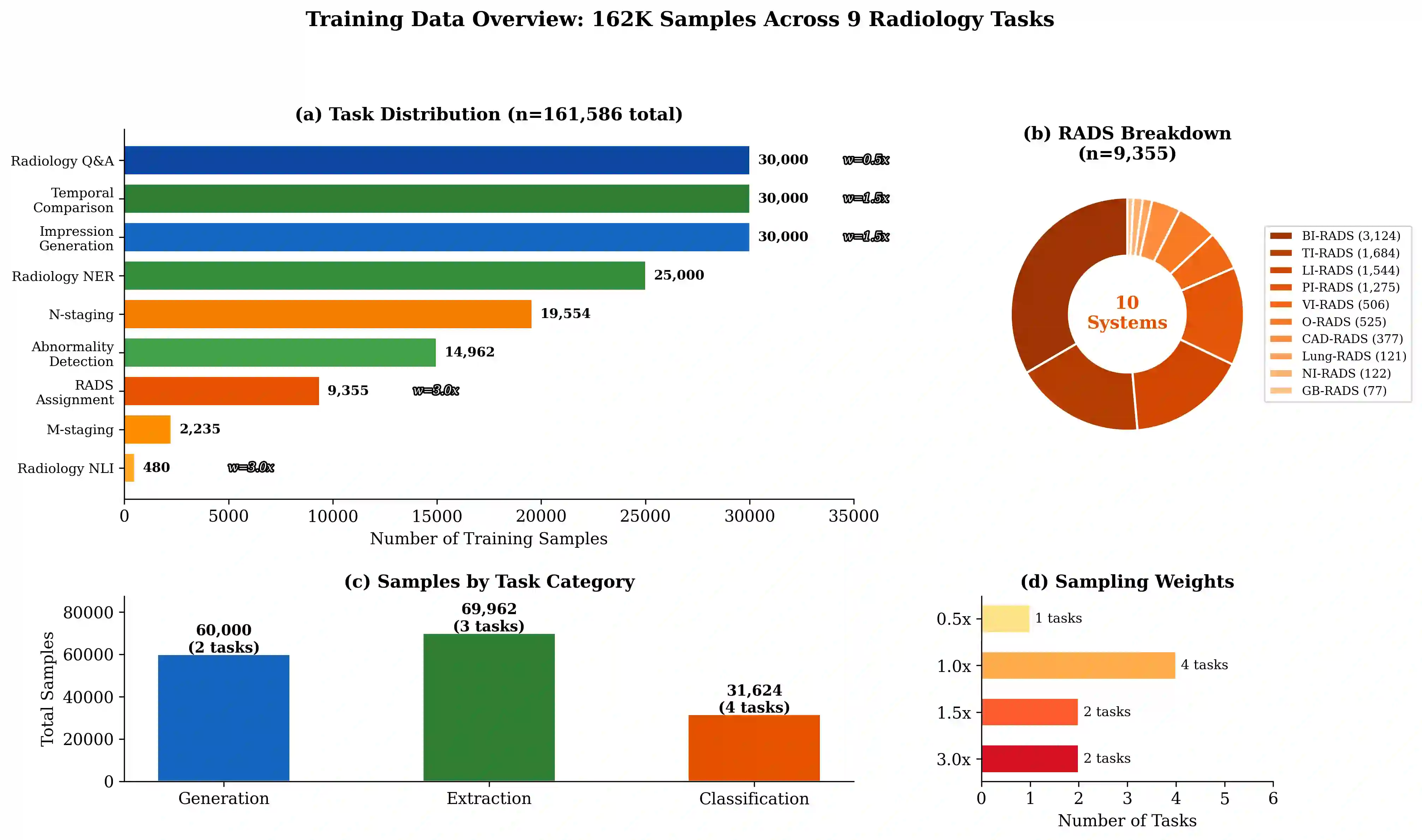
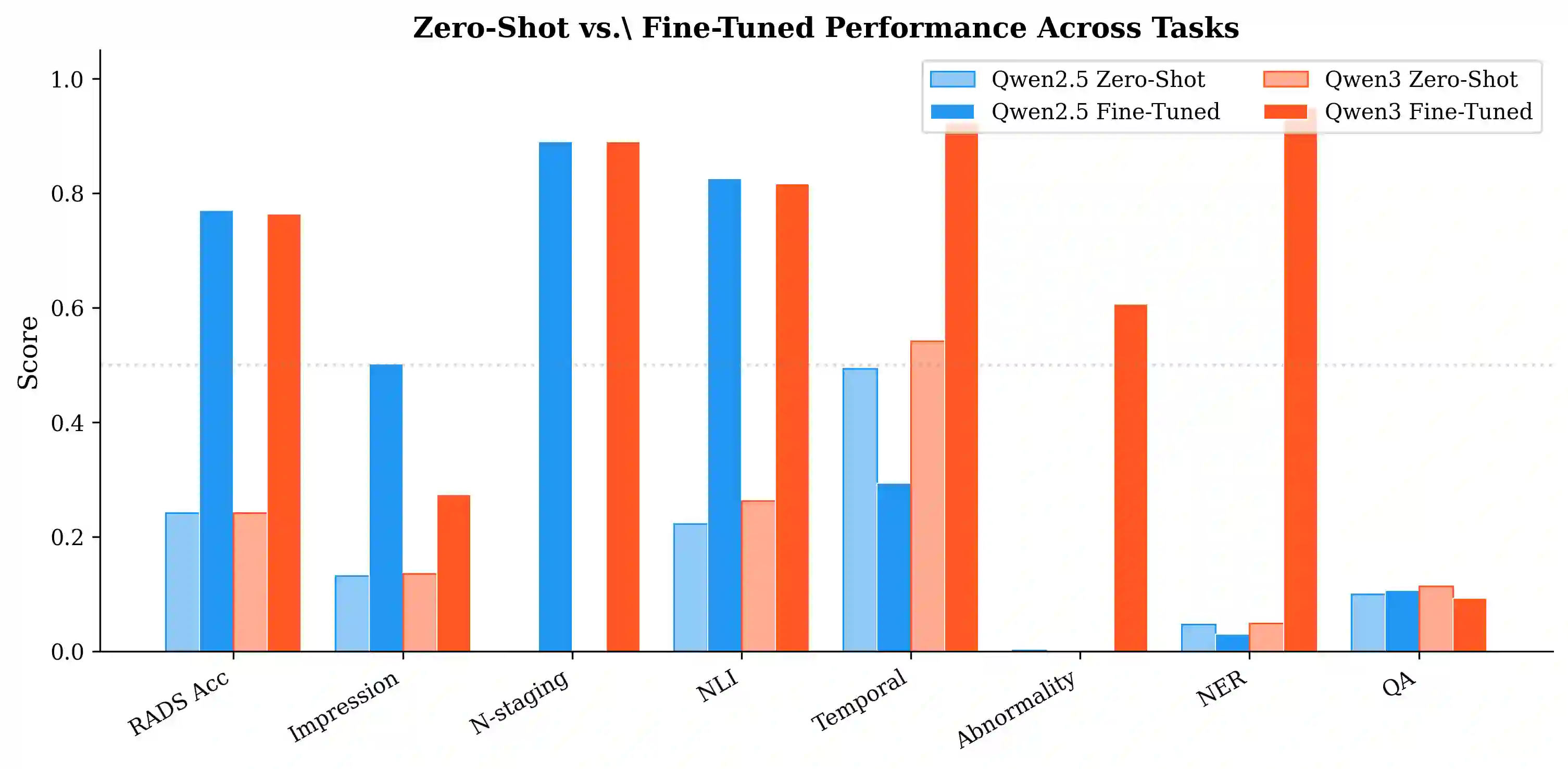
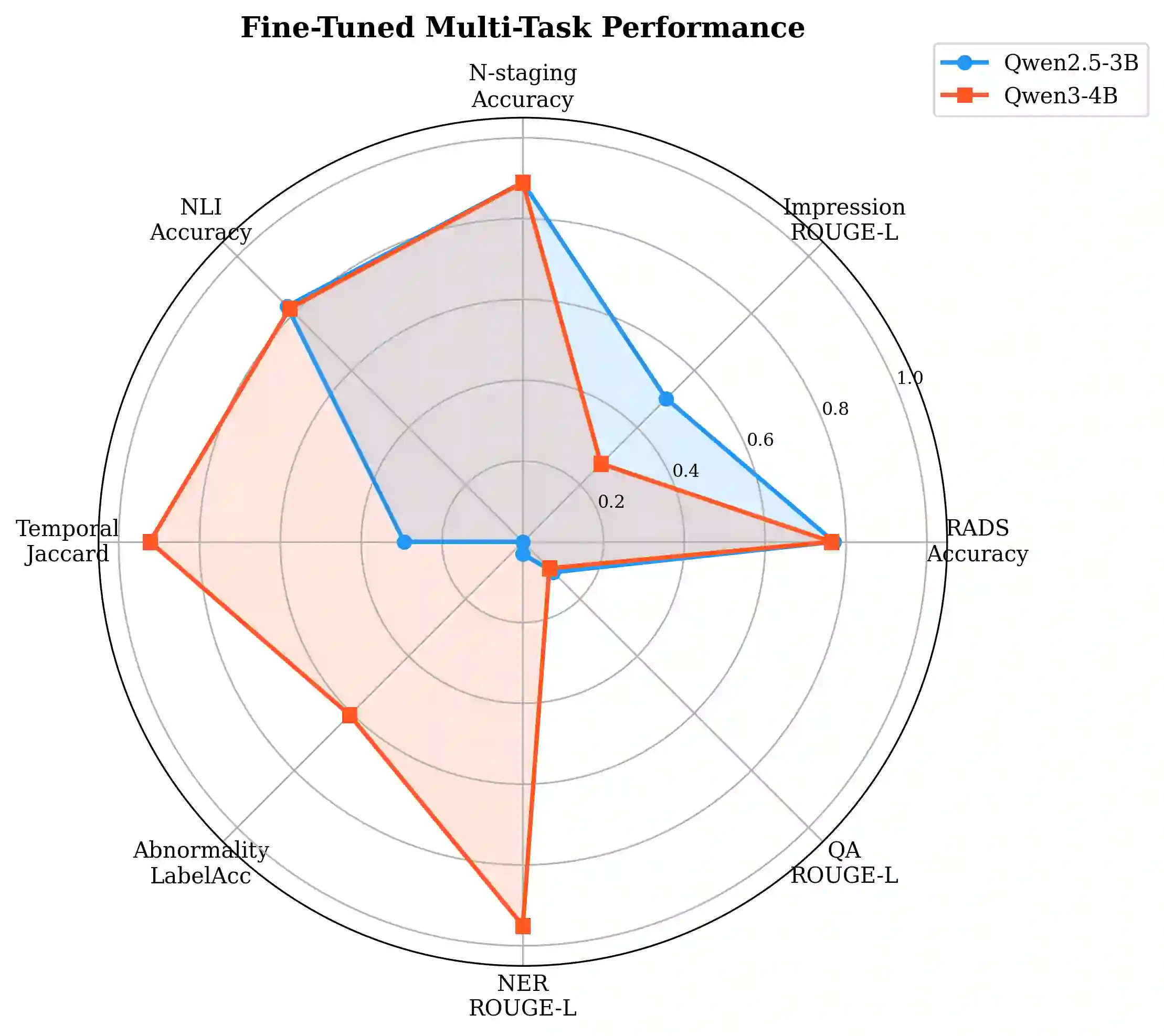
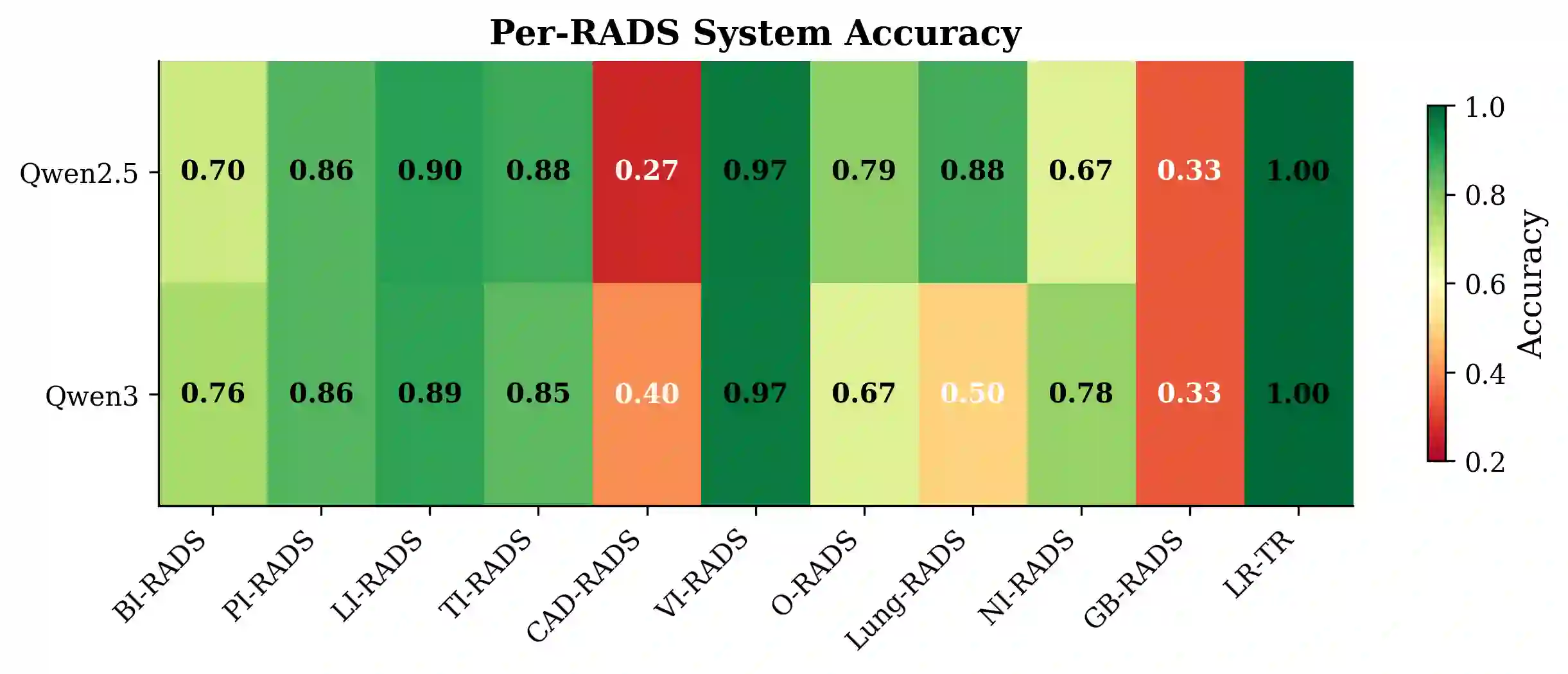
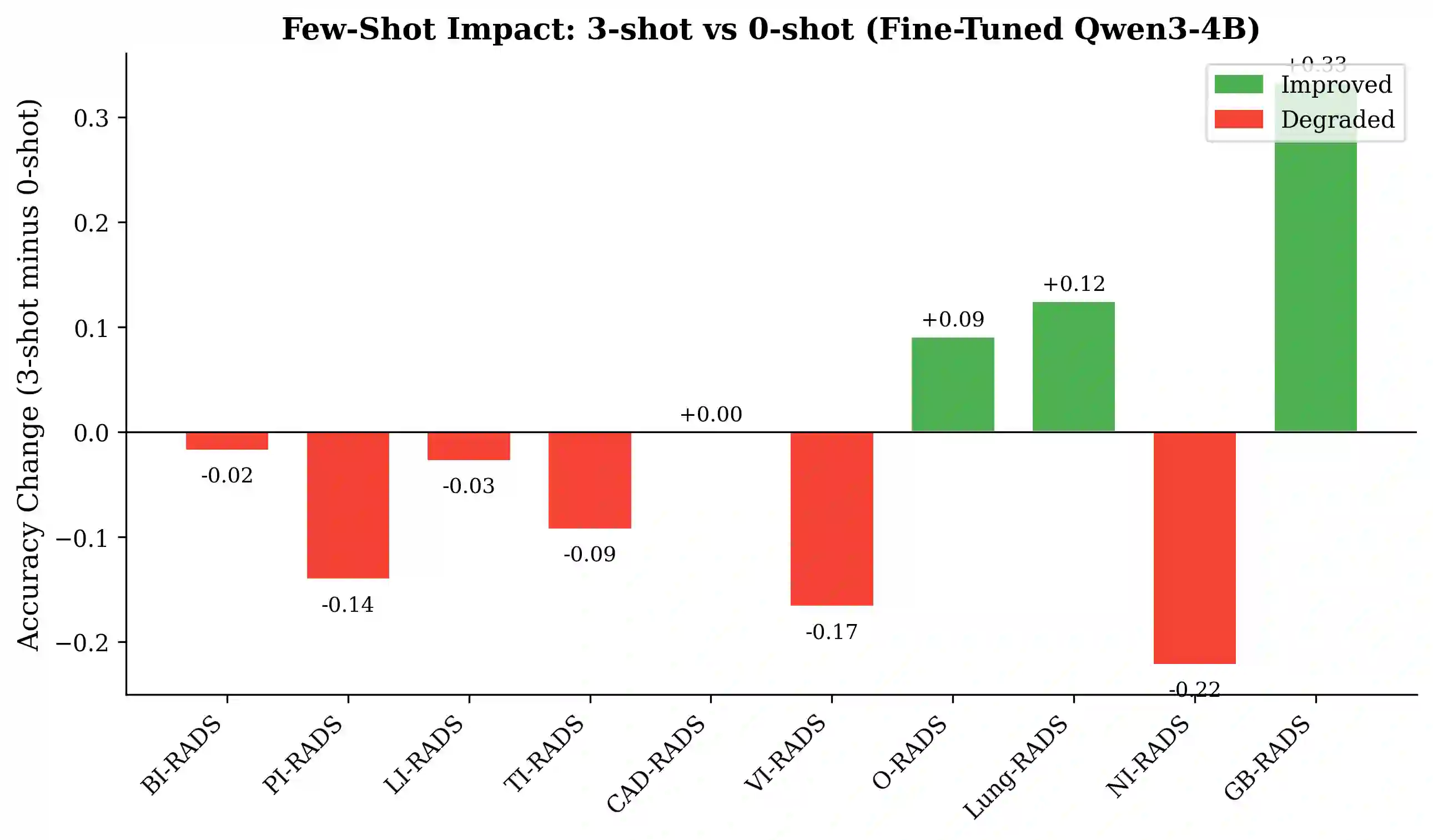
Large language models (LLMs) show promise in radiology but their deployment is limited by computational requirements that preclude use in resource-constrained clinical environments. We investigate whether small language models (SLMs) of 3-4 billion parameters can achieve strong multi-task radiology performance through LoRA fine-tuning, enabling deployment on consumer-grade CPUs. We train Qwen2.5-3B-Instruct and Qwen3-4B on 162K samples spanning 9 radiology tasks - RADS classification across 10 systems, impression generation, temporal comparison, radiology NLI, NER, abnormality detection, N/M staging, and radiology Q&A - compiled from 12 public datasets. Both models are evaluated on up to 500 held-out test samples per task with standardized metrics. Our key findings are: (1) LoRA fine-tuning dramatically improves performance over zero-shot baselines (RADS accuracy +53%, NLI +60%, N-staging +89%); (2) the two models exhibit complementary strengths - Qwen2.5 excels at structured generation tasks while Qwen3 dominates extractive tasks; (3) a task-outed oracle ensemble combining both models achieves the best performance across all tasks; (4) few-shot prompting with fine-tuned models hurts performance, demonstrating that LoRA adaptation is more effective than in-context learning for specialized domains; and (5) models can be quantized to GGUF format (~1.8-2.4GB) for CPU deployment at 4-8 tokens/second on consumer hardware. Our work demonstrates that small, efficiently fine-tuned models - which we collectively call RadLite - can serve as practical multi-task radiology AI assistants deployable entirely on consumer hardware without GPU requirements. Code and models are available at https://github.com/RadioX-Labs/RadLite
翻译:大型语言模型(LLMs)在放射学领域展现出潜力,但其计算需求限制了资源受限临床环境中的部署。本研究探究参数量为30-40亿的小语言模型(SLMs)能否通过LoRA微调实现强大的多任务放射学性能,从而支持在消费级CPU上部署。我们在涵盖9项放射学任务的162K样本上训练了Qwen2.5-3B-Instruct与Qwen3-4B模型——包括10个系统的RADS分类、印象生成、时序比较、放射学自然语言推理(NLI)、命名实体识别(NER)、异常检测、N/M分期及放射学问答——这些数据整合自12个公开数据集。两类模型均通过标准化指标在每项任务多达500个保留测试样本上评估。关键发现如下:(1)相较于零样本基线,LoRA微调显著提升性能(RADS准确率+53%,NLI+60%,N分期+89%);(2)两类模型呈现互补优势:Qwen2.5擅长结构化生成任务,而Qwen3主导抽取式任务;(3)结合两类模型的任务级专家集成在所有任务中取得最优性能;(4)对微调模型使用少样本提示会损害性能,表明LoRA适配在专业领域比上下文学习更有效;(5)模型可量化至GGUF格式(约1.8-2.4GB),在消费级硬件上以4-8 token/秒的速率实现CPU部署。本研究表明,经过高效微调的小型模型(统称为RadLite)可作为实用型多任务放射学AI助手,完全部署于无需GPU的消费级硬件。代码与模型已开源至https://github.com/RadioX-Labs/RadLite