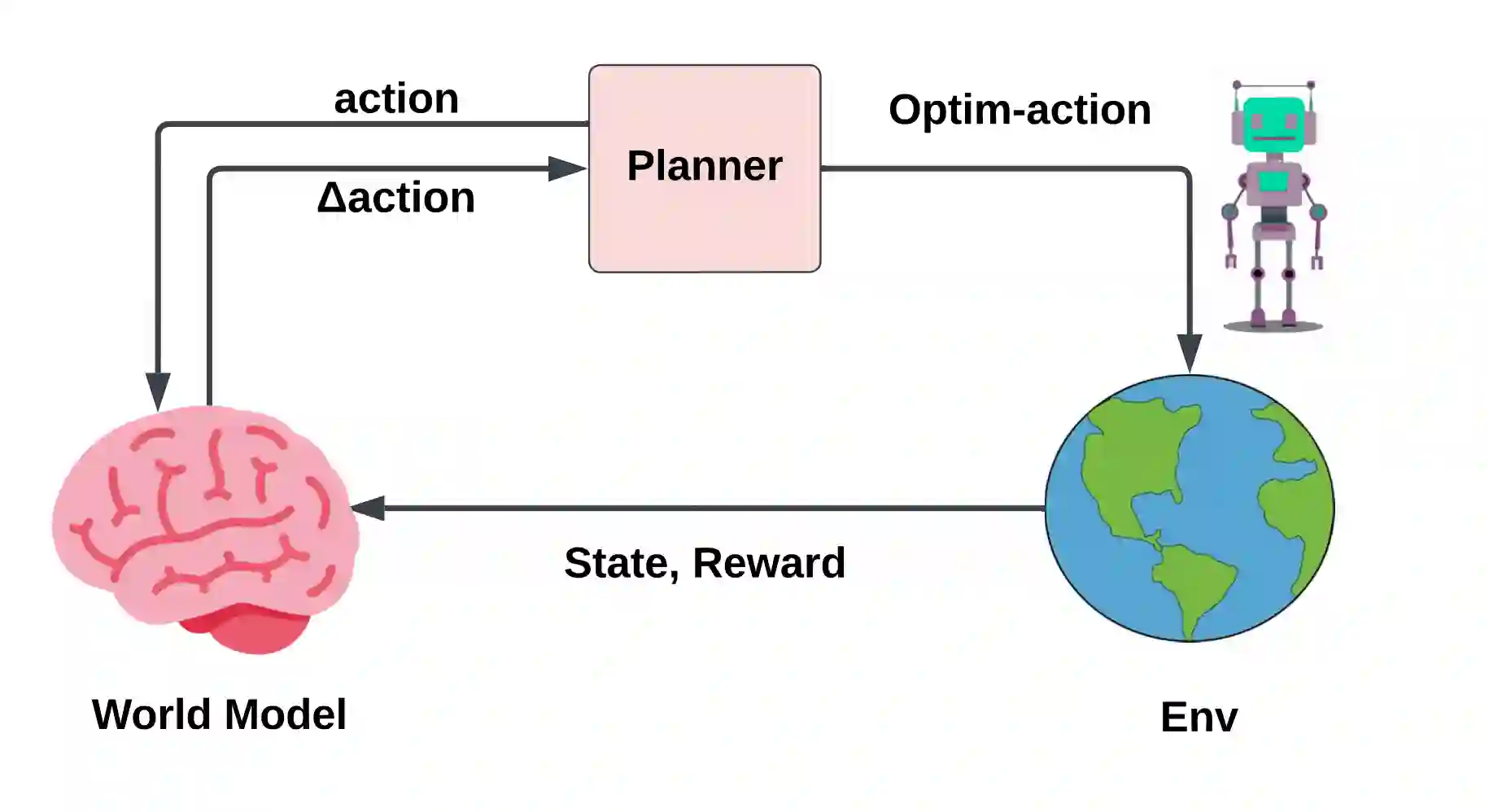
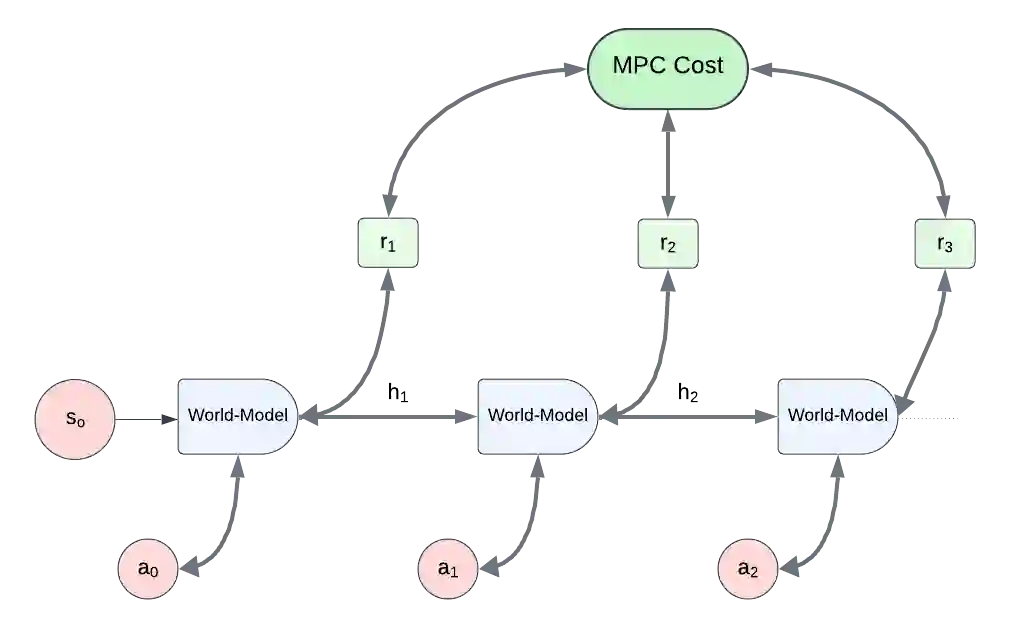
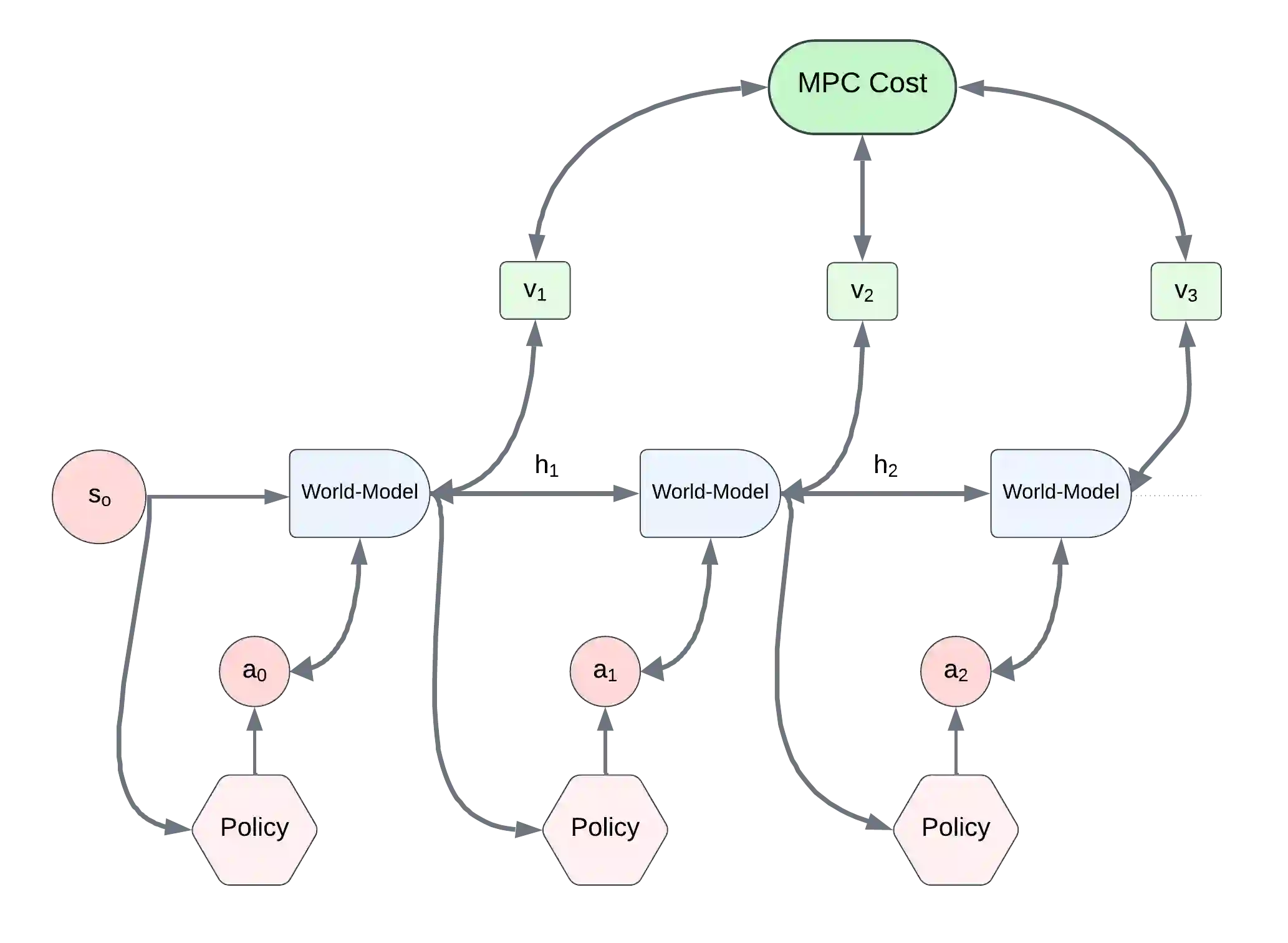
The enduring challenge in the field of artificial intelligence has been the control of systems to achieve desired behaviours. While for systems governed by straightforward dynamics equations, methods like Linear Quadratic Regulation (LQR) have historically proven highly effective, most real-world tasks, which require a general problem-solver, demand world models with dynamics that cannot be easily described by simple equations. Consequently, these models must be learned from data using neural networks. Most model predictive control (MPC) algorithms designed for visual world models have traditionally explored gradient-free population-based optimisation methods, such as Cross Entropy and Model Predictive Path Integral (MPPI) for planning. However, we present an exploration of a gradient-based alternative that fully leverages the differentiability of the world model. In our study, we conduct a comparative analysis between our method and other MPC-based alternatives, as well as policy-based algorithms. In a sample-efficient setting, our method achieves on par or superior performance compared to the alternative approaches in most tasks. Additionally, we introduce a hybrid model that combines policy networks and gradient-based MPC, which outperforms pure policy based methods thereby holding promise for Gradient-based planning with world models in complex real-world tasks.
翻译:人工智能领域长期存在的挑战是如何控制系统以实现期望行为。对于由简单动力学方程描述的系统,如线性二次型调节器(LQR)等经典方法已被证明极为有效,但大多数需要通用问题求解器的实际任务要求建立动力学难以用简单方程描述的世界模型。因此,这类模型必须利用神经网络从数据中学习。传统上,为视觉世界模型设计的模型预测控制(MPC)算法通常采用基于种群的无梯度优化方法进行规划,例如交叉熵方法和模型预测路径积分(MPPI)算法。然而,本文探索了一种基于梯度的替代方案,该方案充分利用了世界模型的可微特性。在我们的研究中,将该方法与其他基于MPC的算法以及基于策略的算法进行了对比分析。在样本效率受限的条件下,本方法在大多数任务中取得了与对比方法相当或更优的性能。此外,我们提出了一种融合策略网络与基于梯度MPC的混合模型,该模型在复杂实际任务中优于纯策略方法,展现了基于梯度的世界模型规划方法的应用潜力。