
导读
图像生成模型近几年主要由扩散模型和自回归模型占据主舞台,而 Normalizing Flow(归一化流)虽然具备精确似然估计、可逆映射和直接采样等优点,却长期受制于一个核心问题:严格可逆性让模型不得不花大量容量去拟合低层像素细节,反而难以捕捉图像的全局语义结构。ECCV 2026 论文 MIMFlow 试图重新打开这条路线:把 Masked Image Modeling(MIM)的语义学习能力直接嵌入 Flow 生成框架,并用端到端训练把表征、重建和生成统一起来。 这篇论文的关键思路可以概括为“让 Flow 少管像素噪声,多管语义流形”。MIMFlow 使用带遮挡图像作为输入,通过 VAE/ViT 编码器和可学习 latent query tokens 提取紧凑语义表示,再让 Normalizing Flow 建模这个低频、语义化、连续的 latent manifold,最后由专门的生成式 ViT decoder 负责高频纹理合成。这样,Flow 不再被迫在原始像素或高噪声 latent 上消耗容量,而可以专注于全局结构。 实验上,MIMFlow-L 在 ImageNet 256×256 上达到 FID 2.50,线性探测准确率达到 71.3%。在与相近规模 Flow 基线 SimFlow-L 对比时,FID 从 3.72 降到 2.50,提升约 32.8%。更值得注意的是,MIMFlow 只使用 128 个 latent tokens,比标准 256-token latent 模型减少一半,却仍取得强竞争力结果。
论文基本信息
论文标题:MIMFlow: Integrating Masked Image Modeling with Normalizing Flows for End-to-End Image Generation 作者:Yang Chen, Xiaowei Xu, Shuai Wang, Xinwen Zhang, Qiushi Guo, Tiezheng Ge, Limin Wang 会议:ECCV 2026 论文链接:https://arxiv.org/abs/2606.26016 PDF:https://arxiv.org/pdf/2606.26016
背景:为什么 Normalizing Flow 需要新的语义瓶颈
Normalizing Flow 的优势非常清晰:它通过一系列可逆、可微变换,将复杂数据分布映射到简单先验分布,因此既能精确计算密度,也能从同一个网络中采样。这种概率建模视角很优雅,也与 flow matching、ODE 轨迹等理论联系紧密。 但图像生成中的难点在于,图像包含大量高频纹理、局部噪声和像素级冗余。传统 Flow 为了保持严格可逆,往往必须保留和建模这些低层细节,导致模型容量被像素级信息占用,难以集中表达物体布局、类别语义、姿态和全局结构。论文将这一点视为 Flow 生成质量受限的根本瓶颈。 另一方面,Masked Image Modeling 已经在自监督视觉表征学习中证明了价值。通过遮挡大量图像 patch,再要求模型重建缺失内容,MIM 能迫使编码器学习更稳健的结构和语义表示。但过去 MIM 与生成模型的结合通常是模块化的:先预训练 tokenizer 或表征模型,再训练独立的生成模型。这样会带来表征空间与生成目标之间的错配。 MIMFlow 的切入点正是在这里:不把 MIM 当作外部预训练工具,而是把 MIM、VAE 重建和 Normalizing Flow 概率建模放进同一个端到端优化目标中。
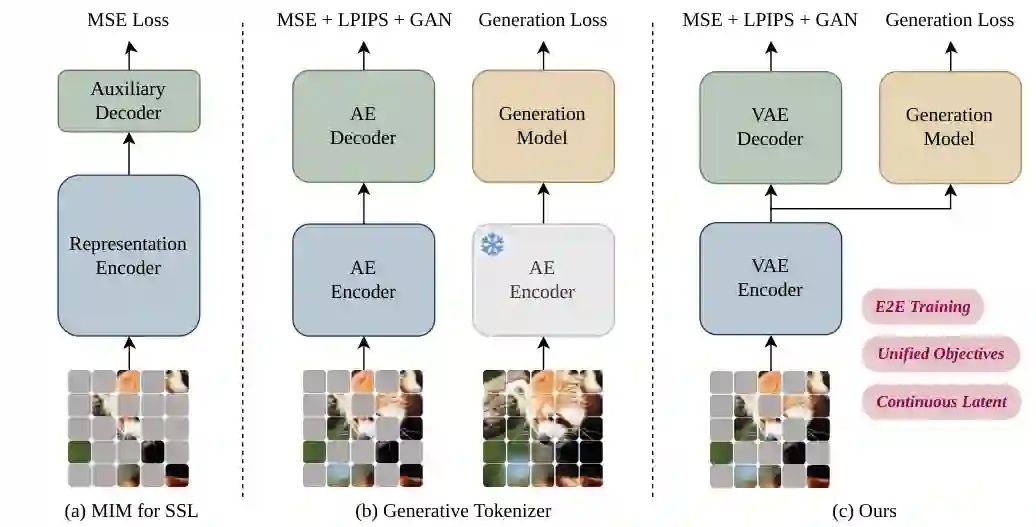
图1:不同 MIM 使用范式对比。MIMFlow 不再采用独立预训练或两阶段 tokenizer,而是把语义学习、像素重建和生成建模统一到端到端框架中。
方法:MIMFlow 的整体框架
MIMFlow 由三个核心模块组成:Masked ViT Encoder、Latent Normalizing Flow 和 Generative ViT Decoder。它们分别承担语义提取、概率建模和像素合成三类任务。 第一,Masked ViT Encoder 接收随机遮挡后的图像,通过自注意力聚合可见 patch、mask token 与可学习 query token 的信息。作者没有直接使用所有 patch tokens 作为 latent,而是引入 Learnable Token Bottleneck:在编码后只取 K 个可学习 query tokens 作为语义 latent 表示。这样做的目的是让 latent 维度固定、长度稳定、信息密度更可控。 第二,Latent Normalizing Flow 在这个紧凑 latent 空间上做概率建模。由于 MIM 已经屏蔽了部分像素细节,latent 更偏向低频语义结构,Flow 不需要再直接拟合大量高频噪声。论文将其解释为一种生成任务解耦:Flow 建模语义流形,decoder 负责纹理细节。 第三,Generative ViT Decoder 从 latent 表示恢复完整图像。训练时,MIMFlow 同时优化重建损失、Flow 负对数似然损失和辅助语义监督;后续再进行 adversarial fine-tuning,提升感知质量和高频细节。
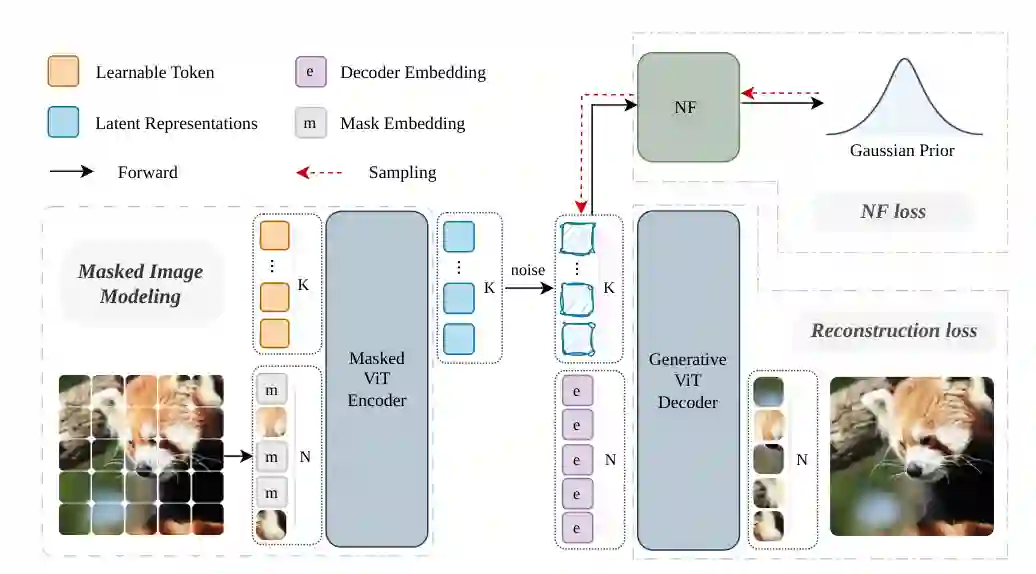
图2:MIMFlow 框架。遮挡图像经 Masked ViT Encoder 提取 K 个 latent tokens,Normalizing Flow 建模其高层语义分布,Generative ViT Decoder 负责图像重建与采样。
核心设计一:可学习 Token Bottleneck
论文认为,直接把传统 MIM 表征接入 Normalizing Flow 会遇到两个问题。MAE 只处理可见 patch,latent 序列长度和位置上下文会随 mask pattern 改变;SimMIM 虽然保留固定长度,但 mask token 与可见 token 的信息密度差异很大。这些随机性都会让 Flow 难以学习稳定分布。 MIMFlow 的解决方案是可学习 token bottleneck。给定一张图像,模型先划分为 N 个 patch 并随机遮挡,然后将 N 个图像相关 token 与 K 个可学习 query tokens 拼接输入双向 Transformer encoder。编码后只保留 K 个 query tokens,形成固定维度 latent 表示。 这个设计有两层作用。其一,K 小于 N,形成物理信息瓶颈,迫使模型压缩全局语义,而不是记忆局部纹理。其二,latent 长度不再随遮挡模式波动,Flow 可以在稳定、连续、语义密集的 latent 空间上训练。 论文默认使用 K=128。这比常见 16×16 latent grid 的 256 tokens 少一半,但实验显示它反而能取得更好的生成质量。这说明瓶颈不是简单减少信息,而是在过滤掉冗余高频细节后,提高了 latent 的有效语义密度。
核心设计二:基于 Flow 的端到端概率建模
MIMFlow 将 encoder 和 decoder 视作 VAE,同时用高容量 Normalizing Flow 替换标准高斯先验。编码器输入不是完整图像,而是遮挡图像;其输出被视为带固定方差的近似后验。Flow 则通过可逆变换将复杂 latent 分布映射到高斯先验,使模型可以精确计算 latent likelihood。 这使 MIMFlow 同时具备三种训练信号:像素重建负责保真度,Flow likelihood 负责生成分布,辅助语义监督负责提升 latent 的判别性。作者还引入 DINO、CLIP 等高层特征作为辅助目标,让 latent 不仅可重建,还具备类别和结构语义。 在训练后期,MIMFlow 对 decoder 做对抗式精修。这里的细节很关键:encoder 仍然接收遮挡图像,以保持训练时 latent posterior 与 Flow 建模的 manifold 一致。换言之,decoder 继续适配被 MIM 约束过的语义 latent,而不是突然转向完整图像编码产生的不同分布。
实验:ImageNet 256×256 上的生成质量
论文在 ImageNet 256×256 class-conditioned generation 上评估 MIMFlow。指标包括 FID、Inception Score、Precision、Recall,以及用于重建质量的 rFID;同时通过线性探测评估 encoder 表征的语义质量。 定量结果显示,MIMFlow-L 在 Flow 类方法中取得显著提升。与参数规模接近的 SimFlow-L 相比,MIMFlow-L 将有 guidance 条件下的 FID 从 3.72 降至 2.50,提升约 32.8%。它还超过更大规模的 FAE-NF-XXL(FID 2.67,约 1.4B 参数),并接近 STARFlow-XXL(FID 2.40)。 更重要的是,MIMFlow-L 仅使用 128 tokens,而多数 latent diffusion 或 latent flow 方法使用 256 tokens,STARFlow、FlowBack 等甚至使用 1024 tokens。这说明 MIMFlow 的性能提升不是来自更长 token 序列,而是来自更紧凑、更语义化的 latent manifold。

图3:MIMFlow-L 在 ImageNet 256×256 上的生成样例,使用 classifier-free guidance=2.0。
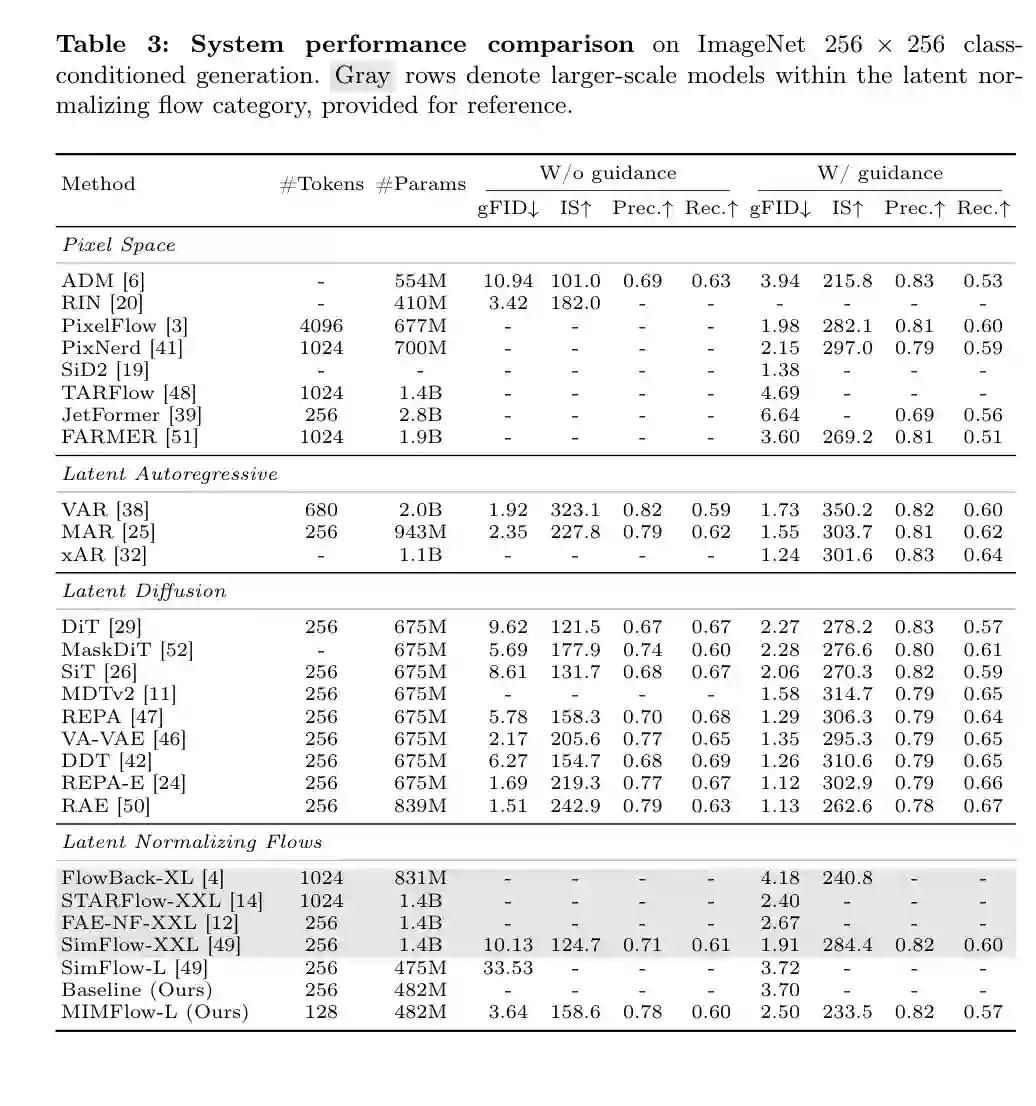
图4:ImageNet 256×256 class-conditioned generation 系统性能对比。MIMFlow-L 在 latent normalizing flows 中取得强竞争力结果,并只使用 128 tokens。
消融:为什么 Mask、128 Tokens 和语义监督有效
论文的消融实验直接验证了 MIMFlow 的几个关键设计。 首先是遮挡策略。无 mask 的模型表现最差,gFID 为 29.0,线性探测准确率为 56.6%。当 mask ratio 设为 0.4-0.6 时,gFID 降至 12.82,线性探测准确率升至 71.3%。这说明遮挡不是普通数据增强,而是迫使模型把 Flow 从像素细节中解耦出来的关键机制。过低 mask ratio 或混合策略反而会退化,说明稳定且足够强的信息瓶颈很重要。 其次是辅助监督。DINO+CLIP 的组合取得最好结果,rFID 3.60、gFID 12.46、IS 92.3。相比之下,引入 HOG 这类低层特征会导致训练崩溃或性能下降。这与论文假设一致:MIMFlow 需要的是高层语义先验,而不是再次把 latent 拉回局部纹理和梯度统计。 第三是 token 数量。64 tokens 已能给出合理结果,128 tokens 达到最佳平衡;继续增大到 192 tokens,性能反而大幅下降。这说明 latent 空间过大时,高频噪声会重新泄漏给 Flow,破坏语义压缩带来的优势。 最后是 latent noise scale。σ=0.3 表现最好,过小不足以平滑 manifold,过大会损害重建质量。这体现了端到端 Flow 建模对 latent 随机性的精细要求。
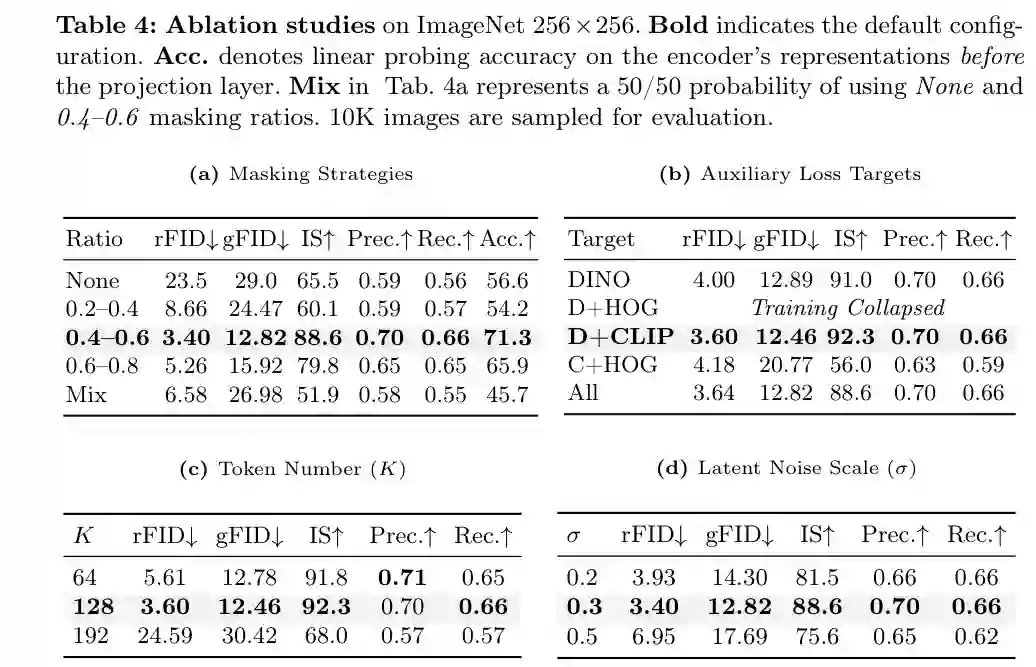
图5:MIMFlow 的关键消融。0.4-0.6 遮挡比例、DINO+CLIP 辅助监督、128 latent tokens 和 σ=0.3 构成默认配置。
分析:更可分的语义空间与更稳定的 Flow
为了说明方法为何有效,论文进一步分析 latent space 和 Flow dynamics。UMAP 可视化显示,相比标准 SD-VAE,MIMFlow 学到的 latent space 呈现更清晰的类别结构。这与线性探测准确率 71.3% 相互印证:MIMFlow 的 latent 不只是可重建,更具语义可分性。

图6:ImageNet latent space 的 UMAP 可视化。MIMFlow 相比 SD-VAE 呈现更清晰的类别区分。 论文还通过 Jacobian spectral analysis 比较 MIMFlow 与 STARFlow。结果显示,MIMFlow 具有更大且更稳定的最小奇异值,并且 log-condition number 更低、更集中。这意味着 Flow 映射更接近良条件变换,对数值扰动更不敏感,也更有利于稳定优化。
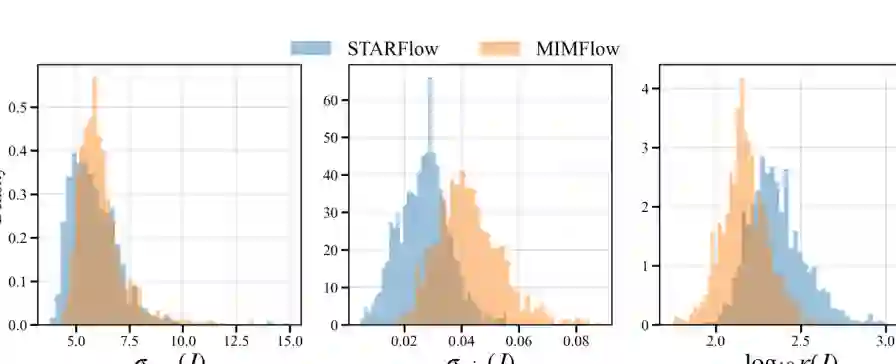
图7:MIMFlow 与 STARFlow 的 Jacobian 谱分析。MIMFlow 的条件数更集中,说明 Flow 变换更稳定。
总结:MIMFlow 的意义与启发
MIMFlow 的贡献不是简单把 MIM 加到生成模型里,而是重新划分图像生成中的任务边界:语义结构由 MIM 约束下的紧凑 latent 表示承担,概率建模由 Normalizing Flow 完成,高频纹理由 decoder 合成。这种解耦缓解了传统 Flow 的容量瓶颈,让 Flow 不再被低层像素噪声拖住。 从更大的方向看,MIMFlow 说明自监督表征学习和概率生成建模可以被更紧密地统一起来。过去很多生成管线依赖预训练 tokenizer 或外部视觉特征,再把生成模型放在冻结 latent 上训练;MIMFlow 则证明端到端联合优化可以让 latent 空间同时服务于重建、语义和生成。 当然,MIMFlow 仍主要在 ImageNet 256×256 上验证,未来还需要看它在更高分辨率、更复杂数据集、多模态条件生成以及更大规模模型中的表现。但对于 Normalizing Flow 这一长期被认为“理论优雅但生成质量受限”的路线来说,MIMFlow 提供了一个非常清晰的新方向:不要让 Flow 直接承担所有像素细节,而要给它一个更干净、更语义化、更紧凑的建模空间。