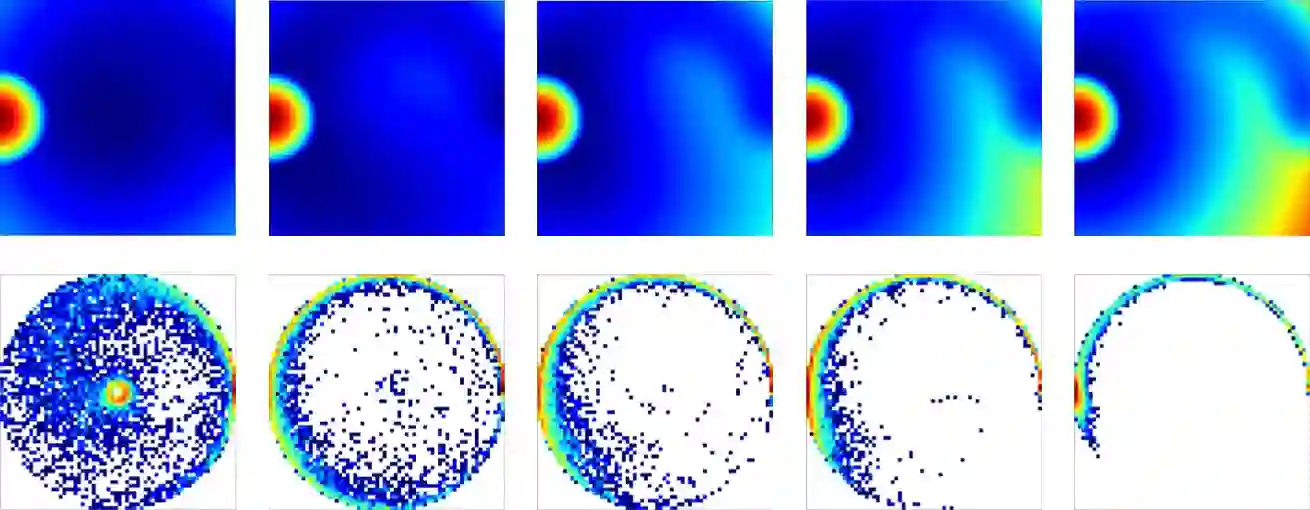
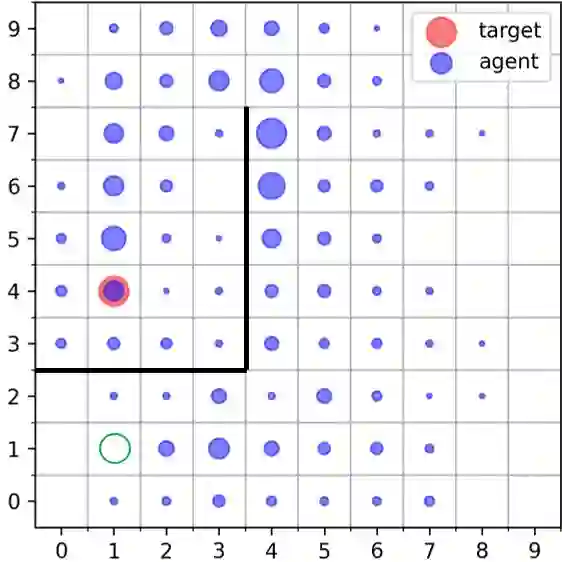
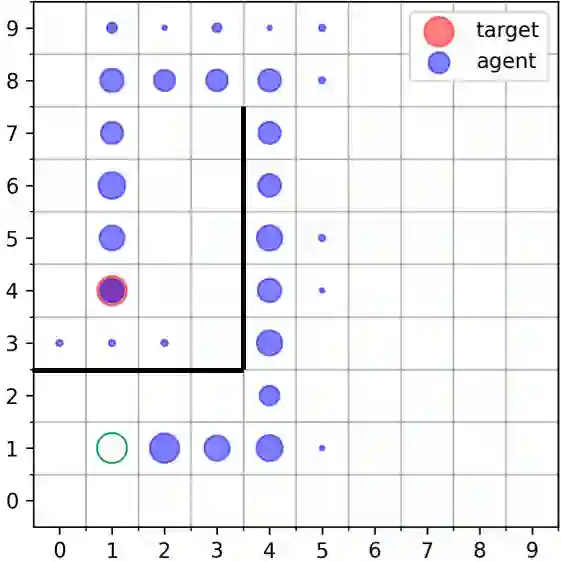
Goal-Conditioned Reinforcement Learning (RL) problems often have access to sparse rewards where the agent receives a reward signal only when it has achieved the goal, making policy optimization a difficult problem. Several works augment this sparse reward with a learned dense reward function, but this can lead to sub-optimal policies if the reward is misaligned. Moreover, recent works have demonstrated that effective shaping rewards for a particular problem can depend on the underlying learning algorithm. This paper introduces a novel way to encourage exploration called $f$-Policy Gradients, or $f$-PG. $f$-PG minimizes the f-divergence between the agent's state visitation distribution and the goal, which we show can lead to an optimal policy. We derive gradients for various f-divergences to optimize this objective. Our learning paradigm provides dense learning signals for exploration in sparse reward settings. We further introduce an entropy-regularized policy optimization objective, that we call $state$-MaxEnt RL (or $s$-MaxEnt RL) as a special case of our objective. We show that several metric-based shaping rewards like L2 can be used with $s$-MaxEnt RL, providing a common ground to study such metric-based shaping rewards with efficient exploration. We find that $f$-PG has better performance compared to standard policy gradient methods on a challenging gridworld as well as the Point Maze and FetchReach environments. More information on our website https://agarwalsiddhant10.github.io/projects/fpg.html.
翻译:目标条件强化学习问题通常面临稀疏奖励的挑战,智能体仅在达成目标时获得奖励信号,这使得策略优化变得困难。现有研究通过引入学习得到的稠密奖励函数来增强稀疏奖励,但若奖励函数存在偏差,可能导致次优策略。此外,近期研究表明,针对特定问题的有效塑形奖励可能取决于底层学习算法。本文提出一种新颖的探索方法——$f$-策略梯度($f$-PG)。$f$-PG通过最小化智能体状态访问分布与目标之间的f-散度,可推导出最优策略。我们针对多种f-散度推导了梯度以实现该目标优化。该学习范式在稀疏奖励场景中提供稠密的学习信号用于探索。我们进一步引入基于熵正则化的策略优化目标——状态最大熵强化学习($s$-MaxEnt RL),作为本文目标的一种特例。研究表明,L2等基于度量的塑形奖励可与$s$-MaxEnt RL结合使用,为这类度量型塑形奖励与高效探索的联合研究提供了统一框架。实验表明,在具有挑战性的网格世界、Point Maze以及FetchReach环境中,$f$-PG相比标准策略梯度方法具有更优性能。更多信息请访问我们的网站:https://agarwalsiddhant10.github.io/projects/fpg.html。