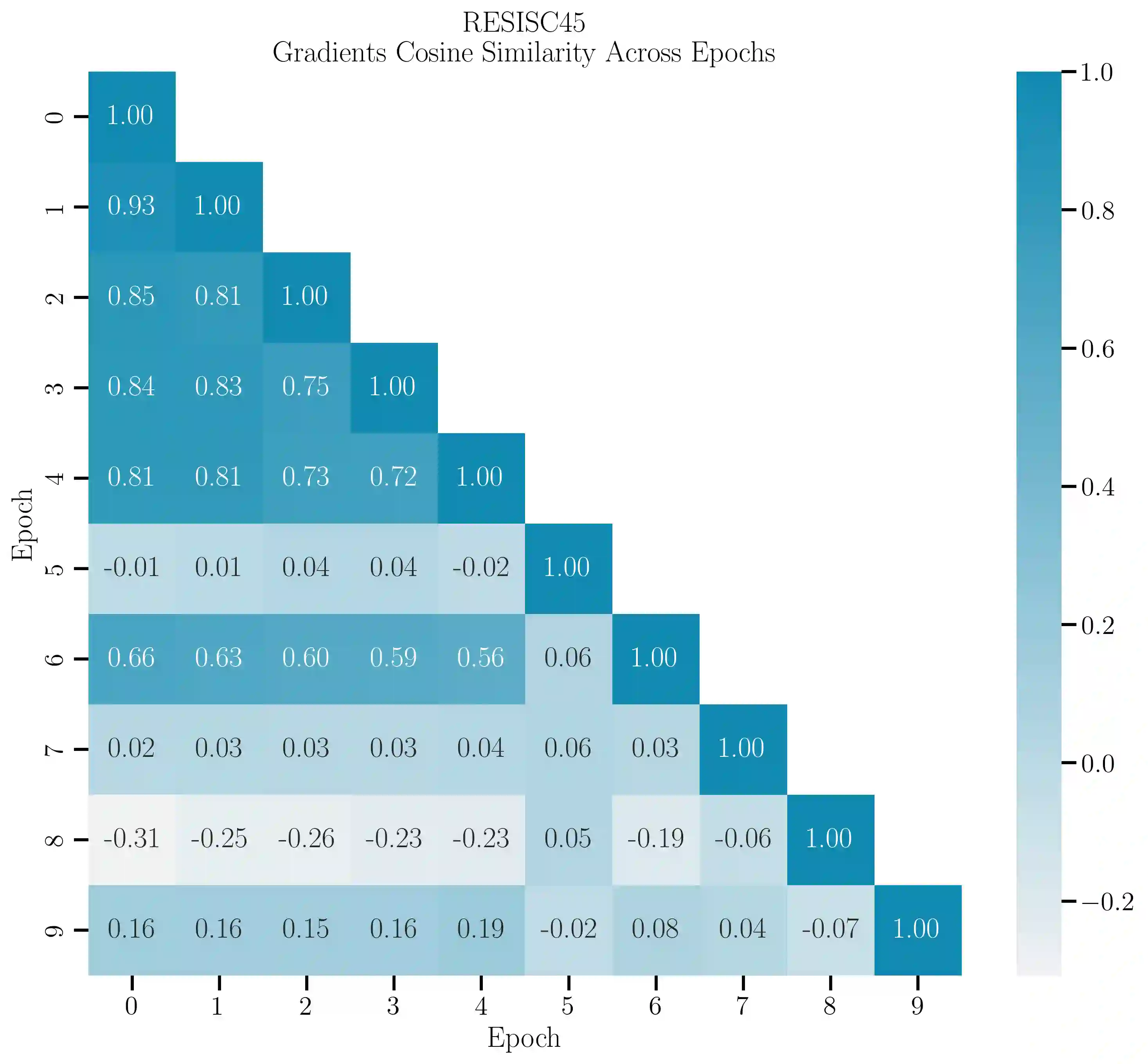
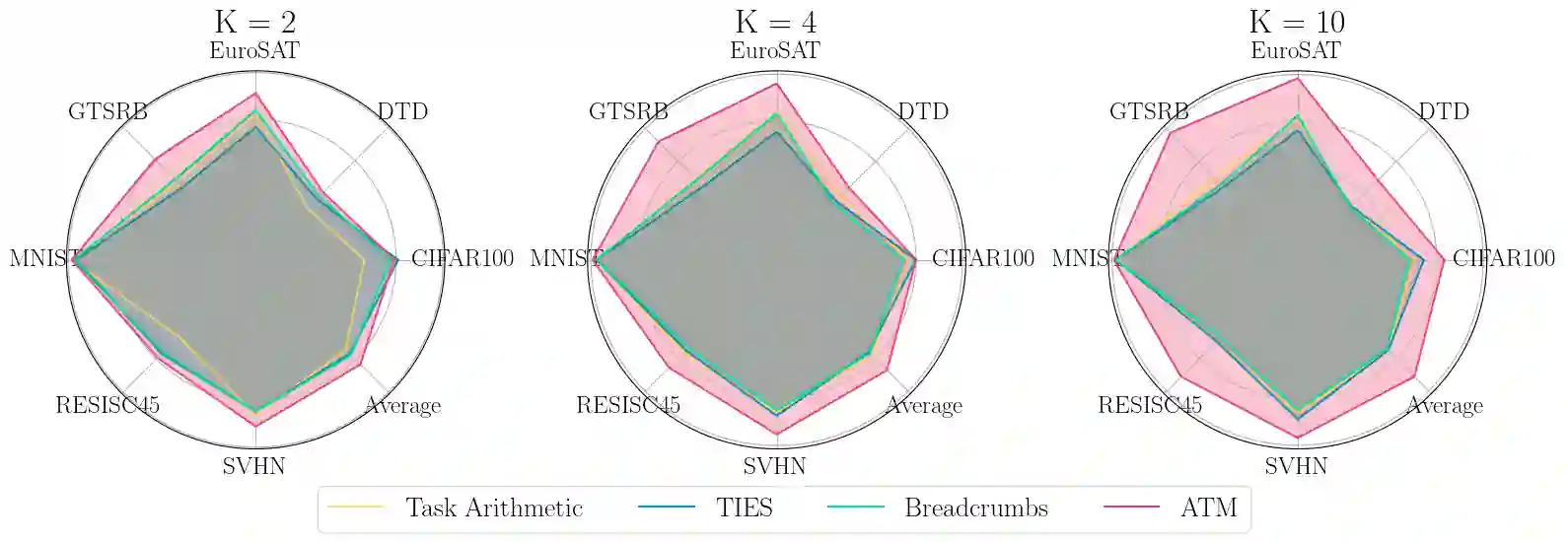
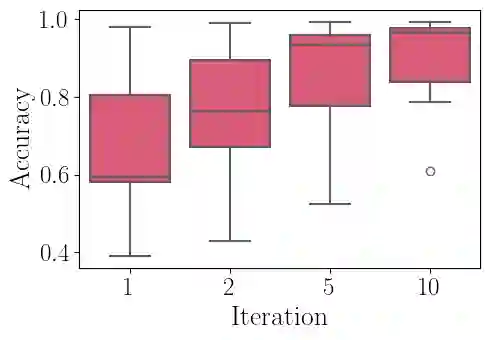
Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic stands out for its simplicity and effectiveness. In this paper, we motivate the effectiveness of task vectors by linking them to multi-task gradients. We show that in a single-epoch scenario, task vectors are mathematically equivalent to the gradients obtained via gradient descent in a multi-task setting, and still approximate these gradients in subsequent epochs. Furthermore, we show that task vectors perform optimally when equality is maintained, and their effectiveness is largely driven by the first epoch's gradient. Building on this insight, we propose viewing model merging as a single step in an iterative process that Alternates between Tuning and Merging (ATM). This method acts as a bridge between model merging and multi-task gradient descent, achieving state-of-the-art results with the same data and computational requirements. We extensively evaluate ATM across diverse settings, achieving up to 20% higher accuracy in computer vision and NLP tasks, compared to the best baselines. Finally, we provide both empirical and theoretical support for its effectiveness, demonstrating increased orthogonality between task vectors and proving that ATM minimizes an upper bound on the loss obtained by jointly finetuning all tasks.
翻译:模型融合最近已成为多任务学习中一种成本效益显著的范式。在现有方法中,任务算术因其简洁性与高效性尤为突出。本文通过将任务向量与多任务梯度相关联,阐释了其有效性原理。我们证明,在单轮训练场景下,任务向量在数学上等价于通过多任务梯度下降获得的梯度,并在后续训练轮次中仍能近似这些梯度。此外,我们发现当保持等式关系时任务向量达到最优效果,且其有效性主要由首轮训练的梯度驱动。基于这一洞见,我们提出将模型融合视为交替调优与合并迭代过程中的单一步骤。该方法作为模型融合与多任务梯度下降之间的桥梁,在相同数据与计算需求下实现了最先进的性能。我们在多样化场景中对ATM进行了全面评估,相比最佳基线方法,在计算机视觉与自然语言处理任务中实现了最高20%的准确率提升。最后,我们通过实证与理论分析验证了其有效性:实验表明任务向量间的正交性显著增强,理论证明则显示ATM能够最小化所有任务联合微调所获损失的上界。