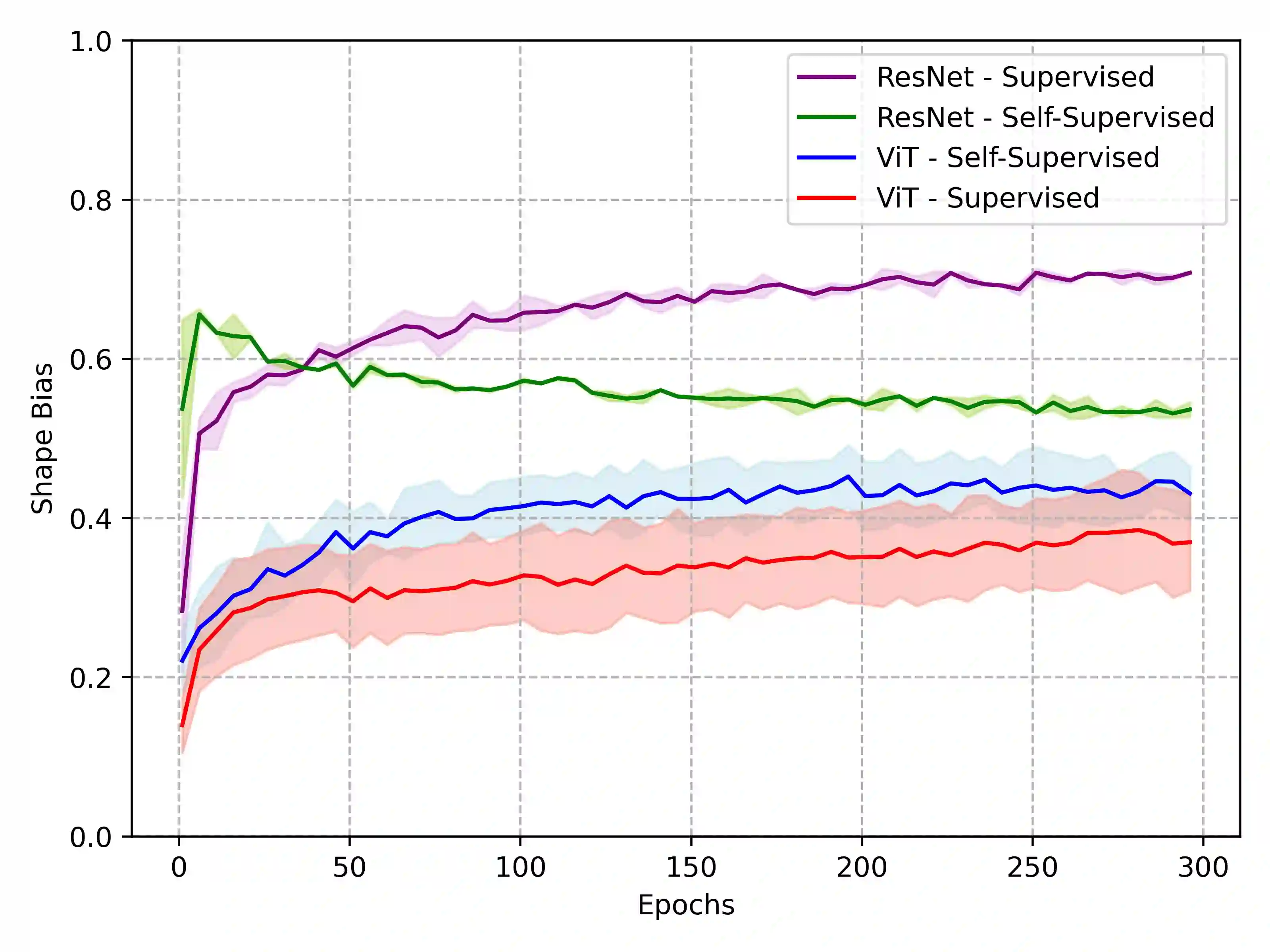
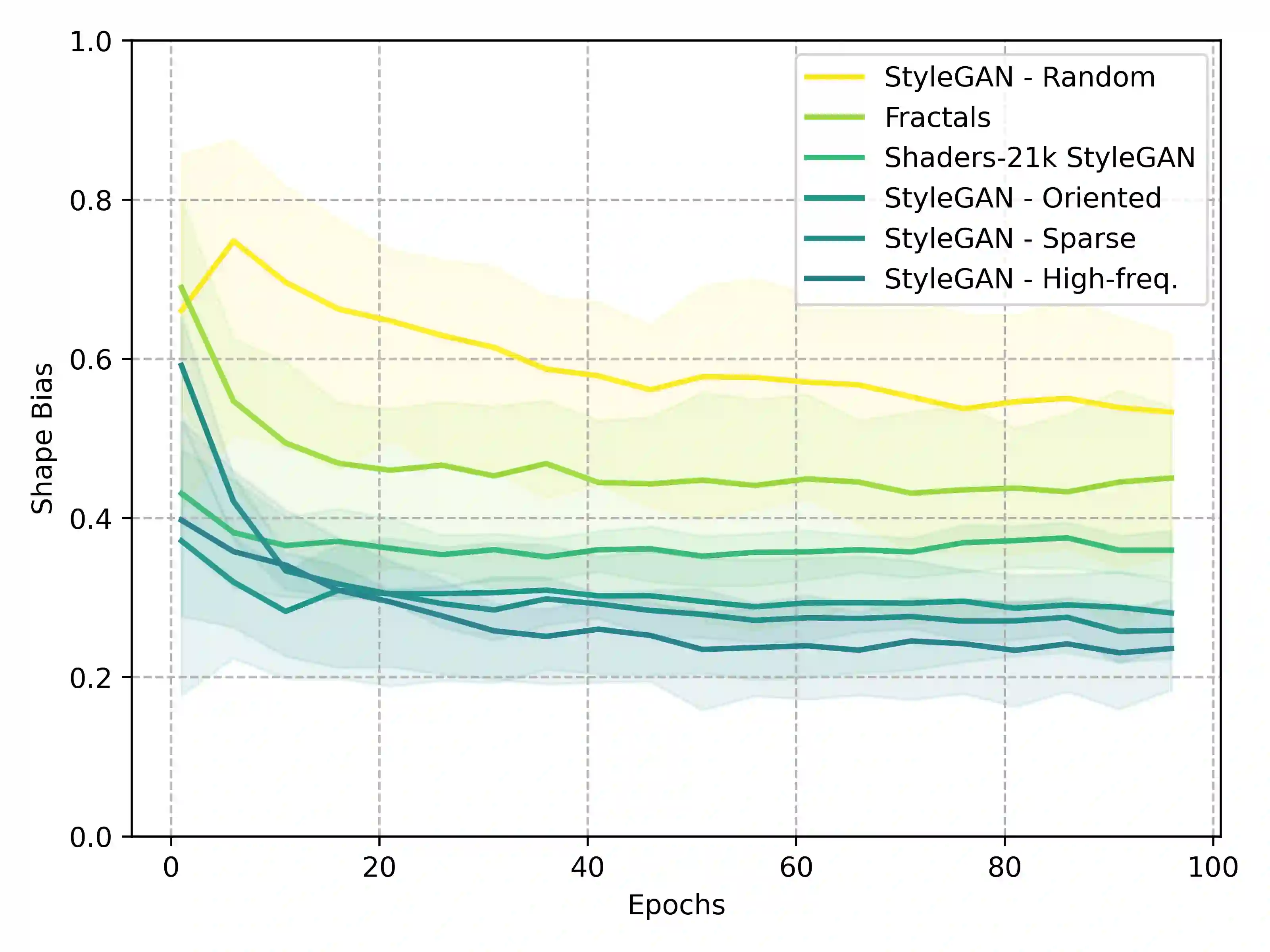
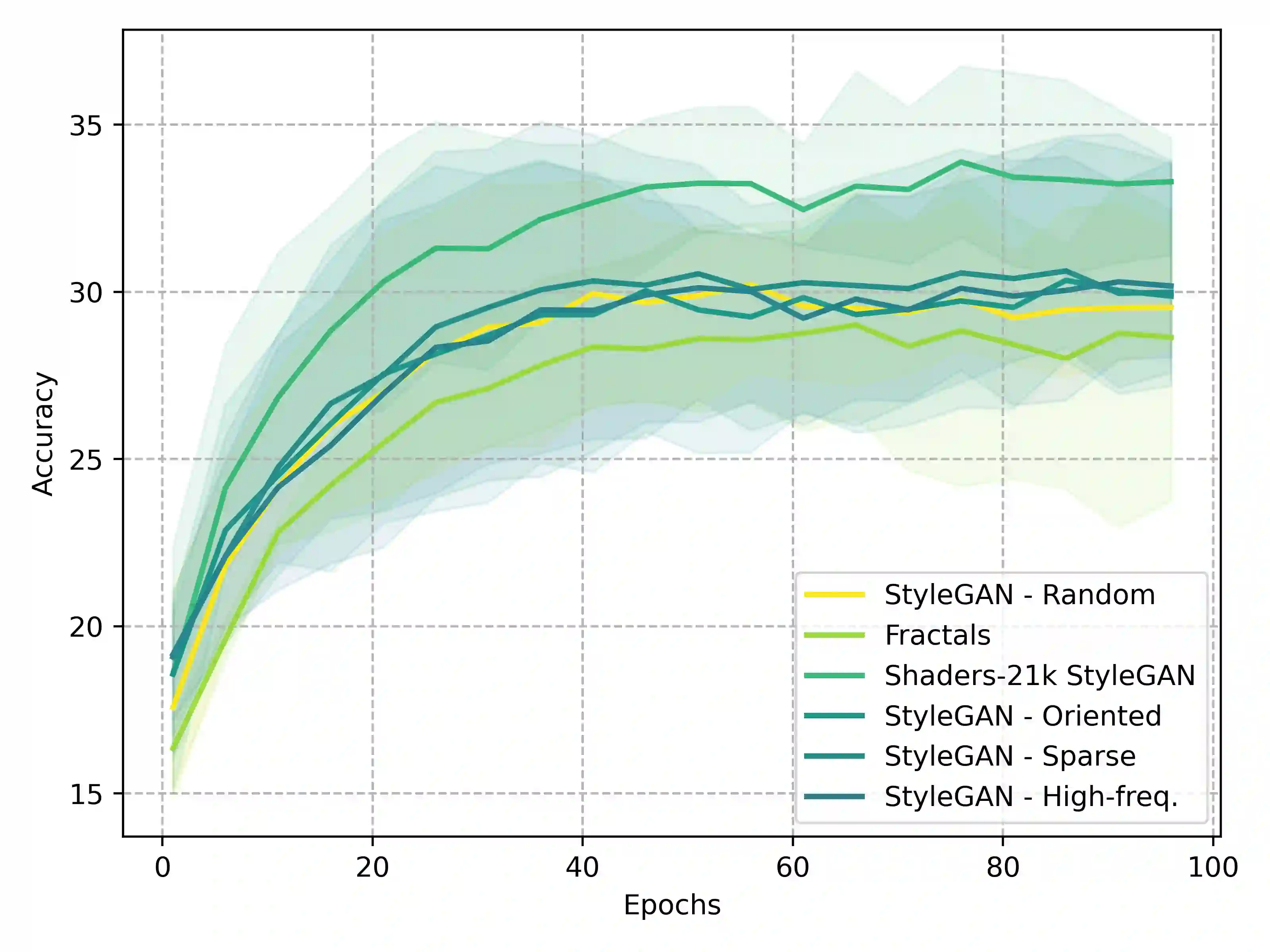
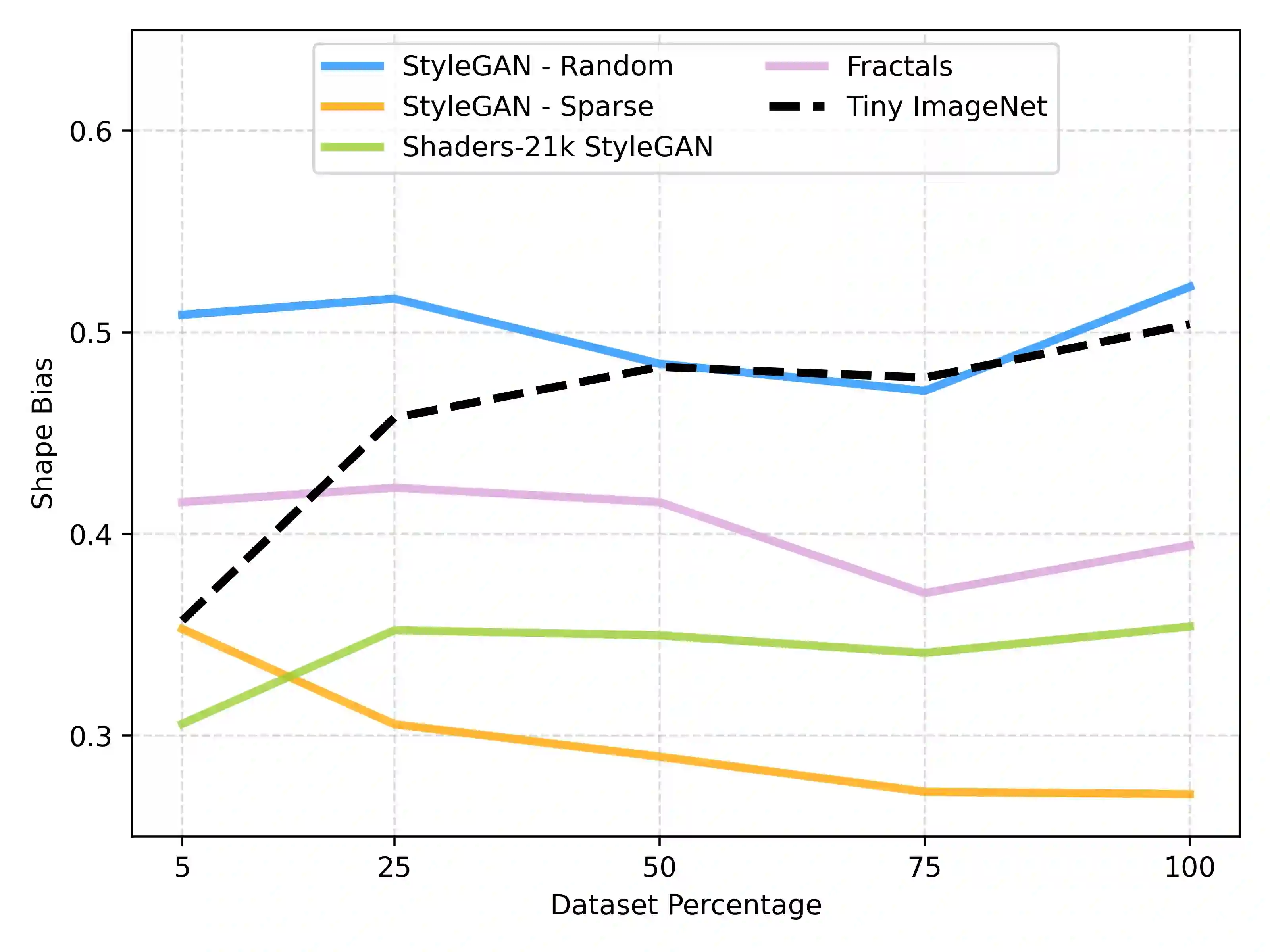
Recent advancements in deep learning have been primarily driven by the use of large models trained on increasingly vast datasets. While neural scaling laws have emerged to predict network performance given a specific level of computational resources, the growing demand for expansive datasets raises concerns. To address this, a new research direction has emerged, focusing on the creation of synthetic data as a substitute. In this study, we investigate how neural networks exhibit shape bias during training on synthetic datasets, serving as an indicator of the synthetic data quality. Specifically, our findings indicate three key points: (1) Shape bias varies across network architectures and types of supervision, casting doubt on its reliability as a predictor for generalization and its ability to explain differences in model recognition compared to human capabilities. (2) Relying solely on shape bias to estimate generalization is unreliable, as it is entangled with diversity and naturalism. (3) We propose a novel interpretation of shape bias as a tool for estimating the diversity of samples within a dataset. Our research aims to clarify the implications of using synthetic data and its associated shape bias in deep learning, addressing concerns regarding generalization and dataset quality.
翻译:近期深度学习的进展主要得益于在日益庞大的数据集上训练大型模型。虽然神经扩展律的出现能够根据特定计算资源水平预测网络性能,但不断增长的庞大数据集需求引发了担忧。为解决这一问题,一个新兴研究方向聚焦于创建合成数据作为替代方案。在本研究中,我们探究神经网络在合成数据集训练过程中展现的形状偏好,将其作为合成数据质量的指示指标。具体而言,我们的发现表明三个关键点:(1)形状偏好因网络架构和监督类型而异,这对其作为泛化预测指标的可靠性及其解释模型与人类识别能力差异的能力提出了质疑。(2)仅依赖形状偏好估计泛化性能并不可靠,因为它与多样性和自然性相互纠缠。(3)我们提出将形状偏好解释为评估数据集内样本多样性工具的新颖视角。本研究旨在阐明深度学习中使用合成数据及其相关形状偏好的影响,以应对泛化性能与数据集质量方面的关切。