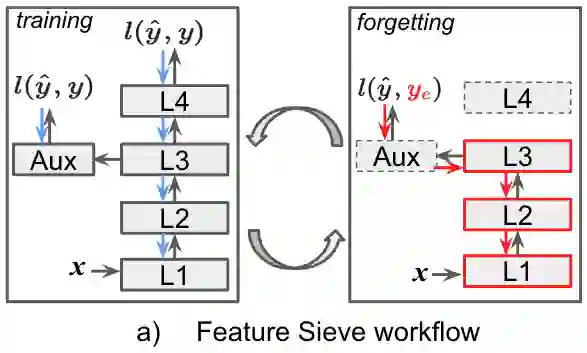
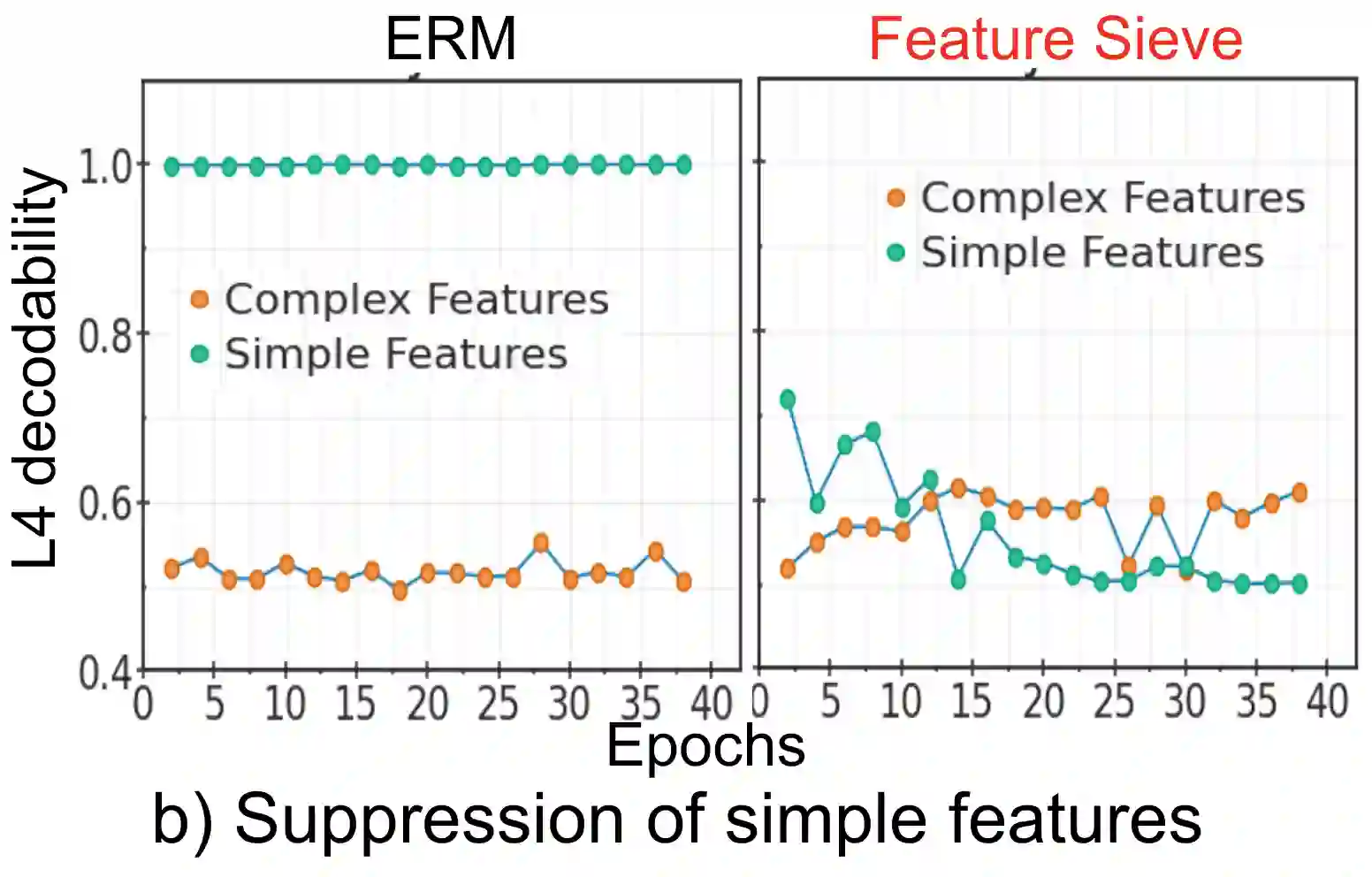
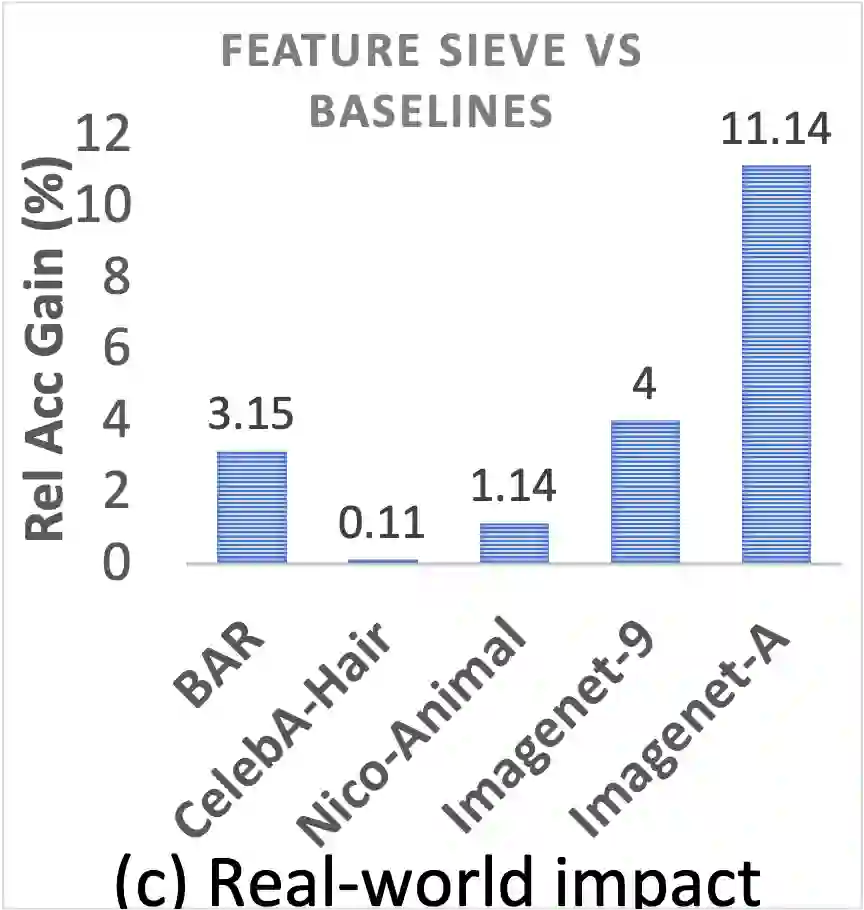
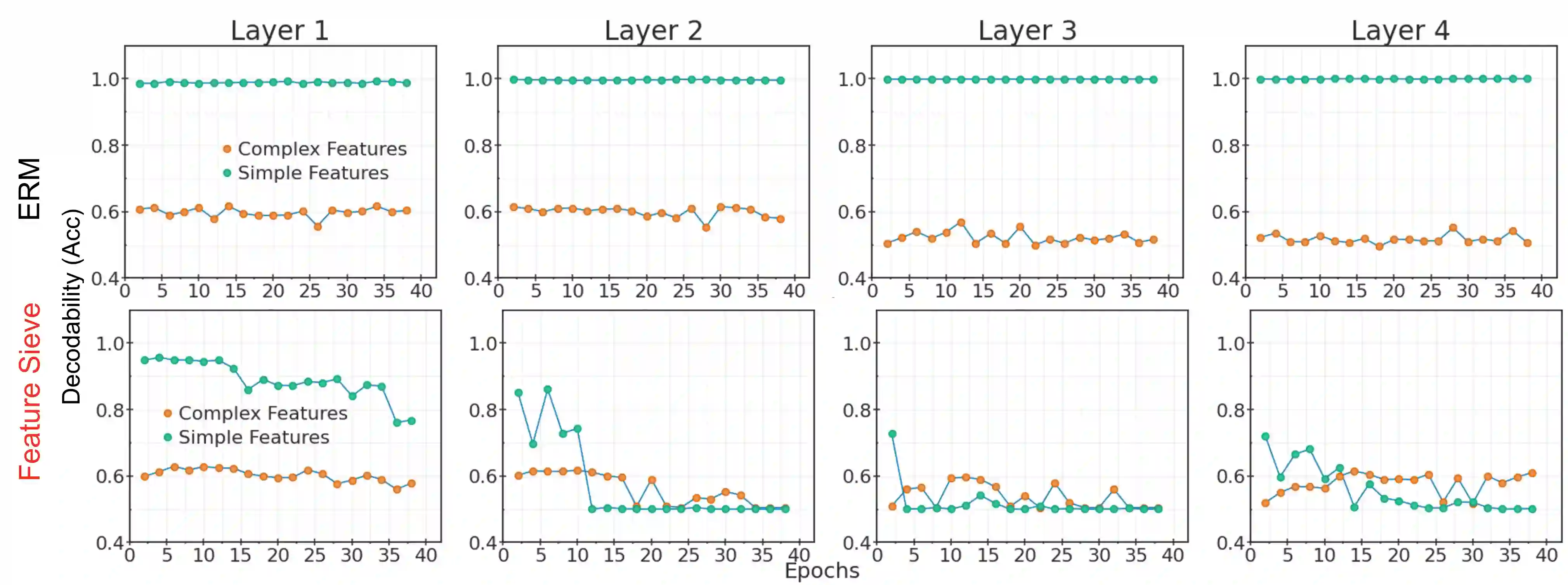
Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This is exacerbated in real-world applications by limited training data and spurious feature-label correlations, leading to biased, incorrect predictions. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we do not depend on prior knowledge of spurious attributes or features, and in fact outperform many baselines that explicitly incorporate such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction and representation learning for deep networks.
翻译:简单性偏差是深度网络的一个令人担忧的倾向,即过度依赖简单、弱预测性的特征,而排斥更强、更复杂的特征。在现实应用中,有限训练数据和虚假特征-标签关联会加剧这一问题,导致有偏且不准确的预测。我们提出了一种直接干预性方法来解决深度神经网络中的简单性偏差,称为"特征筛"。该方法旨在自动识别并抑制网络较低层中易于计算的虚假特征,从而使更高层级能够提取并利用更丰富、更有意义的表征。我们在受控数据集和真实世界图像上提供了这种相关特征差异性抑制与增强的具体证据,并在众多现实世界去偏基准测试中报告了显著改进(ImageNet-A上相对提升11.4%,BAR上提升3.2%等)。关键的是,我们无需依赖虚假属性或特征的先验知识,实际上还超越了多个显式整合此类信息的基线方法。我们相信,我们的特征筛工作为深度网络中的自动化对抗性特征提取与表征学习开辟了令人兴奋的新研究方向。