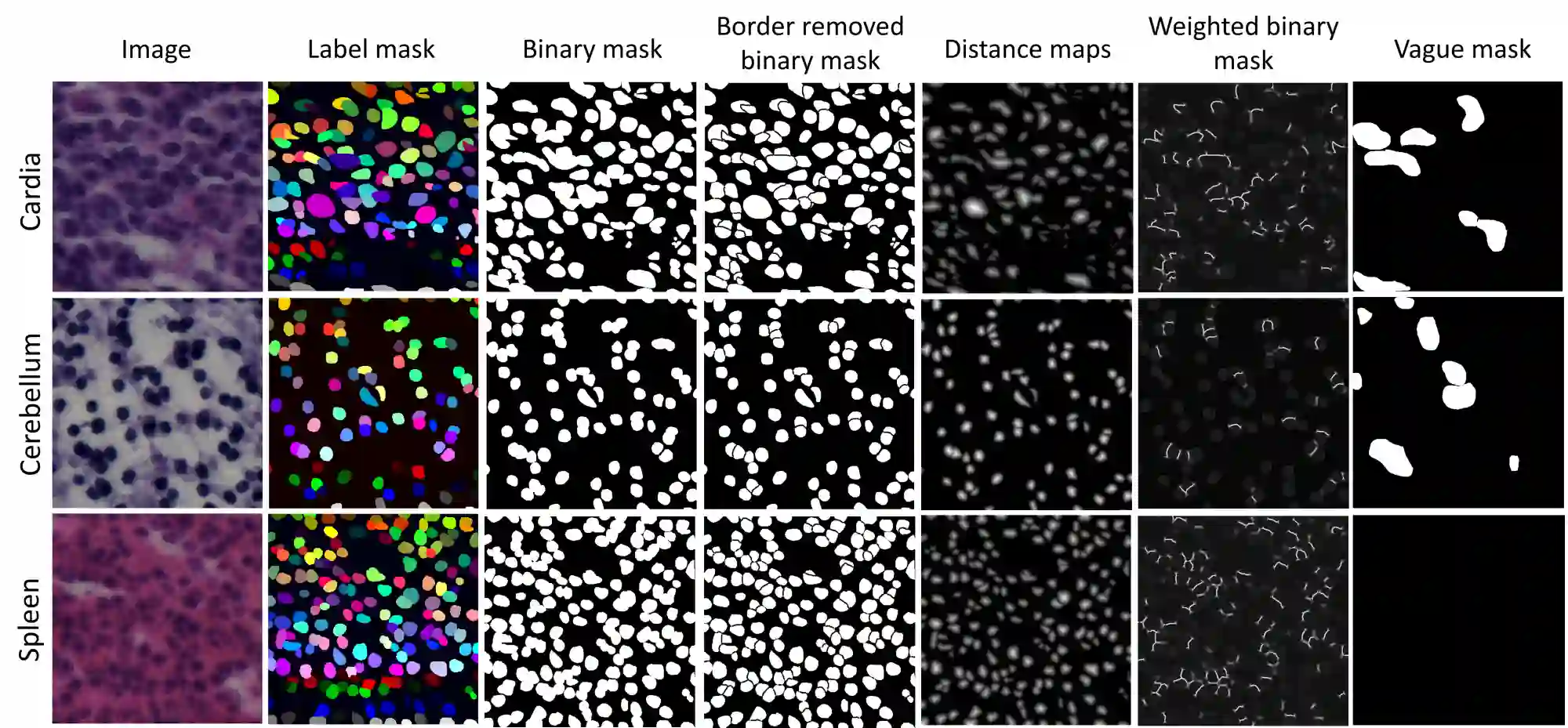
In computational pathology, automatic nuclei instance segmentation plays an essential role in whole slide image analysis. While many computerized approaches have been proposed for this task, supervised deep learning (DL) methods have shown superior segmentation performances compared to classical machine learning and image processing techniques. However, these models need fully annotated datasets for training which is challenging to acquire, especially in the medical domain. In this work, we release one of the biggest fully manually annotated datasets of nuclei in Hematoxylin and Eosin (H&E)-stained histological images, called NuInsSeg. This dataset contains 665 image patches with more than 30,000 manually segmented nuclei from 31 human and mouse organs. Moreover, for the first time, we provide additional ambiguous area masks for the entire dataset. These vague areas represent the parts of the images where precise and deterministic manual annotations are impossible, even for human experts. The dataset and detailed step-by-step instructions to generate related segmentation masks are publicly available at https://www.kaggle.com/datasets/ipateam/nuinsseg and https://github.com/masih4/NuInsSeg, respectively.
翻译:在计算病理学中,自动细胞核实例分割在全切片图像分析中起着至关重要的作用。尽管已提出多种计算机化方法解决此任务,但与传统机器学习及图像处理技术相比,监督式深度学习方法展现了更优越的分割性能。然而,这些模型需要完全注释的数据集进行训练,这在医学领域尤其难以获取。在本工作中,我们发布了一个规模最大的H&E染色组织学图像细胞核全人工注释数据集——NuInsSeg。该数据集包含665个图像块,涵盖来自31个人类及小鼠器官的超过30,000个经人工分割的细胞核。此外,我们首次为整个数据集提供了额外的模糊区域掩码。这些模糊区域代表图像中精确且确定的标注无法实现的区域,即便对于人类专家亦然。该数据集及生成相关分割掩码的详细分步指南已分别公开于https://www.kaggle.com/datasets/ipateam/nuinsseg 和 https://github.com/masih4/NuInsSeg。