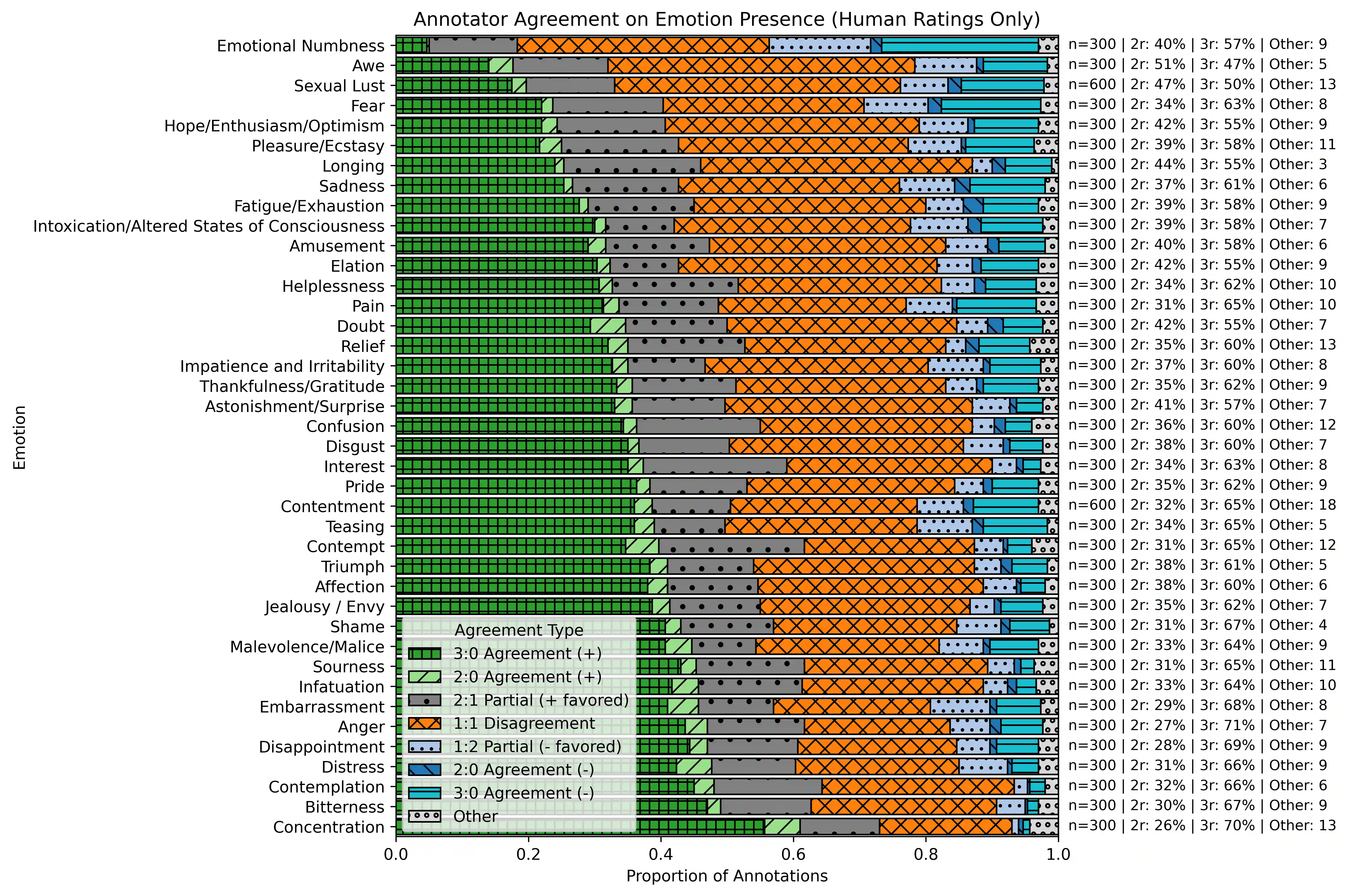
Speech emotion recognition (SER) systems are constrained by existing datasets that typically cover only 6-10 basic emotions, lack scale and diversity, and face ethical challenges when collecting sensitive emotional states. We introduce EMONET-VOICE, a comprehensive resource addressing these limitations through two components: (1) EmoNet-Voice Big, a 5,000-hour multilingual pre-training dataset spanning 40 fine-grained emotion categories across 11 voices and 4 languages, and (2) EmoNet-Voice Bench, a rigorously validated benchmark of 4,7k samples with unanimous expert consensus on emotion presence and intensity levels. Using state-of-the-art synthetic voice generation, our privacy-preserving approach enables ethical inclusion of sensitive emotions (e.g., pain, shame) while maintaining controlled experimental conditions. Each sample underwent validation by three psychology experts. We demonstrate that our Empathic Insight models trained on our synthetic data achieve strong real-world dataset generalization, as tested on EmoDB and RAVDESS. Furthermore, our comprehensive evaluation reveals that while high-arousal emotions (e.g., anger: 95% accuracy) are readily detected, the benchmark successfully exposes the difficulty of distinguishing perceptually similar emotions (e.g., sadness vs. distress: 63% discrimination), providing quantifiable metrics for advancing nuanced emotion AI. EMONET-VOICE establishes a new paradigm for large-scale, ethically-sourced, fine-grained SER research.
翻译:语音情感识别系统受限于现有数据集,这些数据集通常仅覆盖6-10种基本情感,缺乏规模与多样性,且在收集敏感情感状态时面临伦理挑战。我们提出了EMONET-VOICE,这是一个通过两个组成部分解决上述局限性的综合性资源:(1) EmoNet-Voice Big,一个包含5,000小时的多语言预训练数据集,涵盖11种音色和4种语言下的40个细粒度情感类别;(2) EmoNet-Voice Bench,一个包含4.7千个样本、经过严格验证的基准数据集,其中每个样本的情感存在与强度级别均获得了专家的一致共识。利用最先进的合成语音生成技术,我们的隐私保护方法能够在保持受控实验条件的同时,合乎伦理地纳入敏感情感(如痛苦、羞耻)。每个样本均经过三位心理学专家的验证。我们证明,基于我们合成数据训练的Empathic Insight模型在EmoDB和RAVDESS数据集上测试时,展现出强大的真实世界数据集泛化能力。此外,我们的全面评估表明,虽然高唤醒度情感(如愤怒:95%准确率)易于检测,但该基准也成功揭示了区分感知上相似情感的困难(如悲伤与痛苦:63%的区分度),从而为推进细致入微的情感人工智能提供了可量化的指标。EMONET-VOICE为大规模、符合伦理来源、细粒度的语音情感识别研究确立了新范式。