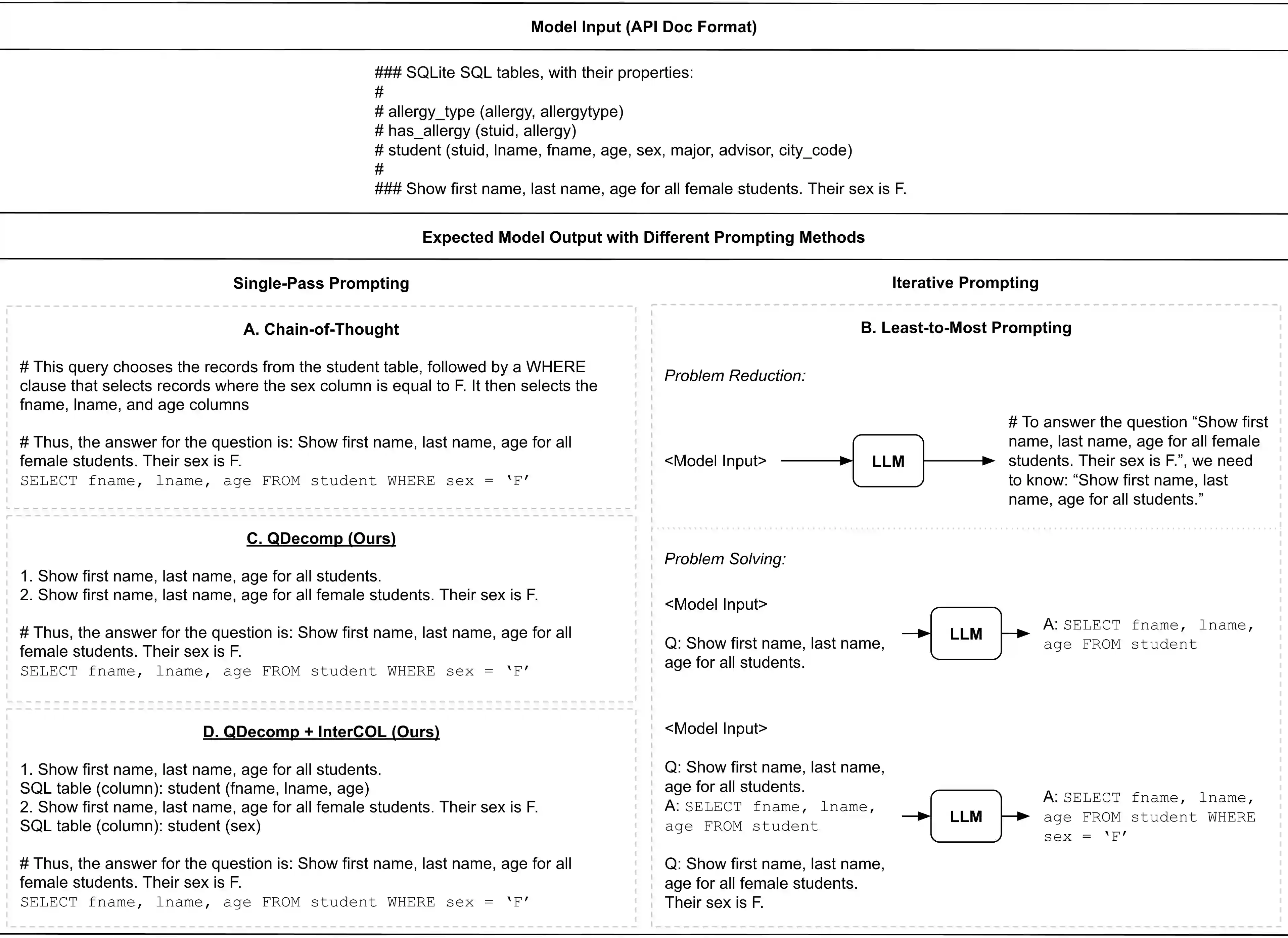
In-context learning with large language models (LLMs) has recently caught increasing attention due to its superior few-shot performance on various tasks. However, its performance on text-to-SQL parsing still has much room for improvement. In this paper, we hypothesize that a crucial aspect of LLMs to improve for text-to-SQL parsing is their multi-step reasoning ability. Thus, we systematically study how to enhance LLMs' reasoning ability through chain of thought (CoT) style prompting, including the original chain-of-thought prompting (Wei et al., 2022b) and least-to-most prompting (Zhou et al., 2023). Our experiments demonstrate that iterative prompting as in Zhou et al. (2023) may be unnecessary for text-to-SQL parsing, and using detailed reasoning steps tends to have more error propagation issues. Based on these findings, we propose a new CoT-style prompting method for text-to-SQL parsing. It brings 5.2 and 6.5 point absolute gains on the Spider development set and the Spider Realistic set, respectively, compared to the standard prompting method without reasoning steps; 2.4 and 1.5 point absolute gains, compared to the least-to-most prompting method.
翻译:近年来,基于大型语言模型(LLM)的上下文学习因其在多种任务上卓越的少样本学习能力而受到广泛关注。然而,其在文本到SQL解析任务上的性能仍有很大提升空间。本文假设,提升LLM在文本到SQL解析任务中表现的关键在于其多步推理能力。为此,我们系统研究了如何通过链式思维(CoT)风格提示——包括原始链式思维提示(Wei等,2022b)和从少到多提示(Zhou等,2023)——来增强LLM的推理能力。实验表明,Zhou等(2023)提出的迭代提示方法对文本到SQL解析而言可能并非必要,且使用详细推理步骤更容易导致错误传播问题。基于这些发现,我们提出了一种新的CoT风格提示方法用于文本到SQL解析。与不使用推理步骤的标准提示方法相比,该方法在Spider开发集和Spider Realistic集上分别取得了5.2和6.5个百分点的绝对提升;与从少到多提示方法相比,分别取得了2.4和1.5个百分点的绝对提升。