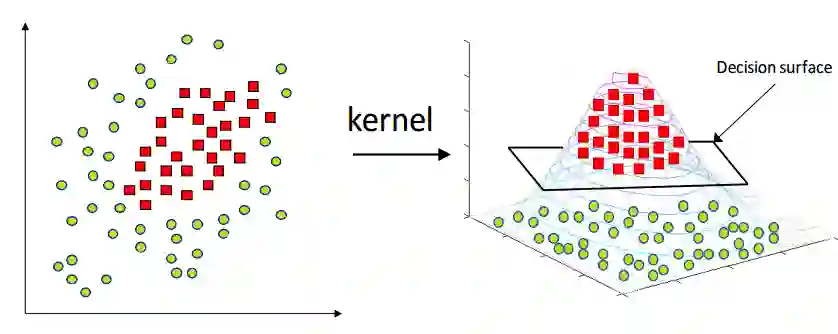
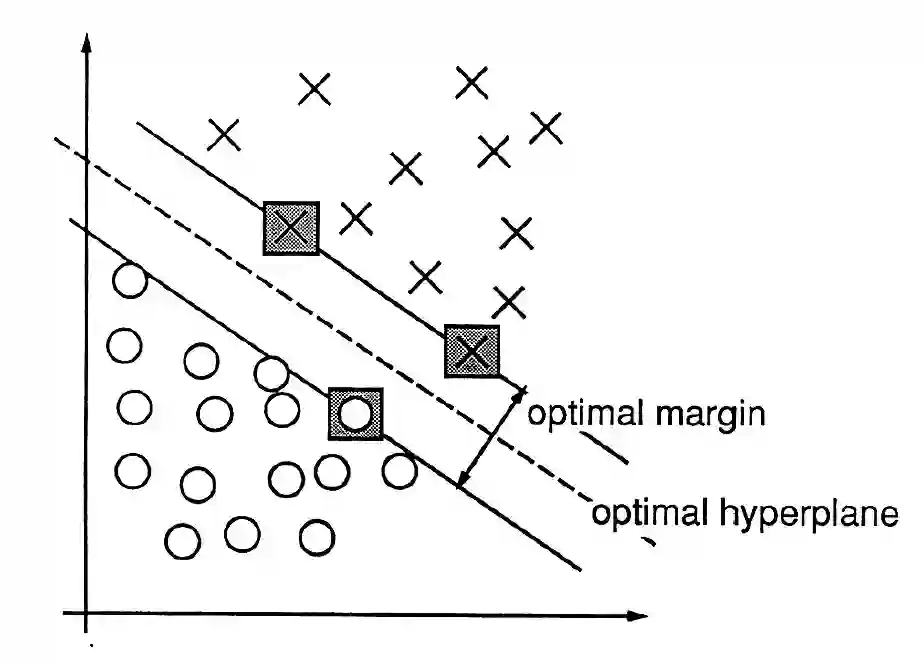
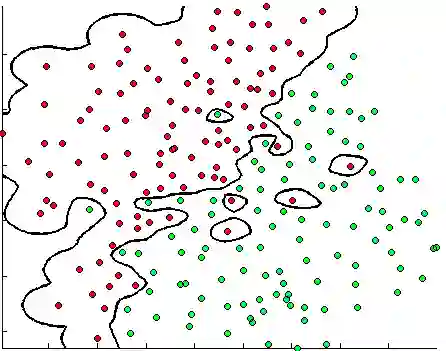
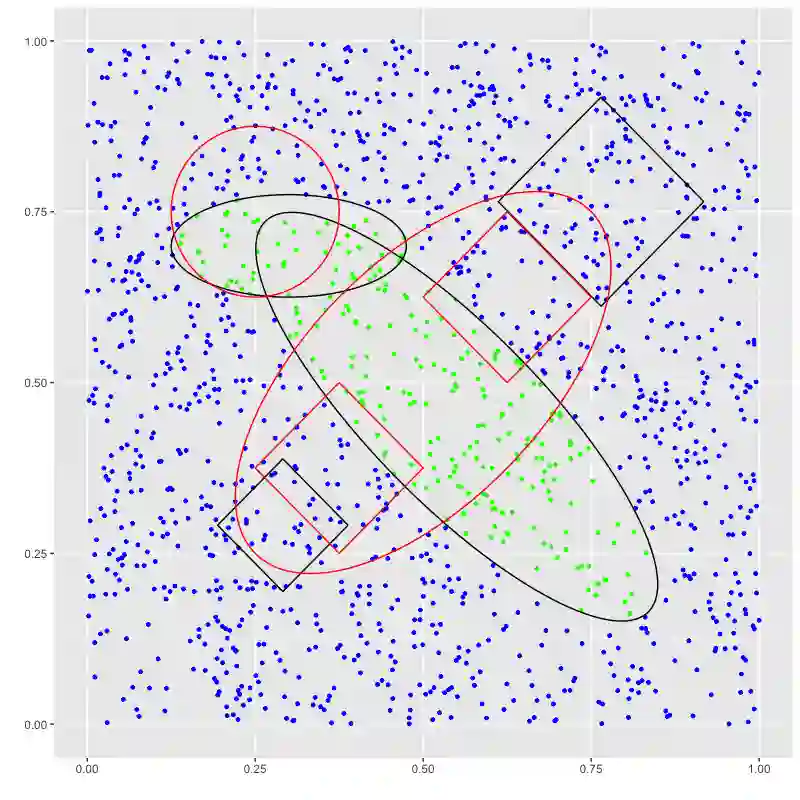
Economic models produce moment inequalities, which can be used to form tests of the true parameters. Confidence sets (CS) of the true parameters are derived by inverting these tests. However, they often lack analytical expressions, necessitating a grid search to obtain the CS numerically by retaining the grid points that pass the test. When the statistic is not asymptotically pivotal, constructing the critical value for each grid point in the parameter space adds to the computational burden. In this paper, we convert the computational issue into a classification problem by using a support vector machine (SVM) classifier. Its decision function provides a faster and more systematic way of dividing the parameter space into two regions: inside vs. outside of the confidence set. We label those points in the CS as 1 and those outside as -1. Researchers can train the SVM classifier on a grid of manageable size and use it to determine whether points on denser grids are in the CS or not. We establish certain conditions for the grid so that there is a tuning that allows us to asymptotically reproduce the test in the CS. This means that in the limit, a point is classified as belonging to the confidence set if and only if it is labeled as 1 by the SVM.
翻译:经济模型可产生矩不等式,用于检验真实参数。通过在参数空间内反演这些检验,可推导出真实参数的置信集。然而,置信集往往缺乏解析表达式,需通过网格搜索保留通过检验的网格点来数值化地获取。当检验统计量不具有渐近枢轴性时,需为参数空间中每个网格点构造临界值,这进一步增加了计算负担。本文利用支持向量机分类器将计算问题转化为分类问题:其决策函数能更快速、系统地划分参数空间为两个区域(置信集内部与外部)。我们将置信集内的网格点标记为1,外部点标记为-1。研究者可在规模可控的网格上训练支持向量机分类器,并用其判断更密集网格上的点是否属于置信集。本文建立网格的特定条件,使得存在一种调节机制可渐近复现置信集检验。这意味着在极限情况下,某个点被判定属于置信集当且仅当支持向量机将其标注为1。