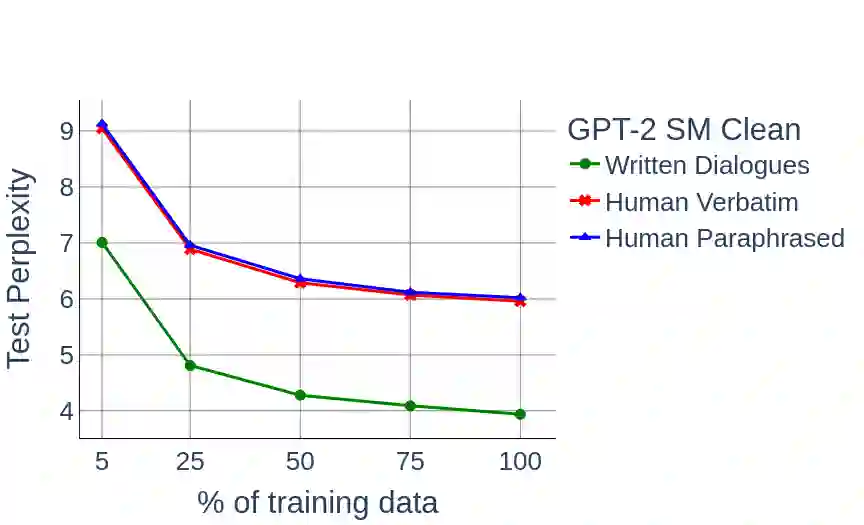
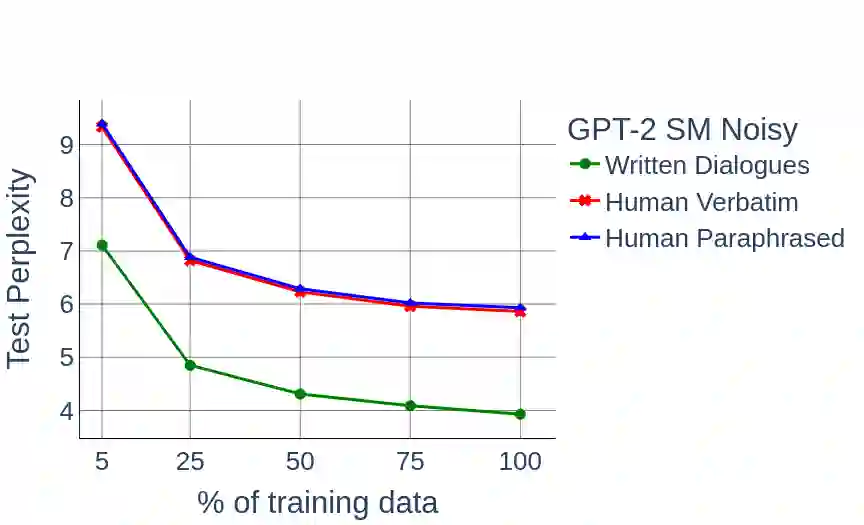
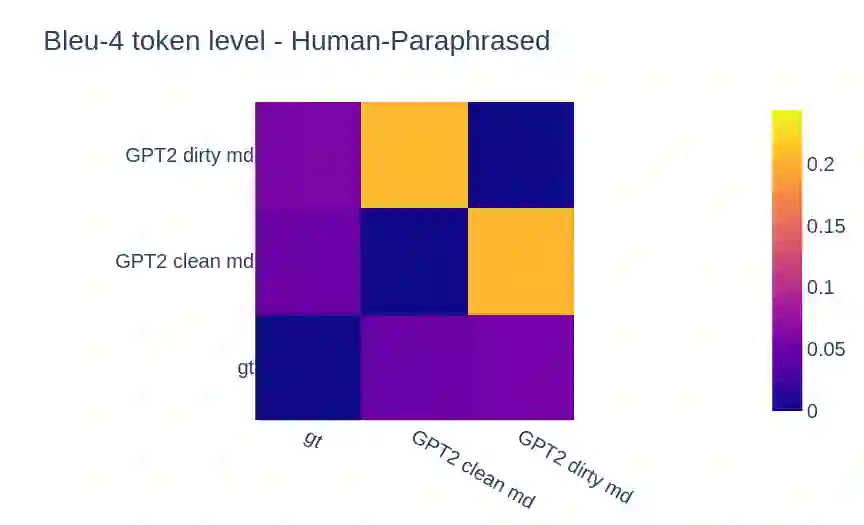
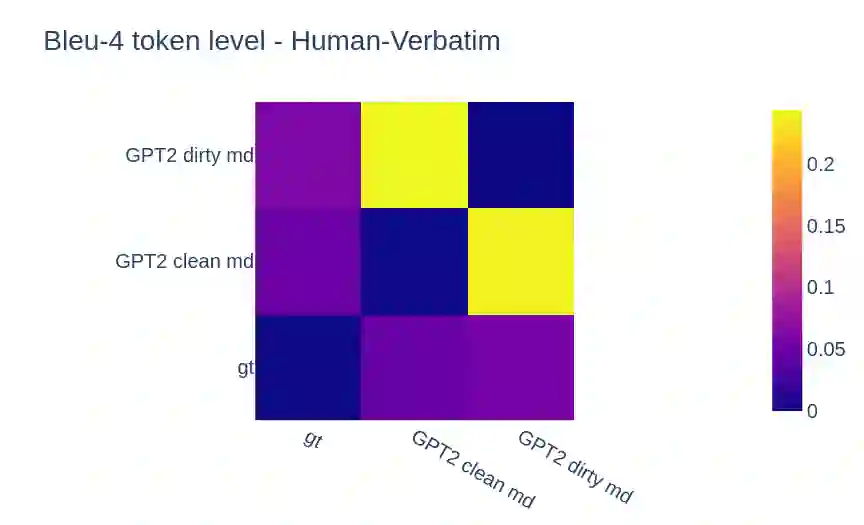
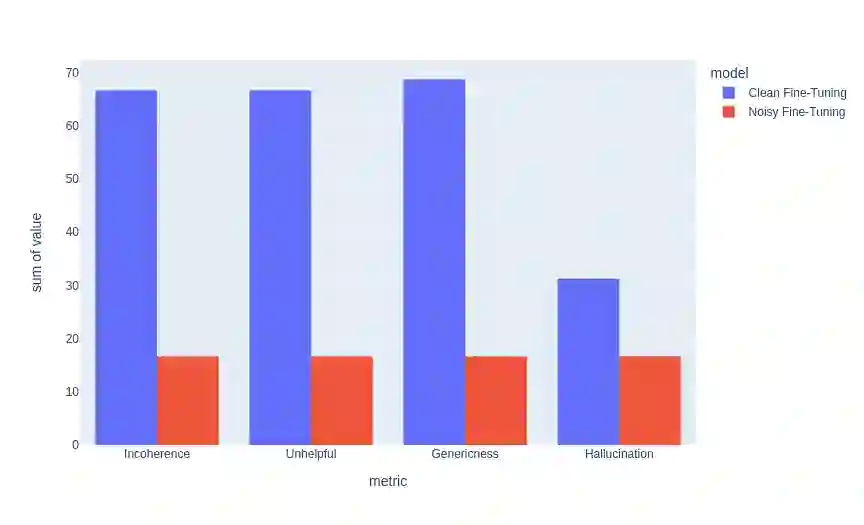
Large Pre-Trained Language Models have demonstrated state-of-the-art performance in different downstream tasks, including dialogue state tracking and end-to-end response generation. Nevertheless, most of the publicly available datasets and benchmarks on task-oriented dialogues focus on written conversations. Consequently, the robustness of the developed models to spoken interactions is unknown. In this work, we have evaluated the performance of LLMs for spoken task-oriented dialogues on the DSTC11 test sets. Due to the lack of proper spoken dialogue datasets, we have automatically transcribed a development set of spoken dialogues with a state-of-the-art ASR engine. We have characterized the ASR-error types and their distributions and simulated these errors in a large dataset of dialogues. We report the intrinsic (perplexity) and extrinsic (human evaluation) performance of fine-tuned GPT-2 and T5 models in two subtasks of response generation and dialogue state tracking, respectively. The results show that LLMs are not robust to spoken noise by default, however, fine-tuning/training such models on a proper dataset of spoken TODs can result in a more robust performance.
翻译:大型预训练语言模型已在不同下游任务中展现出最先进的性能,包括对话状态追踪和端到端响应生成。然而,目前大多数面向任务的对话公开数据集和基准测试均聚焦于书面对话。因此,这些模型在口语交互中的鲁棒性尚不明确。本研究在DSTC11测试集上评估了大型语言模型在口语任务导向对话中的表现。由于缺乏合适的口语对话数据集,我们使用最先进的自动语音识别引擎对开发集中的口语对话进行自动转写,并分析了语音识别错误的类型及其分布,进而在一个大规模对话数据集中模拟了这些错误。我们报告了经过微调的GPT-2和T5模型在响应生成与对话状态追踪两个子任务中的内在性能(困惑度)与外在性能(人工评估)。结果表明,大型语言模型在默认情况下对口语噪声不具备鲁棒性;然而,在合适的口语任务导向对话数据集上微调或训练此类模型,可以提升其鲁棒性能。