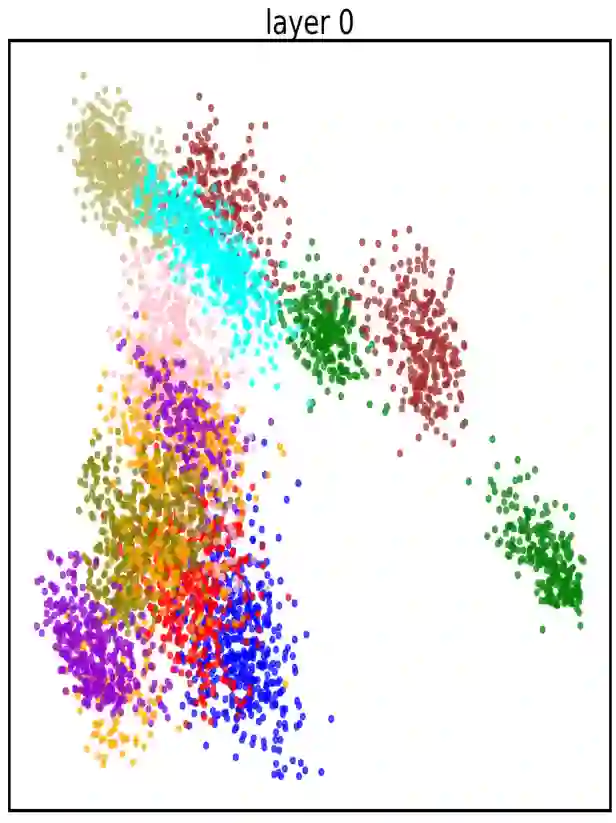
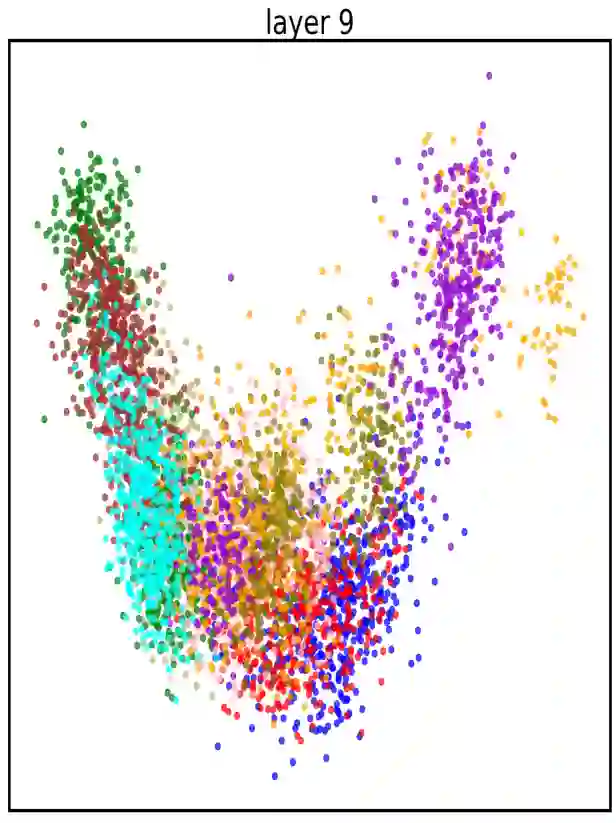
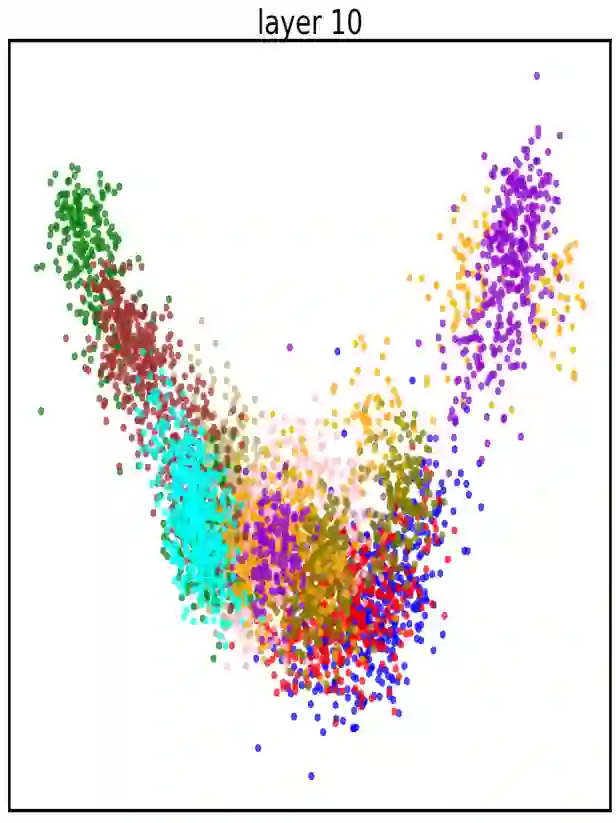
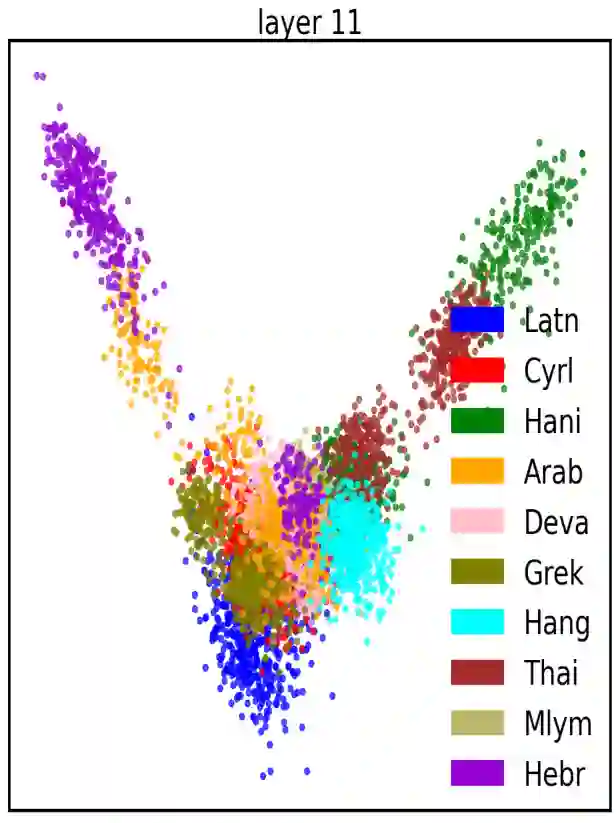
There are 293 scripts representing over 7,000 languages in the written form. Due to various reasons, many closely related languages use different scripts, which poses difficulty for multilingual pretrained language models (mPLMs) in learning crosslingual knowledge through lexical overlap. As a result, mPLMs present a script barrier: representations from different scripts are located in different subspaces, which is a strong indicator of why crosslingual transfer involving languages of different scripts shows sub-optimal performance. To address this problem, we propose a simple framework TransliCo that contains Transliteration Contrastive Modeling (TCM) to fine-tune an mPLM by contrasting sentences in its training data and their transliterations in a unified script (Latn, in our case), which ensures uniformity in the representation space for different scripts. Using Glot500-m, an mPLM pretrained on over 500 languages, as our source model, we find-tune it on a small portion (5\%) of its training data, and refer to the resulting model as Furina. We show that Furina not only better aligns representations from distinct scripts but also outperforms the original Glot500-m on various crosslingual transfer tasks. Additionally, we achieve consistent improvement in a case study on the Indic group where the languages are highly related but use different scripts. We make our code and models publicly available.
翻译:全球书写系统共有293种文字,覆盖超过7000种语言。由于多种原因,许多密切相关的语言使用不同的文字,这给多语言预训练语言模型(mPLMs)通过词汇重叠学习跨语言知识带来了困难。因此,mPLMs呈现出一种“文字壁垒”:不同文字的表示位于不同的子空间中,这充分解释了为何涉及不同文字的语言之间的跨语言迁移表现欠佳。为解决此问题,我们提出一个简洁的框架TransliCo,其中包含音译对比建模(TCM),通过对训练数据中的句子及其统一文字(本文采用拉丁字母)的音译进行对比,来微调mPLM,从而确保不同文字在表示空间中的一致性。我们以在500多种语言上预训练的mPLM Glot500-m作为源模型,仅用其训练数据的5%进行微调,并将所得模型命名为Furina。实验表明,Furina不仅能更好地对齐不同文字的表示,还在多种跨语言迁移任务中优于原始Glot500-m。此外,在以语言高度相关但使用不同文字的印度语支为案例的研究中,我们获得了一致的改进提升。我们已公开代码和模型。