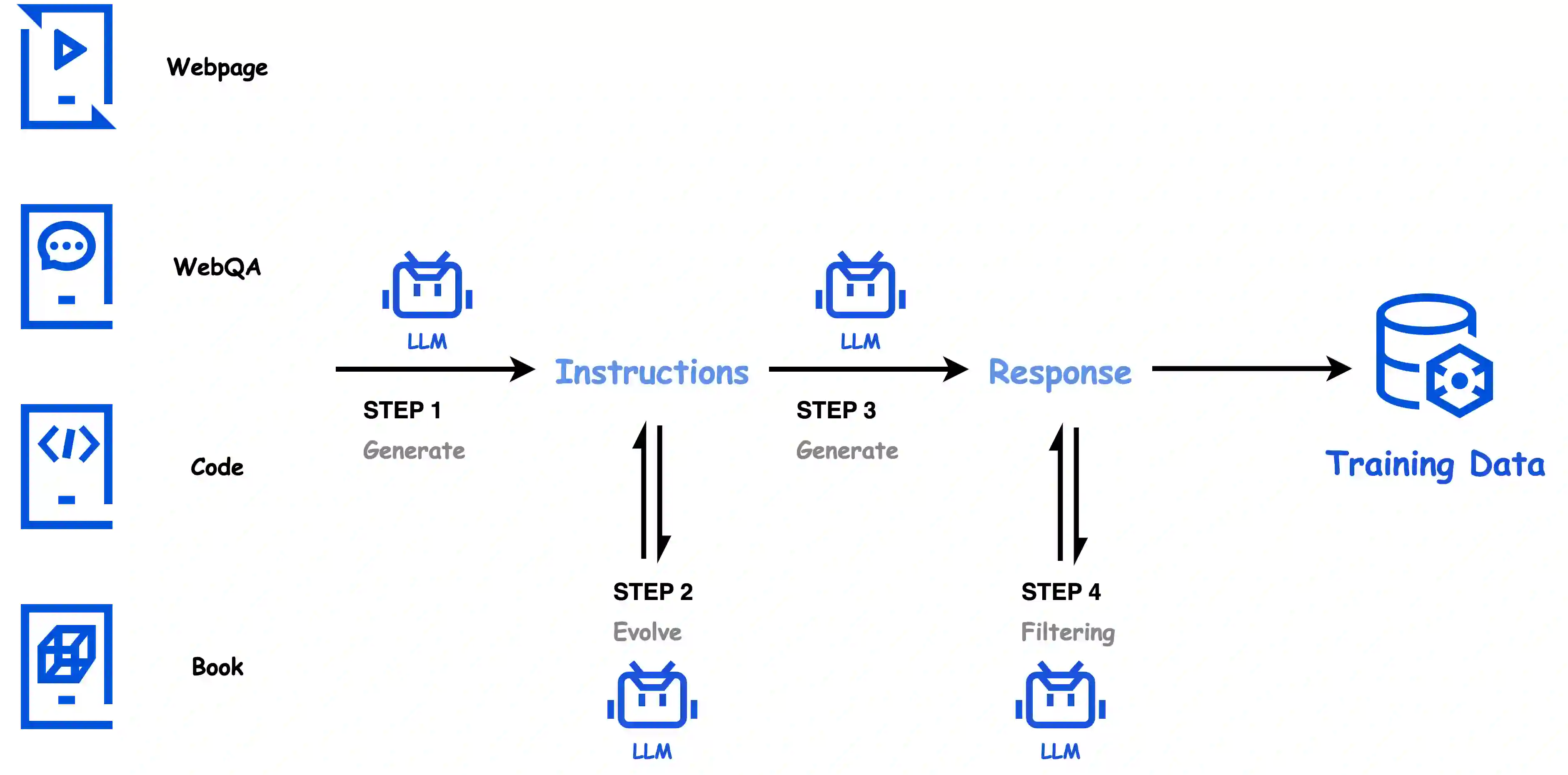
In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
翻译:本文介绍了Hunyuan-Large,这是目前最大的基于Transformer的开源专家混合模型,总参数量达3890亿,激活参数量为520亿,可处理长达256K的上下文。我们对Hunyuan-Large在多项基准测试中的卓越表现进行了全面评估,包括语言理解与生成、逻辑推理、数学问题求解、代码生成、长上下文处理及综合任务。结果显示,其性能超越LLama3.1-70B,并与参数量显著更大的LLama3.1-405B模型表现相当。Hunyuan-Large的核心实践包括:规模较以往文献提升数个数量级的大规模合成数据、混合专家路由策略、键值缓存压缩技术以及专家专用学习率策略。此外,我们还研究了专家混合模型的缩放规律与学习率调度机制,为未来模型的开发与优化提供了宝贵的见解与指导。Hunyuan-Large的代码与模型检查点已开源,以促进未来的创新与应用。代码地址:https://github.com/Tencent/Hunyuan-Large 模型地址:https://huggingface.co/tencent/Tencent-Hunyuan-Large