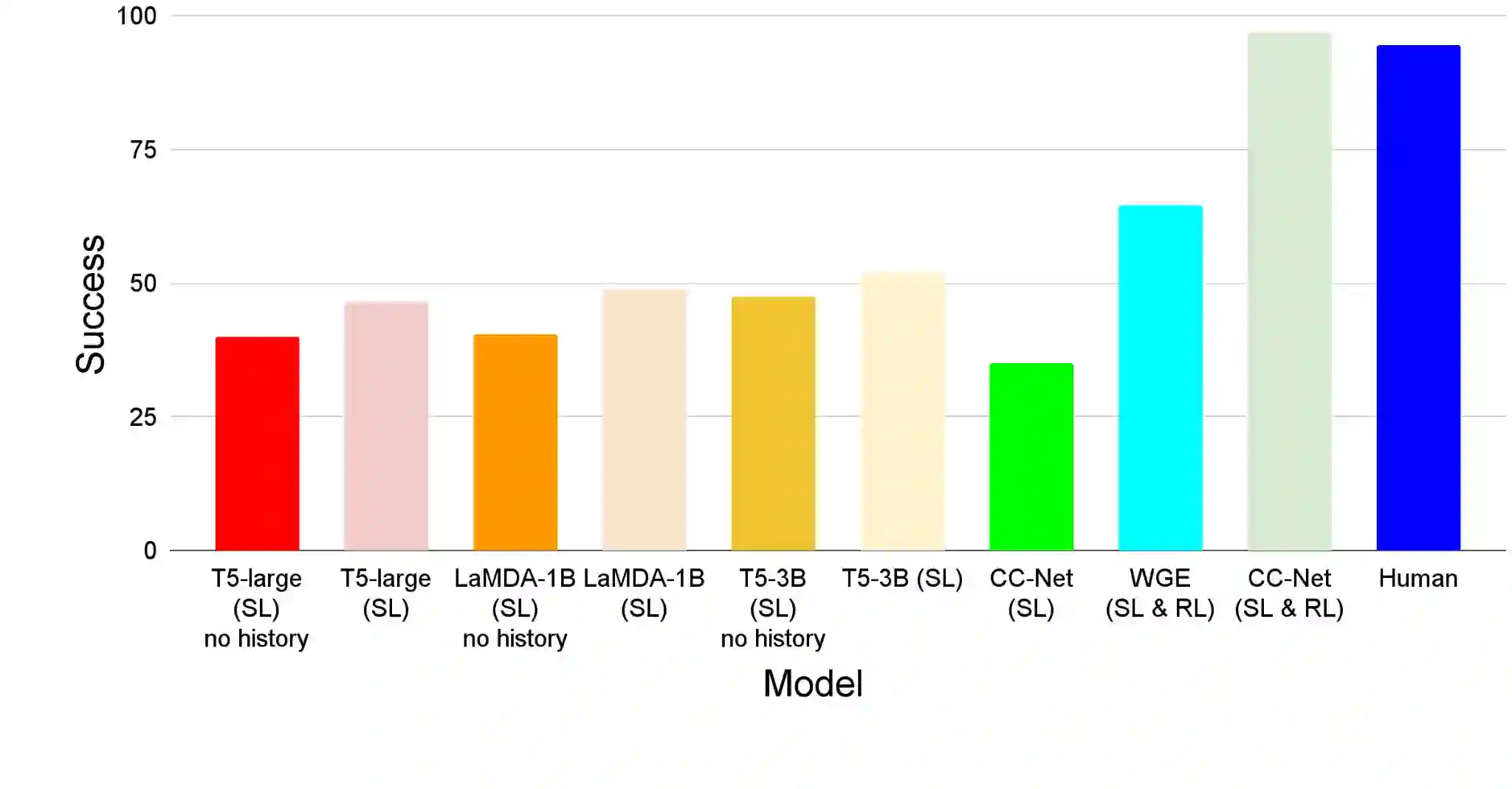
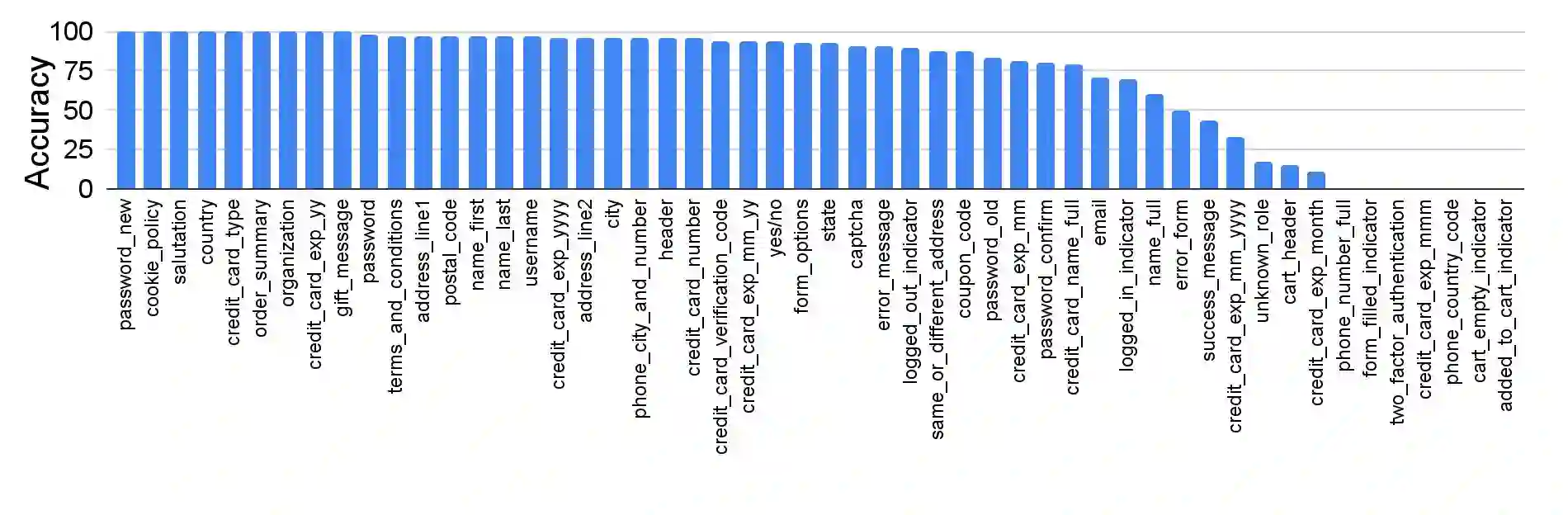
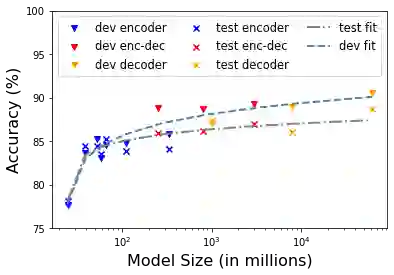
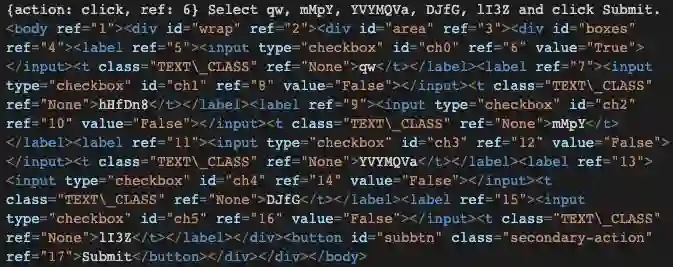
Large language models (LLMs) have shown exceptional performance on a variety of natural language tasks. Yet, their capabilities for HTML understanding -- i.e., parsing the raw HTML of a webpage, with applications to automation of web-based tasks, crawling, and browser-assisted retrieval -- have not been fully explored. We contribute HTML understanding models (fine-tuned LLMs) and an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Description Generation for HTML inputs, and (iii) Autonomous Web Navigation of HTML pages. While previous work has developed dedicated architectures and training procedures for HTML understanding, we show that LLMs pretrained on standard natural language corpora transfer remarkably well to HTML understanding tasks. For instance, fine-tuned LLMs are 12% more accurate at semantic classification compared to models trained exclusively on the task dataset. Moreover, when fine-tuned on data from the MiniWoB benchmark, LLMs successfully complete 50% more tasks using 192x less data compared to the previous best supervised model. Out of the LLMs we evaluate, we show evidence that T5-based models are ideal due to their bidirectional encoder-decoder architecture. To promote further research on LLMs for HTML understanding, we create and open-source a large-scale HTML dataset distilled and auto-labeled from CommonCrawl.
翻译:大型语言模型(LLMs)在各类自然语言任务中表现出卓越性能。然而,其HTML理解能力——即解析网页原始HTML,应用于基于网页的任务自动化、网页爬取及浏览器辅助检索——尚未得到充分探索。我们贡献了HTML理解模型(经微调的LLMs),并深入分析了它们在以下三项任务中的能力:(i) HTML元素的语义分类,(ii) HTML输入的描述生成,以及(iii) HTML页面的自主网页导航。尽管先前研究为HTML理解开发了专用架构与训练流程,但我们发现:在标准自然语言语料库上预训练的LLMs,能显著迁移至HTML理解任务。例如,与仅在任务数据集上训练的模型相比,经微调的LLMs在语义分类上准确率提升12%。此外,当使用MiniWoB基准数据进行微调时,LLMs以192倍更少的数据成功完成的任务数量比先前最佳监督模型多50%。在我们评估的LLMs中,有证据表明T5系列模型因其双向编码器-解码器架构而成为理想选择。为促进LLMs在HTML理解领域的进一步研究,我们创建并开源了一个从CommonCrawl中提炼并自动标注的大规模HTML数据集。