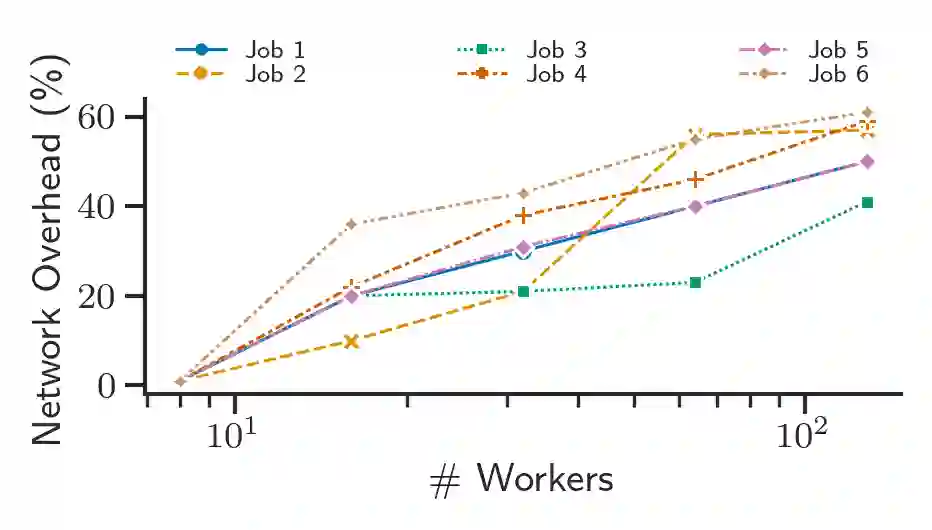
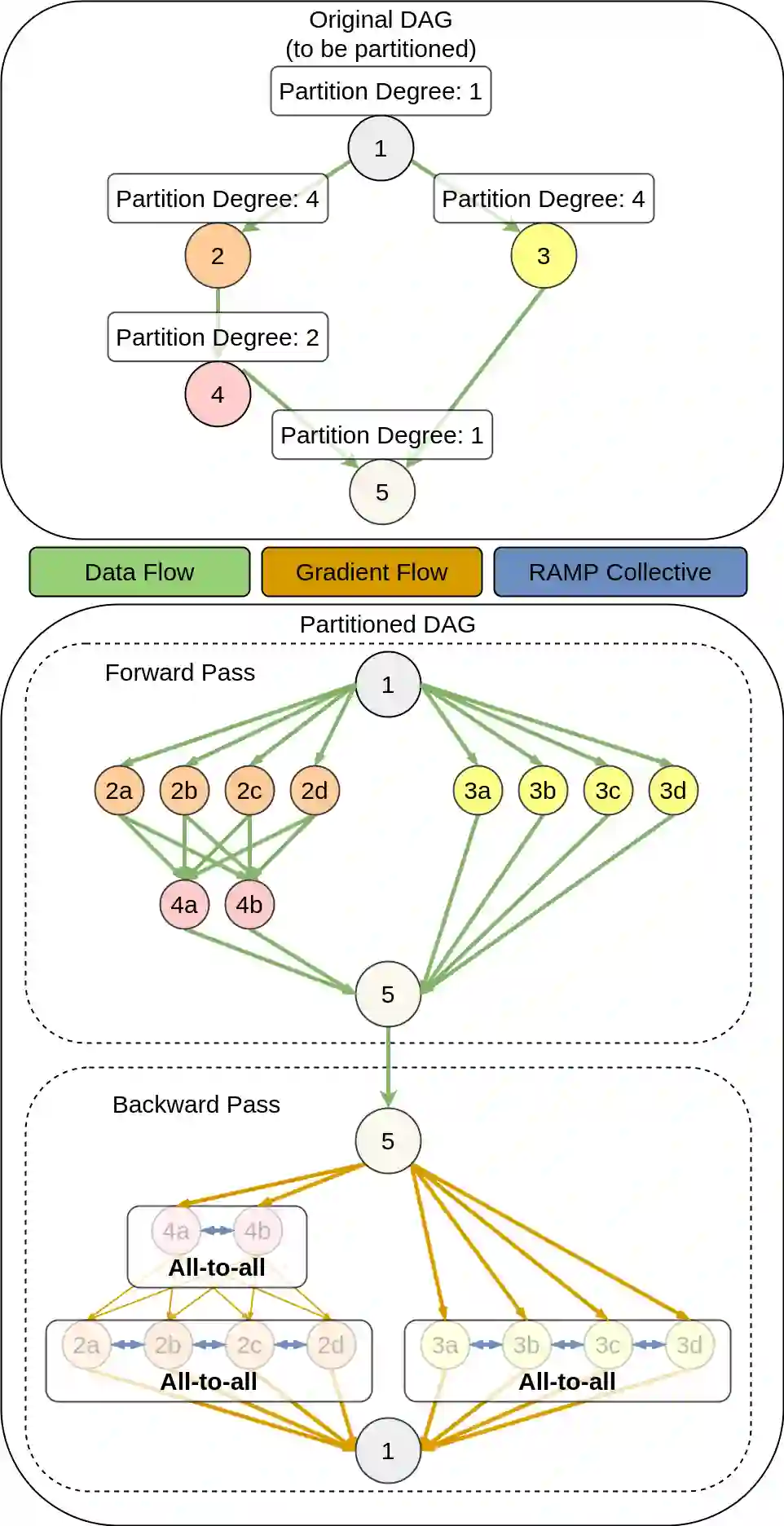
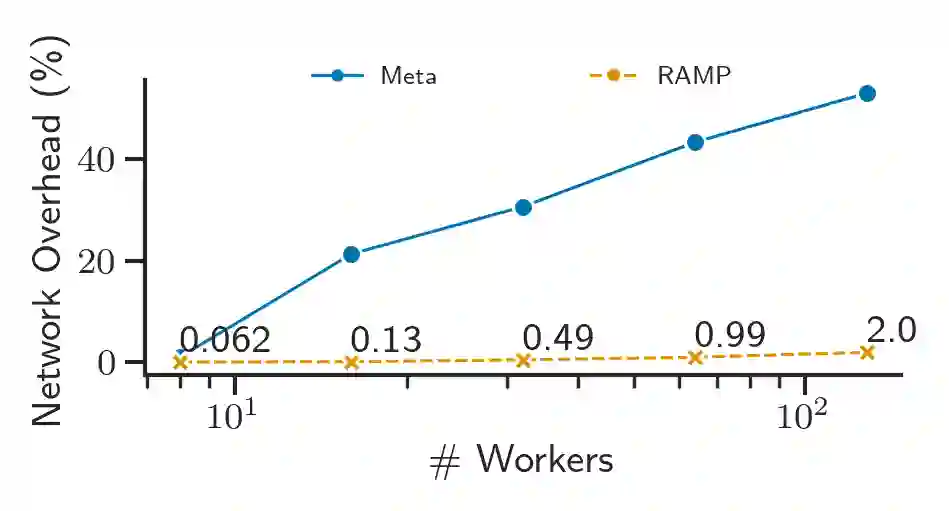
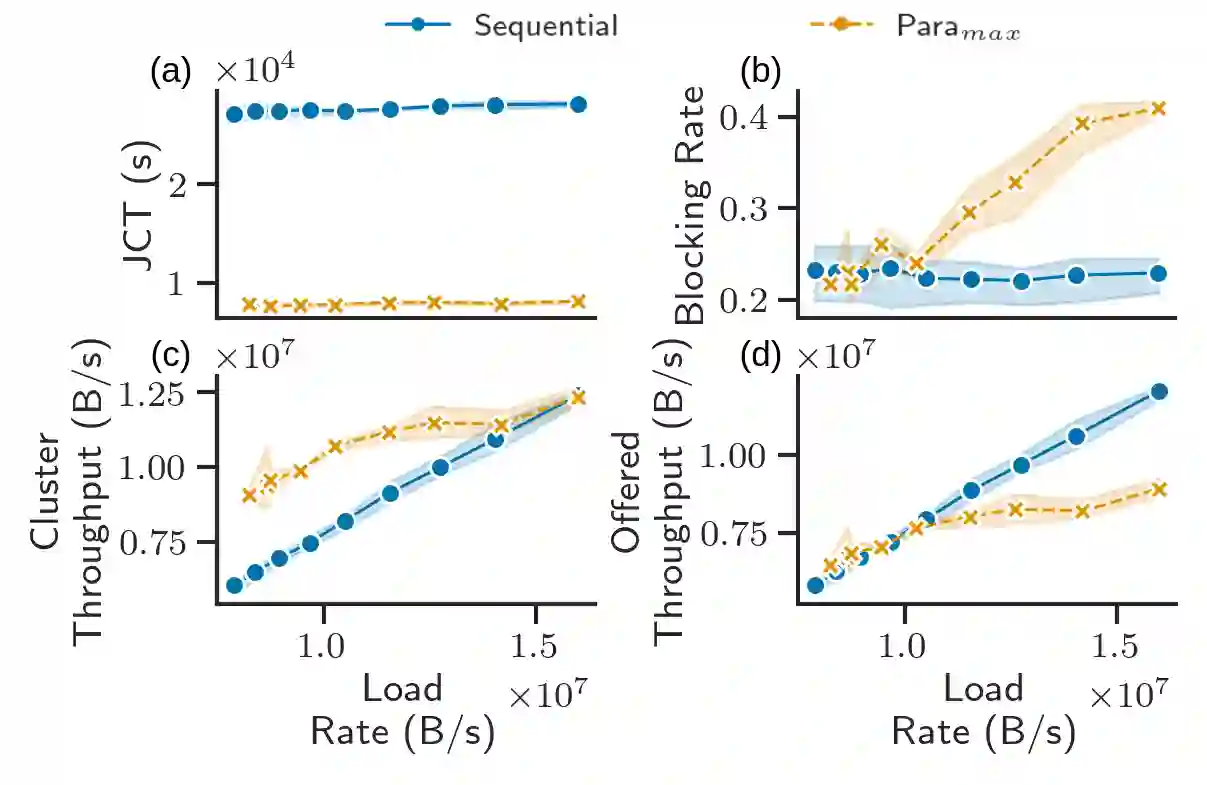
From natural language processing to genome sequencing, large-scale machine learning models are bringing advances to a broad range of fields. Many of these models are too large to be trained on a single machine, and instead must be distributed across multiple devices. This has motivated the research of new compute and network systems capable of handling such tasks. In particular, recent work has focused on developing management schemes which decide how to allocate distributed resources such that some overall objective, such as minimising the job completion time (JCT), is optimised. However, such studies omit explicit consideration of how much a job should be distributed, usually assuming that maximum distribution is desirable. In this work, we show that maximum parallelisation is sub-optimal in relation to user-critical metrics such as throughput and blocking rate. To address this, we propose PAC-ML (partitioning for asynchronous computing with machine learning). PAC-ML leverages a graph neural network and reinforcement learning to learn how much to partition computation graphs such that the number of jobs which meet arbitrary user-defined JCT requirements is maximised. In experiments with five real deep learning computation graphs on a recently proposed optical architecture across four user-defined JCT requirement distributions, we demonstrate PAC-ML achieving up to 56.2% lower blocking rates in dynamic job arrival settings than the canonical maximum parallelisation strategy used by most prior works.
翻译:从自然语言处理到基因组测序,大规模机器学习模型正在推动众多领域的进步。许多此类模型因规模过大而无法在单台机器上训练,必须分布到多台设备上。这促使研究人员开发能够处理此类任务的新型计算和网络系统。具体而言,近期工作聚焦于开发管理方案,以决定如何分配分布式资源,从而优化作业完成时间(JCT)等总体目标。然而,这些研究忽略了应如何分布作业的显式考量,通常默认最大程度分布是最优策略。本研究表明,在吞吐量和阻塞率等用户关键指标方面,最大并行化并非最优方案。为解决此问题,我们提出PAC-ML(基于机器学习的异步计算划分方法)。该方法利用图神经网络和强化学习来学习计算图的划分程度,从而最大化满足用户自定义JCT要求的作业数量。在最近提出的光架构上,使用五个真实深度学习计算图进行实验,针对四种用户自定义JCT要求分布,我们证明PAC-ML在动态作业到达场景中实现的阻塞率比大多数先前工作采用的标准最大并行化策略低达56.2%。