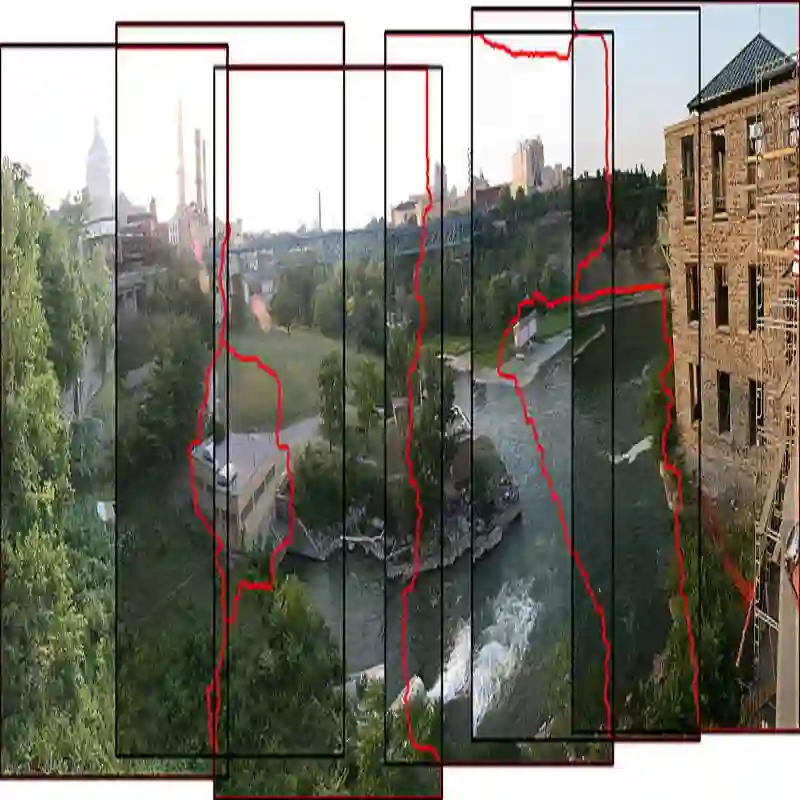
Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
翻译:全景图像拼接提供了一种统一、广角的场景视图,超越了相机的视野范围。对于静态场景,将平移视频的帧拼接成全景照片是一个已得到充分理解的问题;但当物体移动时,静态全景图无法捕捉场景动态。本文提出了一种从随意拍摄的平移视频合成全景视频的方法,使合成结果如同使用广角相机拍摄原始视频一般。我们将全景合成建模为一个时空外绘问题,旨在生成与输入视频时长相同的完整全景视频。时空体的一致性补全需要对视频内容与运动具备强大且真实的先验知识,为此我们适配了生成式视频模型。然而,如我们所示,现有生成模型并不能直接扩展至全景补全任务。相反,我们将视频生成作为全景合成系统的一个组件,并展示了如何充分利用模型优势同时最小化其局限性。我们的系统能够为包括人物、车辆、流水以及静态背景特征在内的多种真实场景创建视频全景。