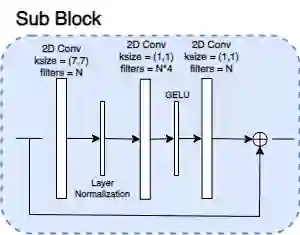
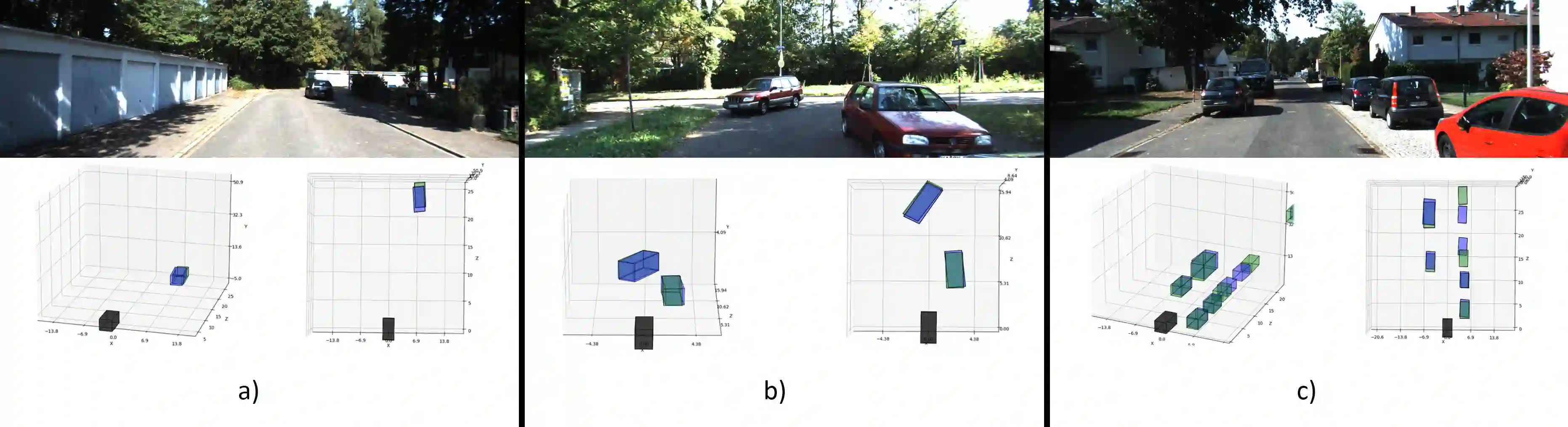
Autonomous driving perception tasks rely heavily on cameras as the primary sensor for Object Detection, Semantic Segmentation, Instance Segmentation, and Object Tracking. However, RGB images captured by cameras lack depth information, which poses a significant challenge in 3D detection tasks. To supplement this missing data, mapping sensors such as LIDAR and RADAR are used for accurate 3D Object Detection. Despite their significant accuracy, the multi-sensor models are expensive and require a high computational demand. In contrast, Monocular 3D Object Detection models are becoming increasingly popular, offering a faster, cheaper, and easier-to-implement solution for 3D detections. This paper introduces a different Multi-Tasking Learning approach called MonoNext that utilizes a spatial grid to map objects in the scene. MonoNext employs a straightforward approach based on the ConvNext network and requires only 3D bounding box annotated data. In our experiments with the KITTI dataset, MonoNext achieved high precision and competitive performance comparable with state-of-the-art approaches. Furthermore, by adding more training data, MonoNext surpassed itself and achieved higher accuracies.
翻译:自动驾驶感知任务高度依赖摄像头作为目标检测、语义分割、实例分割及目标追踪的主要传感器。然而摄像头采集的RGB图像缺乏深度信息,这给三维检测任务带来了巨大挑战。为弥补这一数据缺失,通常采用激光雷达(LiDAR)和雷达(RADAR)等测绘传感器实现精确的三维目标检测。尽管多传感器模型精度显著,但其成本高昂且计算需求巨大。相比之下,单目三维目标检测模型正日益普及,为三维检测提供了更快、更廉价且更易实现的解决方案。本文提出一种名为MonoNext的多任务学习方法,该方法利用空间网格对场景中的物体进行映射。MonoNext采用基于ConvNext网络的简洁方案,仅需三维边界框标注数据即可运行。在KITTI数据集上的实验表明,MonoNext实现了与现有最优方法相媲美的高精度和竞争性表现。此外,通过增加训练数据,MonoNext进一步超越自身,取得了更高的精度。