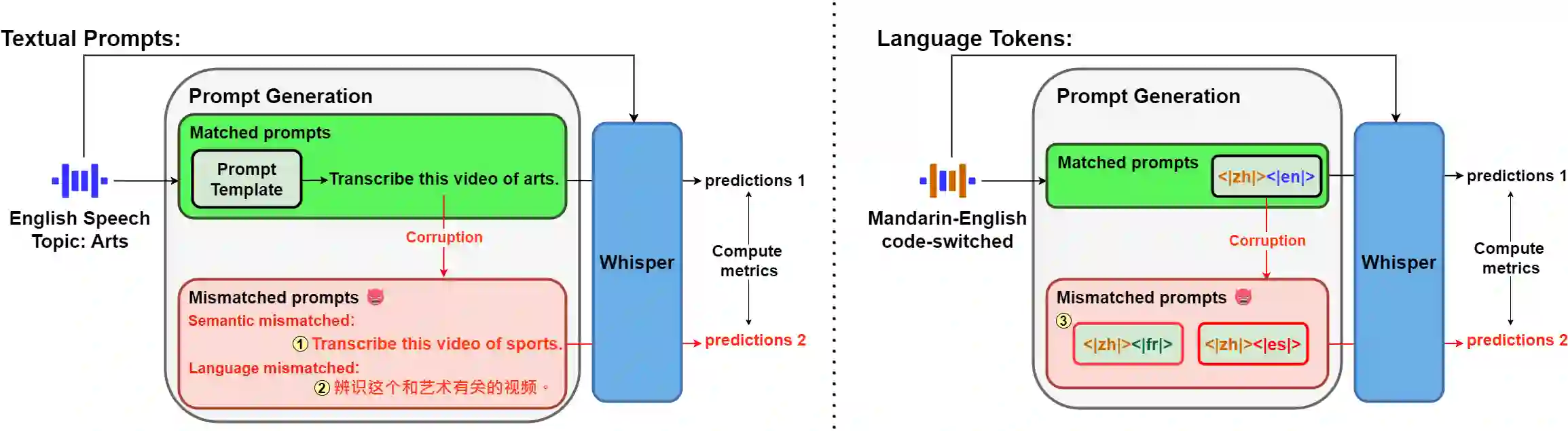
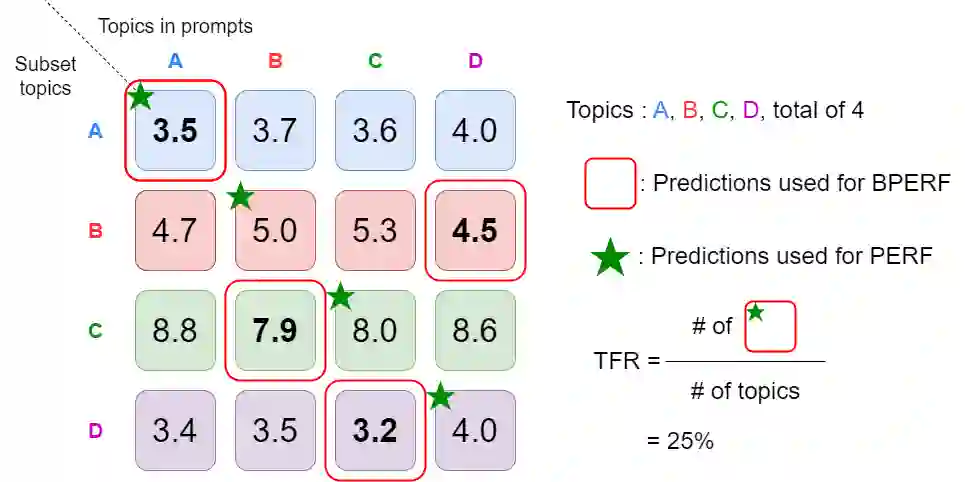
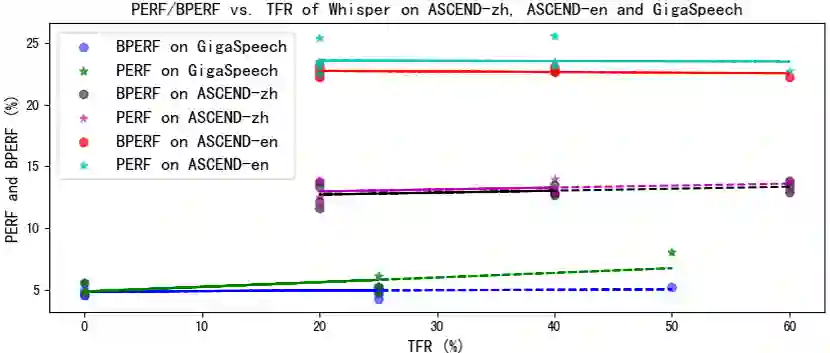
This research explores how the information of prompts interacts with the high-performing speech recognition model, Whisper. We compare its performances when prompted by prompts with correct information and those corrupted with incorrect information. Our results unexpectedly show that Whisper may not understand the textual prompts in a human-expected way. Additionally, we find that performance improvement is not guaranteed even with stronger adherence to the topic information in textual prompts. It is also noted that English prompts generally outperform Mandarin ones on datasets of both languages, likely due to differences in training data distributions for these languages despite the mismatch with pre-training scenarios. Conversely, we discover that Whisper exhibits awareness of misleading information in language tokens by ignoring incorrect language tokens and focusing on the correct ones. In sum, We raise insightful questions about Whisper's prompt understanding and reveal its counter-intuitive behaviors. We encourage further studies.
翻译:本研究探讨了提示信息如何与高性能语音识别模型Whisper相互作用。我们比较了模型在接收正确信息提示与接收被错误信息破坏的提示时的表现。结果意外地表明,Whisper可能并未以人类预期的方式理解文本提示。此外,我们发现即使文本提示更严格地遵循主题信息,性能提升也并非必然。研究还注意到,在英语和普通话数据集上,英语提示通常表现优于普通话提示,这可能是由于两种语言训练数据分布的差异所致,尽管这与预训练场景不匹配。相反,我们发现Whisper表现出对语言标记中误导信息的觉察能力,能够忽略错误的语言标记并专注于正确的标记。总之,我们对Whisper的提示理解能力提出了深刻质疑,并揭示了其反直觉的行为特性。我们鼓励进一步的研究。