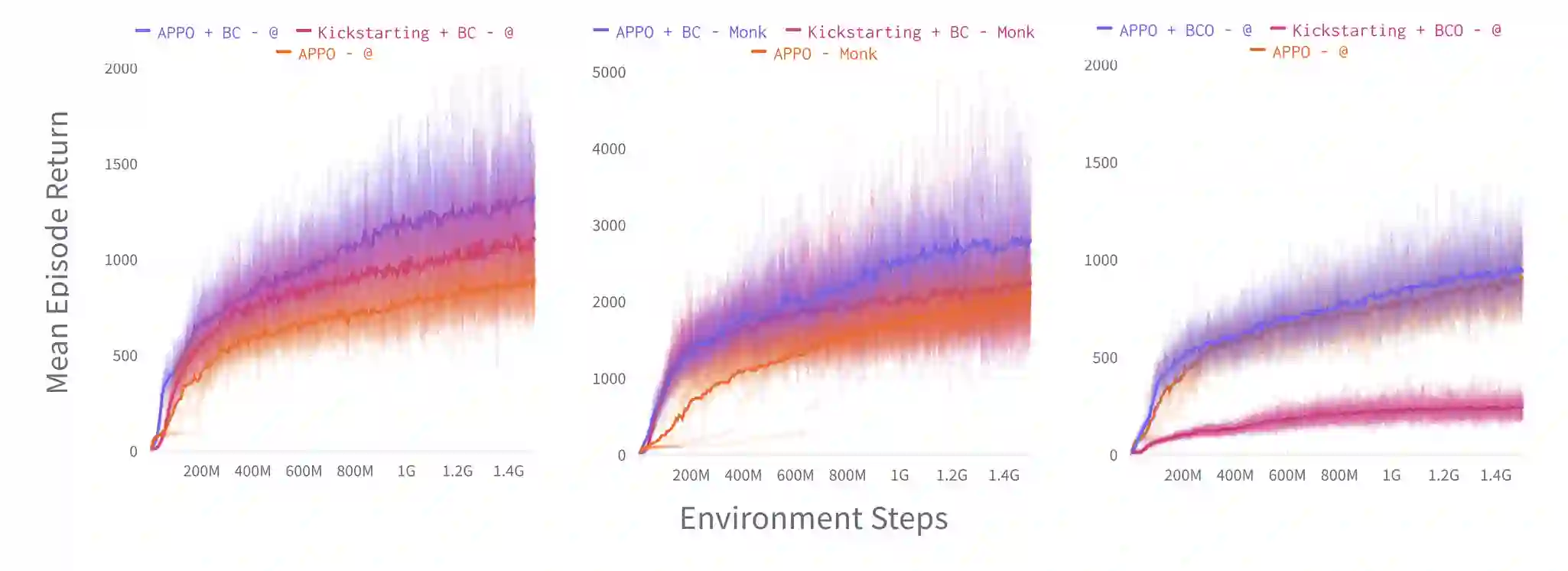
Recent breakthroughs in the development of agents to solve challenging sequential decision making problems such as Go, StarCraft, or DOTA, have relied on both simulated environments and large-scale datasets. However, progress on this research has been hindered by the scarcity of open-sourced datasets and the prohibitive computational cost to work with them. Here we present the NetHack Learning Dataset (NLD), a large and highly-scalable dataset of trajectories from the popular game of NetHack, which is both extremely challenging for current methods and very fast to run. NLD consists of three parts: 10 billion state transitions from 1.5 million human trajectories collected on the NAO public NetHack server from 2009 to 2020; 3 billion state-action-score transitions from 100,000 trajectories collected from the symbolic bot winner of the NetHack Challenge 2021; and, accompanying code for users to record, load and stream any collection of such trajectories in a highly compressed form. We evaluate a wide range of existing algorithms including online and offline RL, as well as learning from demonstrations, showing that significant research advances are needed to fully leverage large-scale datasets for challenging sequential decision making tasks.
翻译:近期在解决诸如围棋、星际争霸或DOTA等复杂序贯决策问题的智能体开发中取得了突破性进展,这既依赖于模拟环境也依赖于大规模数据集。然而,由于开源数据集的稀缺性以及处理这些数据所需的巨大计算成本,相关研究进展一直受到阻碍。本文提出NetHack学习数据集(NLD),这是一个来自热门游戏NetHack的大规模、高可扩展性轨迹数据集,该游戏对现有方法极具挑战性且运行效率极高。NLD包含三部分:从2009年至2020年在NAO公共NetHack服务器收集的150万条人类玩家轨迹中提取的100亿个状态转移数据;从NetHack挑战赛2021符号化机器人获胜者收集的10万条轨迹中提取的30亿个状态-动作-得分转移数据;以及配套代码,允许用户以高压缩形式记录、加载和流式传输任意轨迹集合。我们评估了包括在线与离线强化学习以及基于示范学习在内的多种现有算法,结果表明要充分挖掘大规模数据集在复杂序贯决策任务中的潜力,仍需开展大量研究创新。