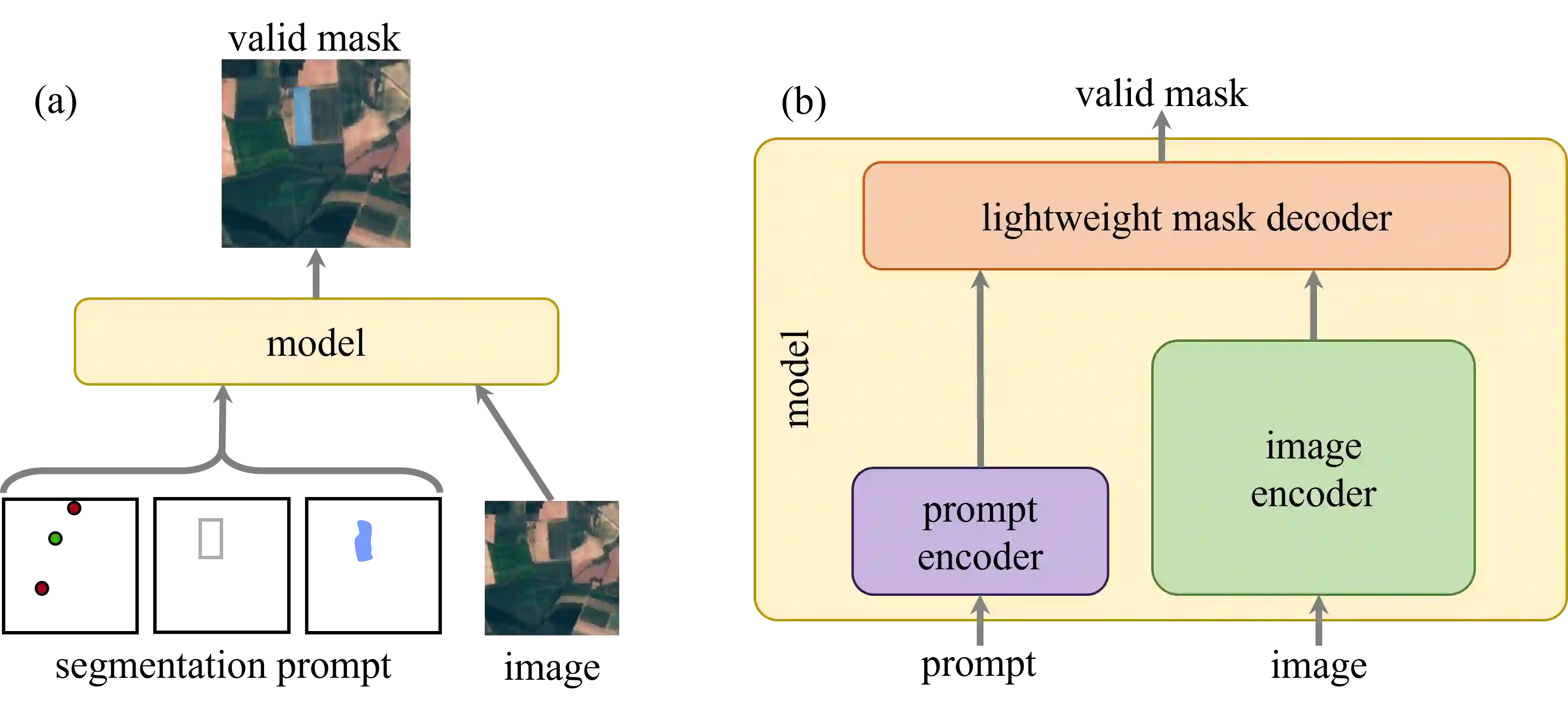
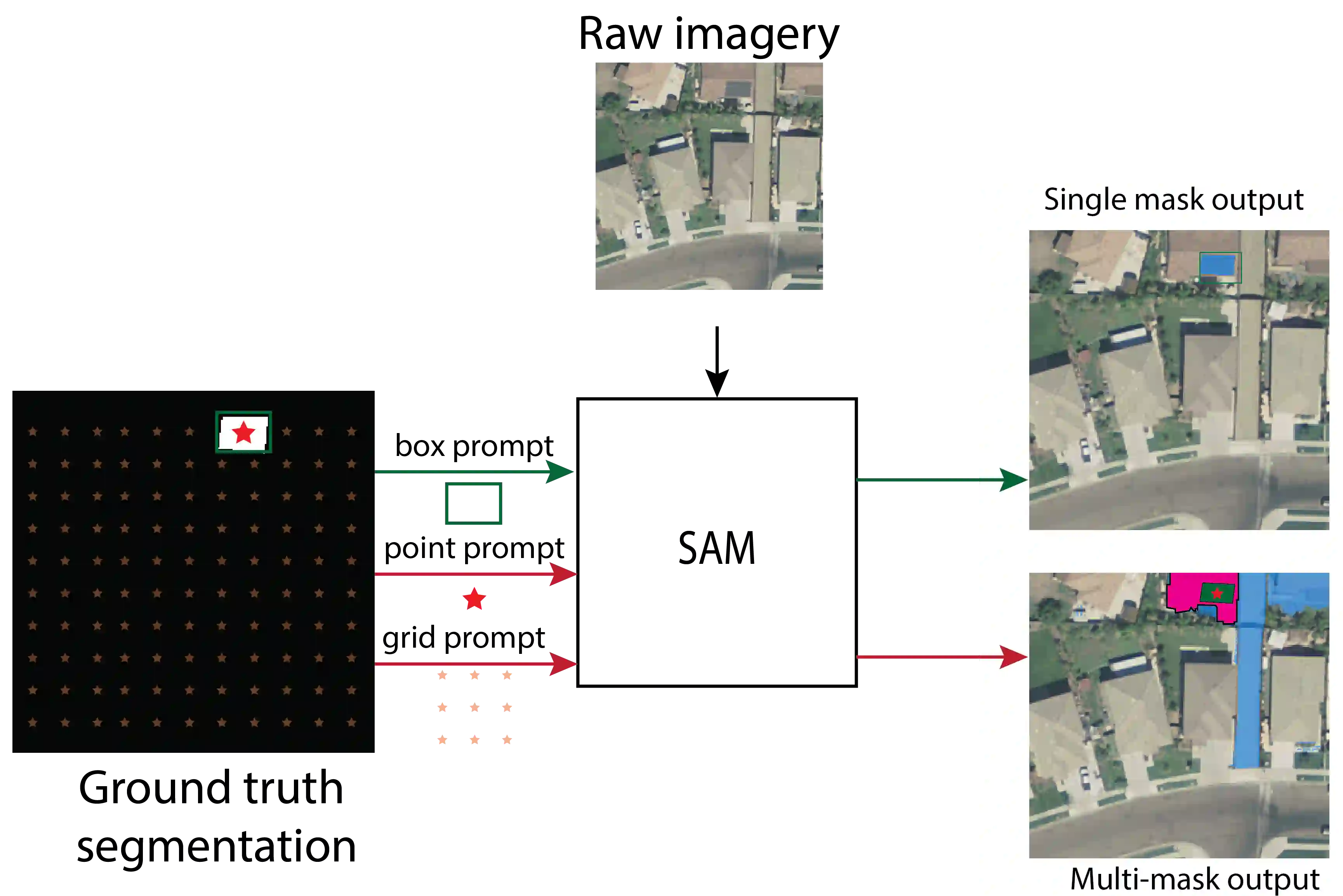
Recently, the first foundation model developed specifically for vision tasks was developed, termed the "Segment Anything Model" (SAM). SAM can segment objects in input imagery based upon cheap input prompts, such as one (or more) points, a bounding box, or a mask. The authors examined the zero-shot image segmentation accuracy of SAM on a large number of vision benchmark tasks and found that SAM usually achieved recognition accuracy similar to, or sometimes exceeding, vision models that had been trained on the target tasks. The impressive generalization of SAM for segmentation has major implications for vision researchers working on natural imagery. In this work, we examine whether SAM's impressive performance extends to overhead imagery problems, and help guide the community's response to its development. We examine SAM's performance on a set of diverse and widely-studied benchmark tasks. We find that SAM does often generalize well to overhead imagery, although it fails in some cases due to the unique characteristics of overhead imagery and the target objects. We report on these unique systematic failure cases for remote sensing imagery that may comprise useful future research for the community. Note that this is a working paper, and it will be updated as additional analysis and results are completed.
翻译:近日,首个专门为视觉任务开发的基础模型——"分割一切模型"(SAM)——问世。SAM能够基于简单的输入提示(如一个或多个点、边界框或掩膜)对输入图像中的目标进行分割。作者在大量视觉基准任务上检验了SAM的零样本图像分割精度,发现其识别准确率通常与在目标任务上训练过的视觉模型相当,有时甚至更优。SAM在分割任务上令人印象深刻的泛化能力,对研究自然图像的视觉领域研究者具有重大意义。本研究旨在探讨SAM的卓越性能是否也能延伸至遥感影像问题,从而引导学界对其发展作出回应。我们选取一系列多样且被广泛研究的基准任务评估SAM的表现,发现SAM在多数情况下能较好地泛化至遥感影像,但因遥感影像及目标对象的独特性,在某些案例中仍存在失败情况。本文报告了这些遥感影像特有的系统性失败案例,或可为后续研究提供方向。请注意,本文为工作论文,后续分析及结果完成后将进行更新。