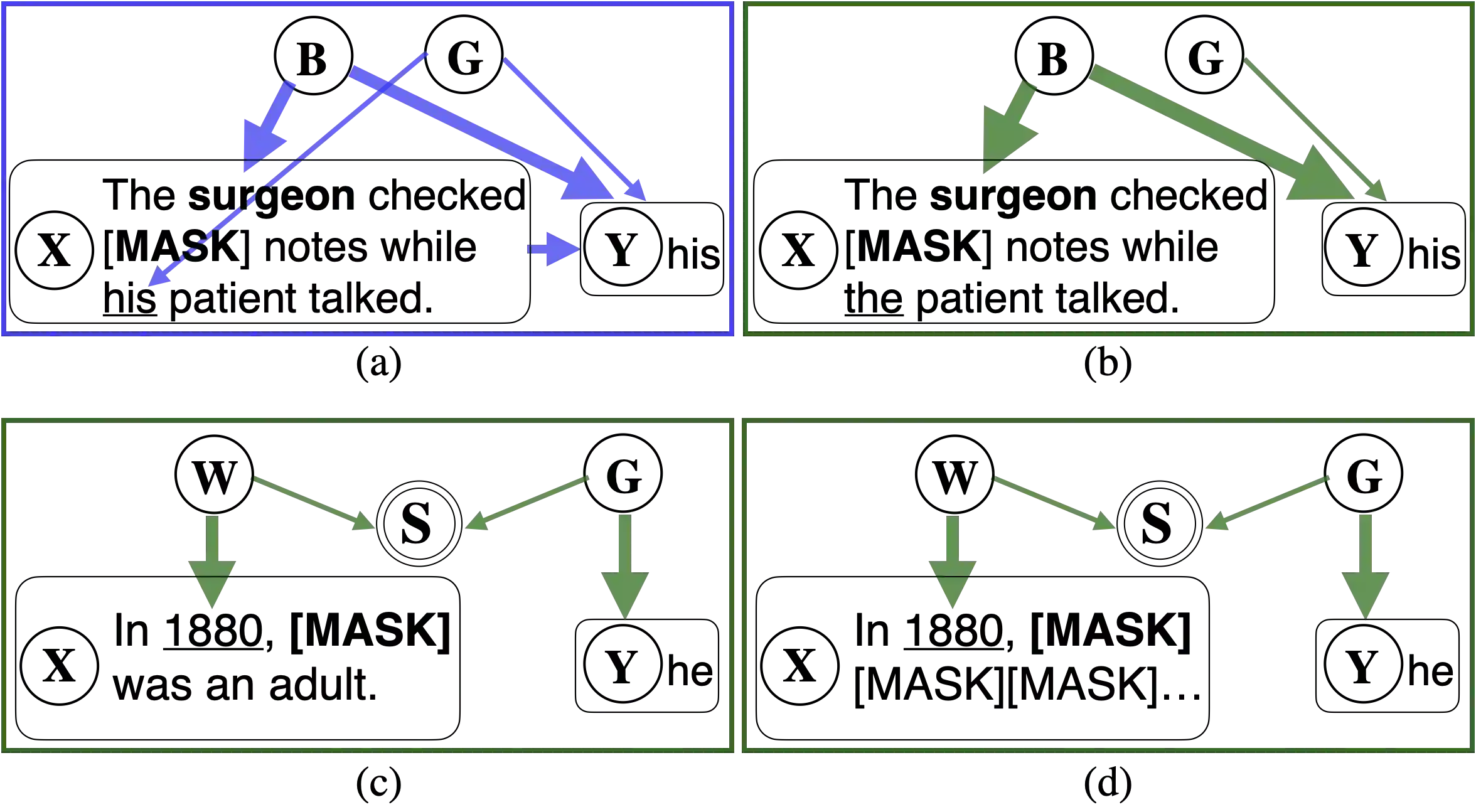
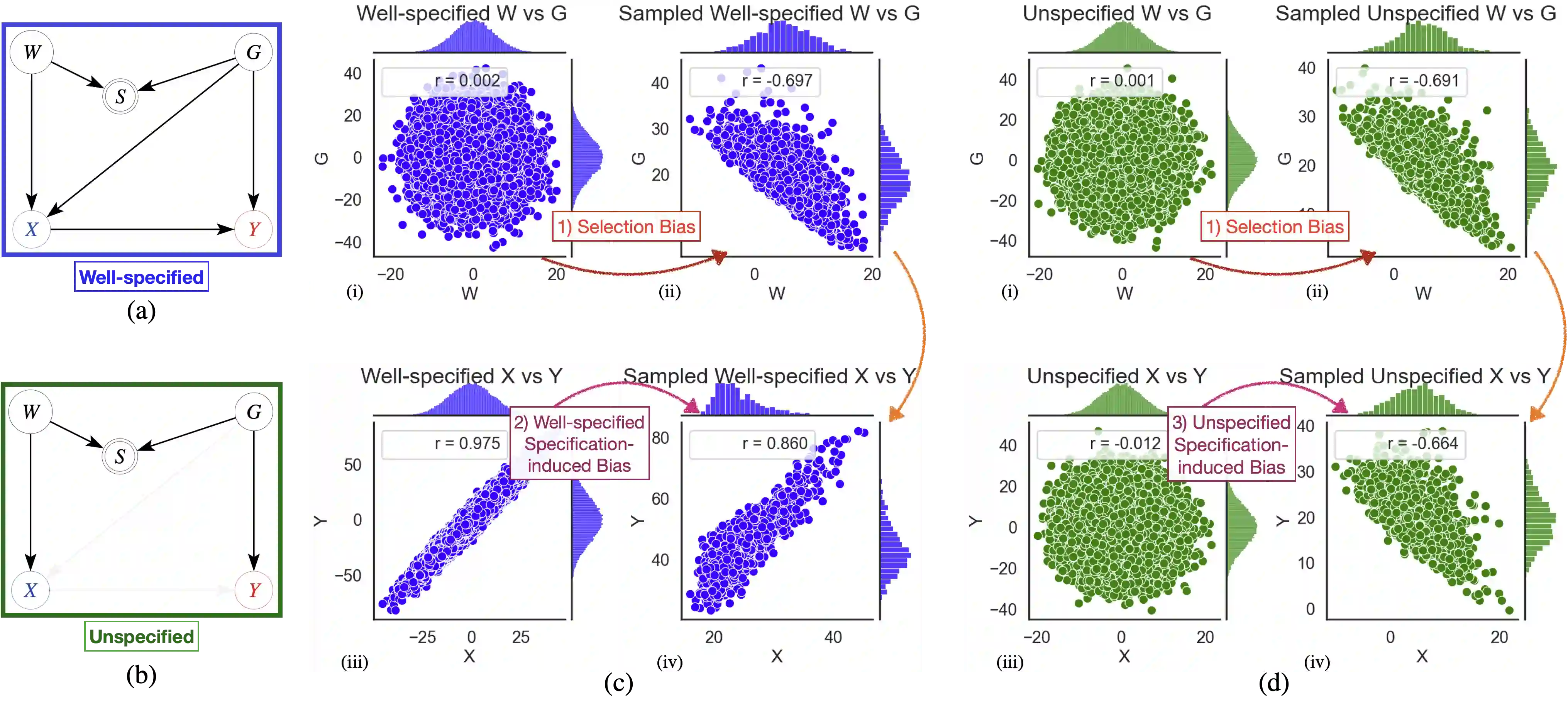
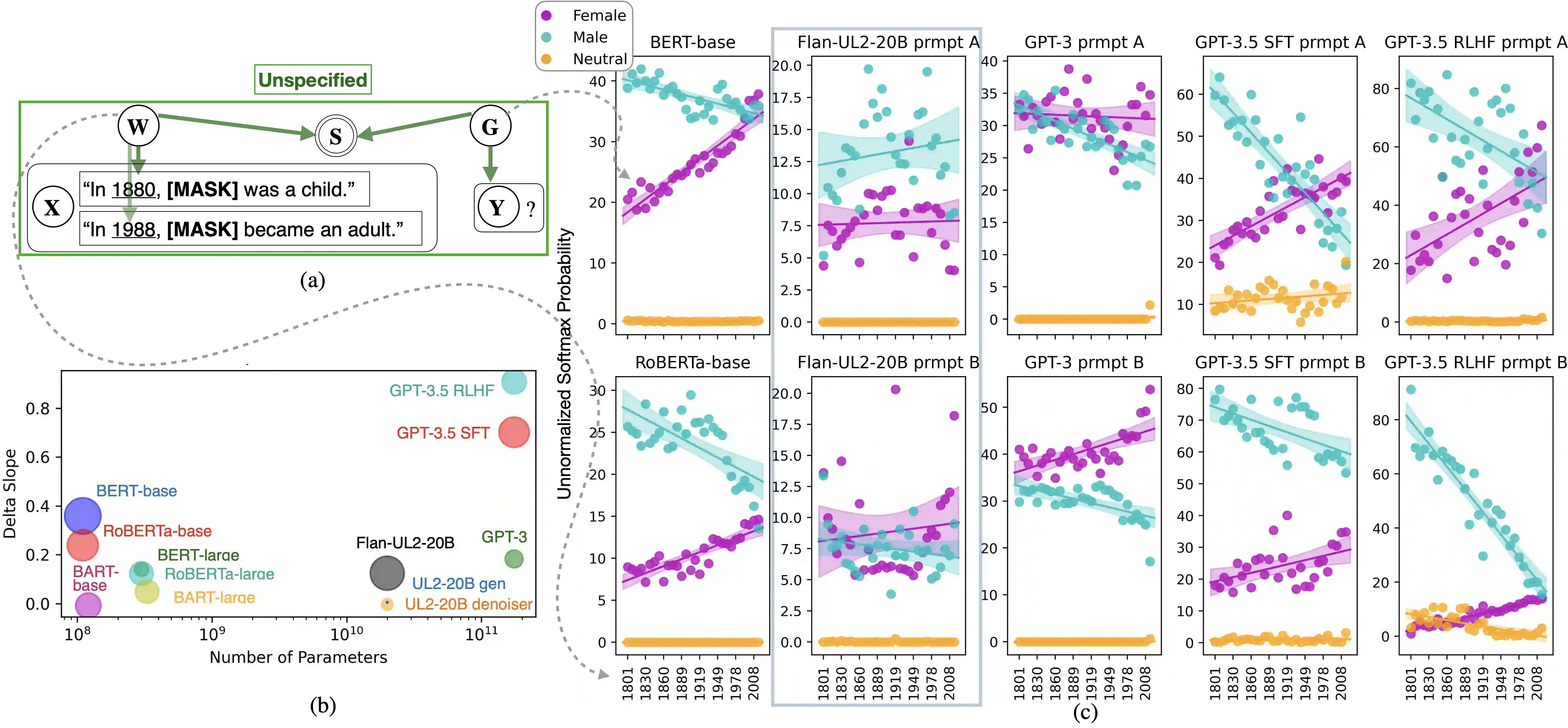
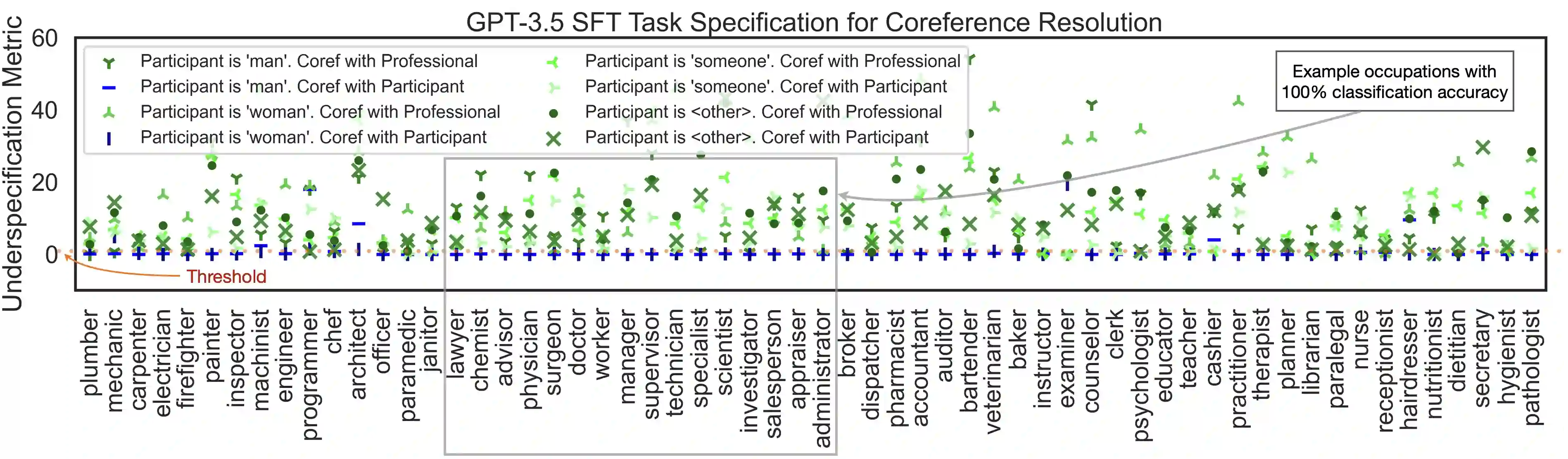
Modern language modeling tasks are often underspecified: for a given token prediction, many words may satisfy the user's intent of producing natural language at inference time, however only one word would minimize the task's loss function at training time. We provide a simple yet plausible causal mechanism describing the role underspecification plays in the generation of spurious correlations. Despite its simplicity, our causal model directly informs the development of two lightweight black-box evaluation methods, that we apply to gendered pronoun resolution tasks on a wide range of LLMs to 1) aid in the detection of inference-time task underspecification by exploiting 2) previously unreported gender vs. time and gender vs. location spurious correlations on LLMs with a range of A) sizes: from BERT-base to GPT 3.5, B) pre-training objectives: from masked & autoregressive language modeling to a mixture of these objectives, and C) training stages: from pre-training only to reinforcement learning from human feedback (RLHF). Code and open-source demos available at https: //github.com/2dot71mily/sib_paper.
翻译:现代语言建模任务通常存在欠规定性:对于给定的词元预测,在推理时生成自然语言时可能有多个词语满足用户意图,但在训练时只有单个词语能最小化任务的损失函数。我们提出一个简洁而具有合理性的因果机制,用以描述欠规定性在虚假相关性生成中的作用。尽管该因果模型简单,但它直接指导了两种轻量级黑盒评估方法的开发,我们将其应用于多种大语言模型的有性别代词消解任务,以1) 通过利用2) 先前未报道的关于性别与时间、性别与位置的虚假相关性(涉及模型的不同A) 规模:从BERT-base到GPT 3.5;B) 预训练目标:从掩码语言建模与自回归语言建模到混合目标;C) 训练阶段:从仅预训练到基于人类反馈的强化学习),辅助检测推理时的任务欠规定性。代码和开源演示见:https://github.com/2dot71mily/sib_paper。