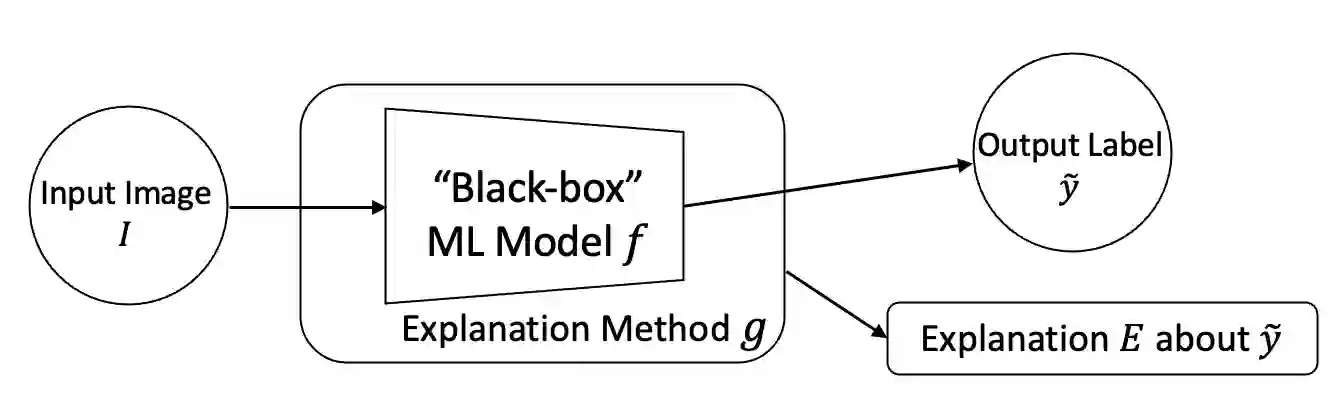
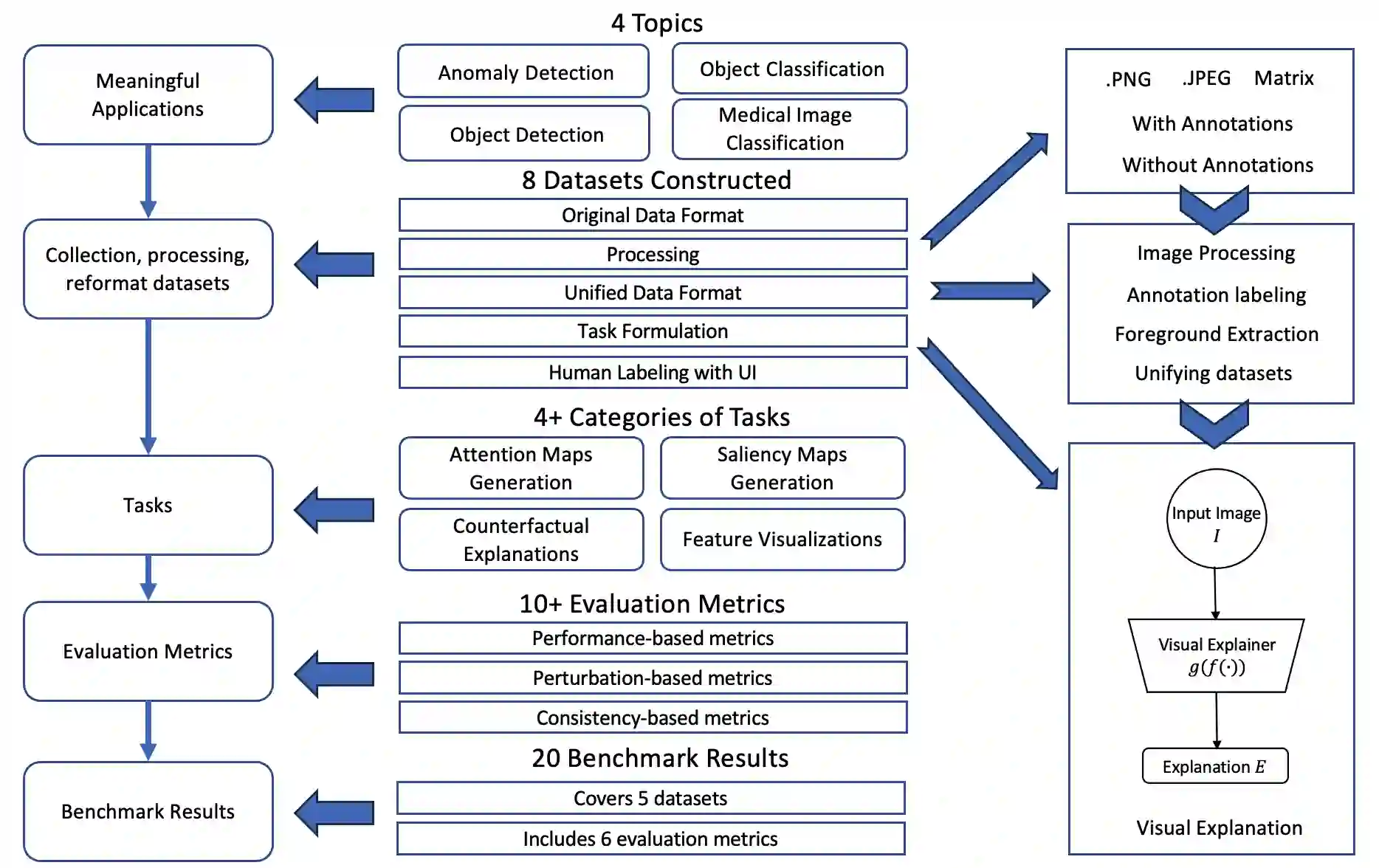
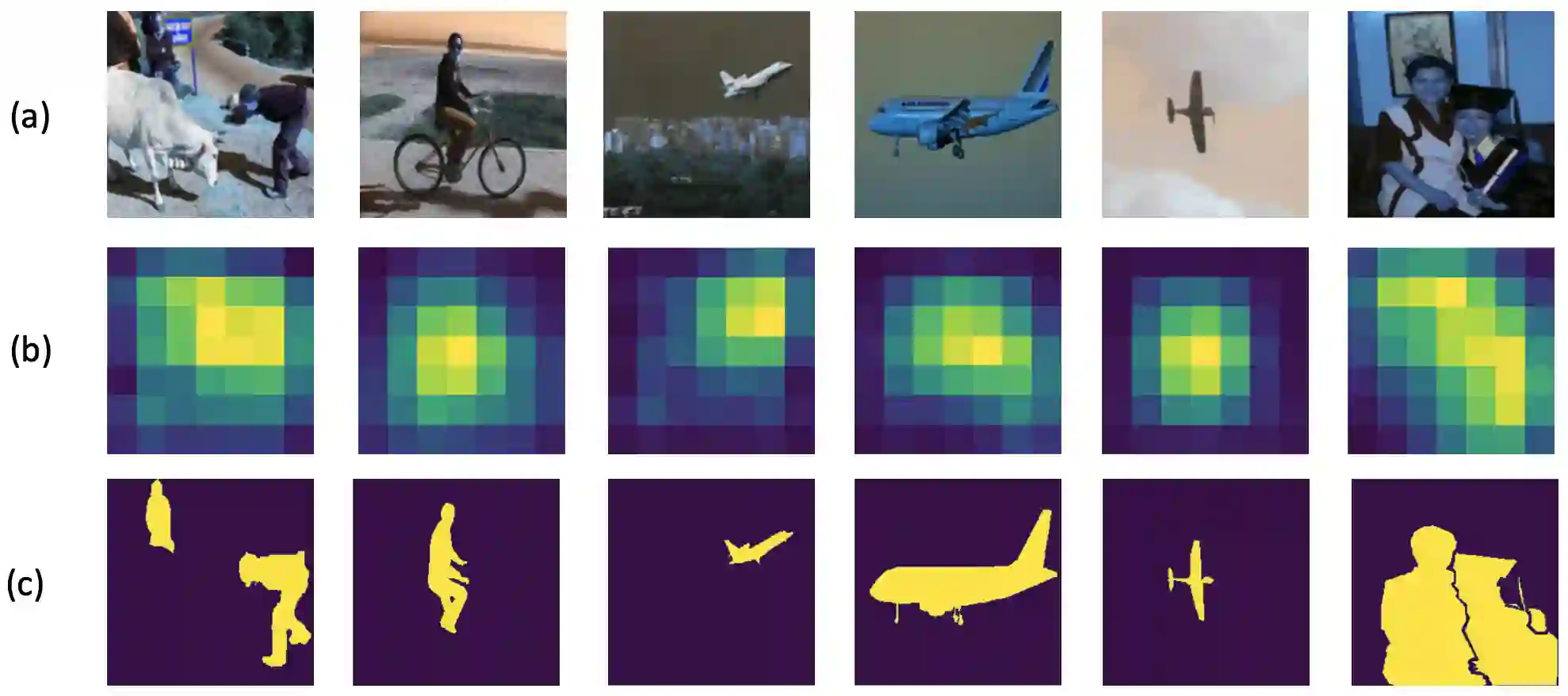
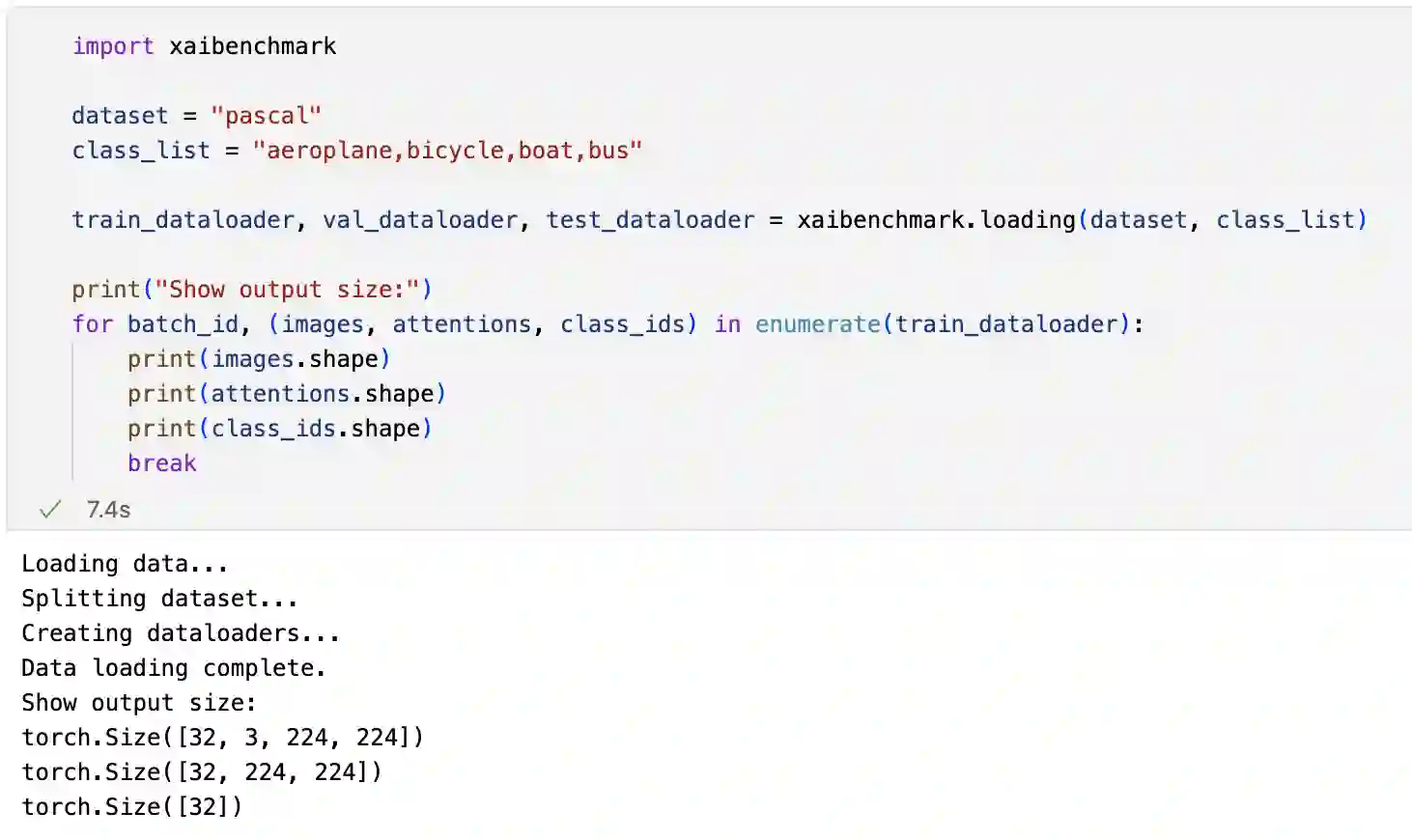
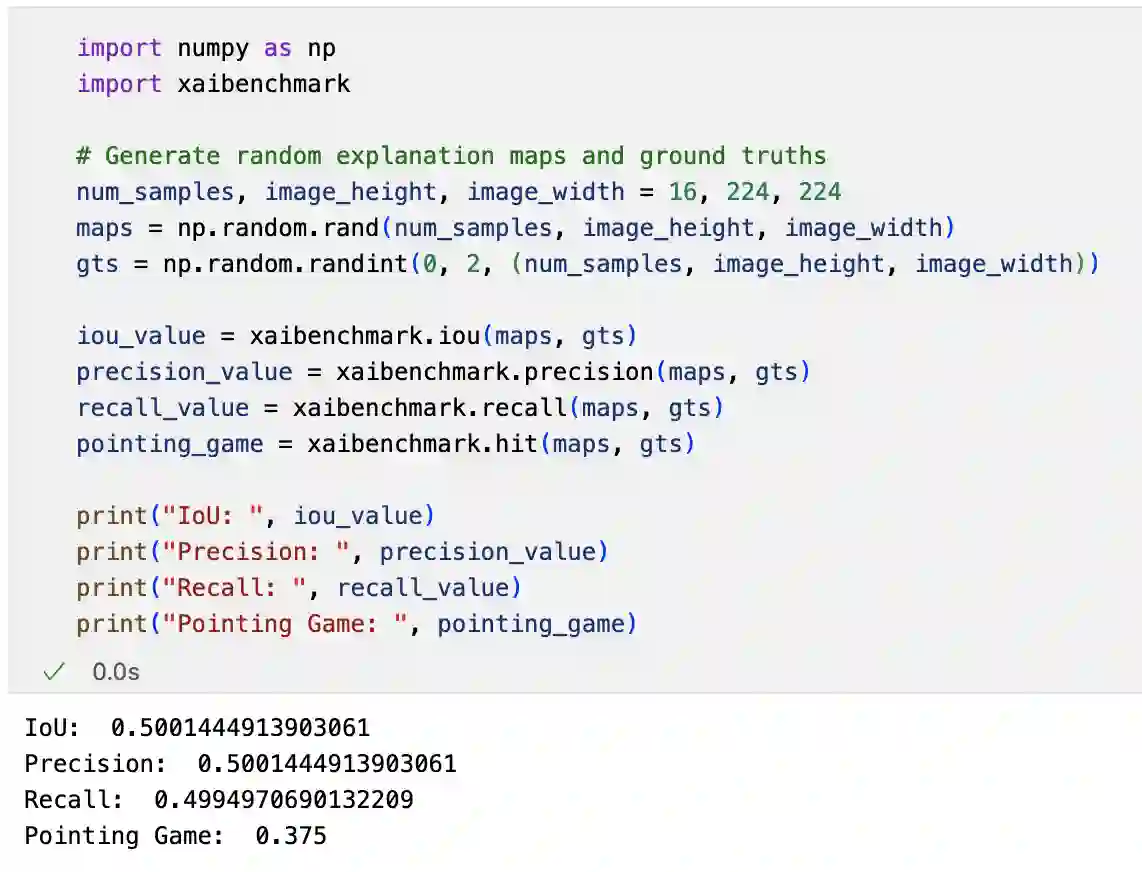
The rise of deep learning algorithms has led to significant advancements in computer vision tasks, but their "black box" nature has raised concerns regarding interpretability. Explainable AI (XAI) has emerged as a critical area of research aiming to open this "black box", and shed light on the decision-making process of AI models. Visual explanations, as a subset of Explainable Artificial Intelligence (XAI), provide intuitive insights into the decision-making processes of AI models handling visual data by highlighting influential areas in an input image. Despite extensive research conducted on visual explanations, most evaluations are model-centered since the availability of corresponding real-world datasets with ground truth explanations is scarce in the context of image data. To bridge this gap, we introduce an XAI Benchmark comprising a dataset collection from diverse topics that provide both class labels and corresponding explanation annotations for images. We have processed data from diverse domains to align with our unified visual explanation framework. We introduce a comprehensive Visual Explanation pipeline, which integrates data loading, preprocessing, experimental setup, and model evaluation processes. This structure enables researchers to conduct fair comparisons of various visual explanation techniques. In addition, we provide a comprehensive review of over 10 evaluation methods for visual explanation to assist researchers in effectively utilizing our dataset collection. To further assess the performance of existing visual explanation methods, we conduct experiments on selected datasets using various model-centered and ground truth-centered evaluation metrics. We envision this benchmark could facilitate the advancement of visual explanation models. The XAI dataset collection and easy-to-use code for evaluation are publicly accessible at https://xaidataset.github.io.
翻译:深度学习算法的兴起显著推动了计算机视觉任务的发展,但其"黑箱"特性引发了关于可解释性的担忧。可解释人工智能(XAI)应运而生,成为旨在打开这一"黑箱"、揭示AI模型决策过程的关键研究领域。视觉解释作为可解释人工智能的一个分支,通过凸显输入图像中的关键区域,为处理视觉数据的AI模型决策过程提供了直观洞见。尽管视觉解释已开展大量研究,但由于在图像数据领域缺乏兼具真实标注和解释标注的对应数据集,多数评估仍以模型为中心。为填补这一空白,我们引入了一个XAI基准测试,包含来自不同主题的数据集集合,这些数据集同时提供了图像的类别标签和对应的解释标注。我们处理了来自多个领域的数据,使其与我们的统一视觉解释框架保持一致。我们提出了一个完整的视觉解释流程,整合了数据加载、预处理、实验设置和模型评估等环节。该框架使研究者能够公平比较各类视觉解释技术。此外,我们综述了超过10种视觉解释评估方法,以帮助研究者有效利用我们的数据集集合。为进一步评估现有视觉解释方法的性能,我们基于选定的数据集,采用多种以模型为中心和以真实标注为中心的评估指标进行实验。我们期望该基准测试能够促进视觉解释模型的发展。XAI数据集集合及易于使用的评估代码已在https://xaidataset.github.io公开获取。