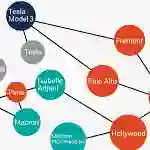
In the ever-evolving landscape of natural language processing and information retrieval, the need for robust and domain-specific entity linking algorithms has become increasingly apparent. It is crucial in a considerable number of fields such as humanities, technical writing and biomedical sciences to enrich texts with semantics and discover more knowledge. The use of Named Entity Disambiguation (NED) in such domains requires handling noisy texts, low resource settings and domain-specific KBs. Existing approaches are mostly inappropriate for such scenarios, as they either depend on training data or are not flexible enough to work with domain-specific KBs. Thus in this work, we present an unsupervised approach leveraging the concept of Group Steiner Trees (GST), which can identify the most relevant candidates for entity disambiguation using the contextual similarities across candidate entities for all the mentions present in a document. We outperform the state-of-the-art unsupervised methods by more than 40\% (in avg.) in terms of Precision@1 across various domain-specific datasets.
翻译:在自然语言处理与信息检索不断演进的背景下,对鲁棒且领域特定的实体链接算法的需求日益凸显。在人文学科、技术写作与生物医学等诸多领域,为文本赋予语义并挖掘更多知识至关重要。在这些领域中应用命名实体消歧(NED)需要处理噪声文本、低资源场景以及领域特定的知识库。现有方法大多不适用于此类场景,因为它们要么依赖于训练数据,要么灵活性不足,难以与领域特定知识库协同工作。因此,本研究提出一种利用组斯坦纳树(GST)概念的无监督方法,该方法能够通过文档中所有提及实体的候选实体间的上下文相似性,识别出最相关的候选实体以进行消歧。在多个领域特定数据集上,我们的方法在Precision@1指标上平均超越当前最先进的无监督方法40%以上。