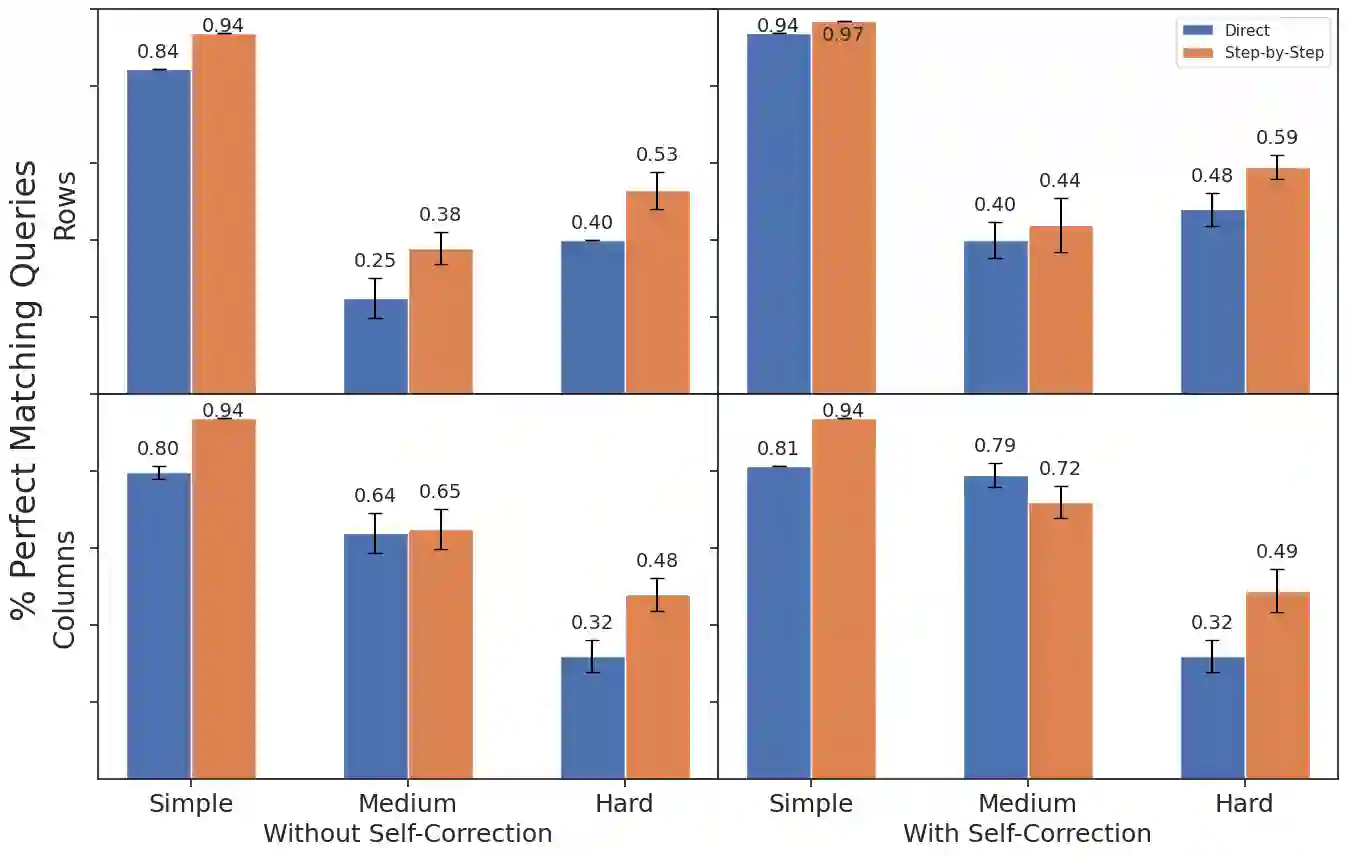
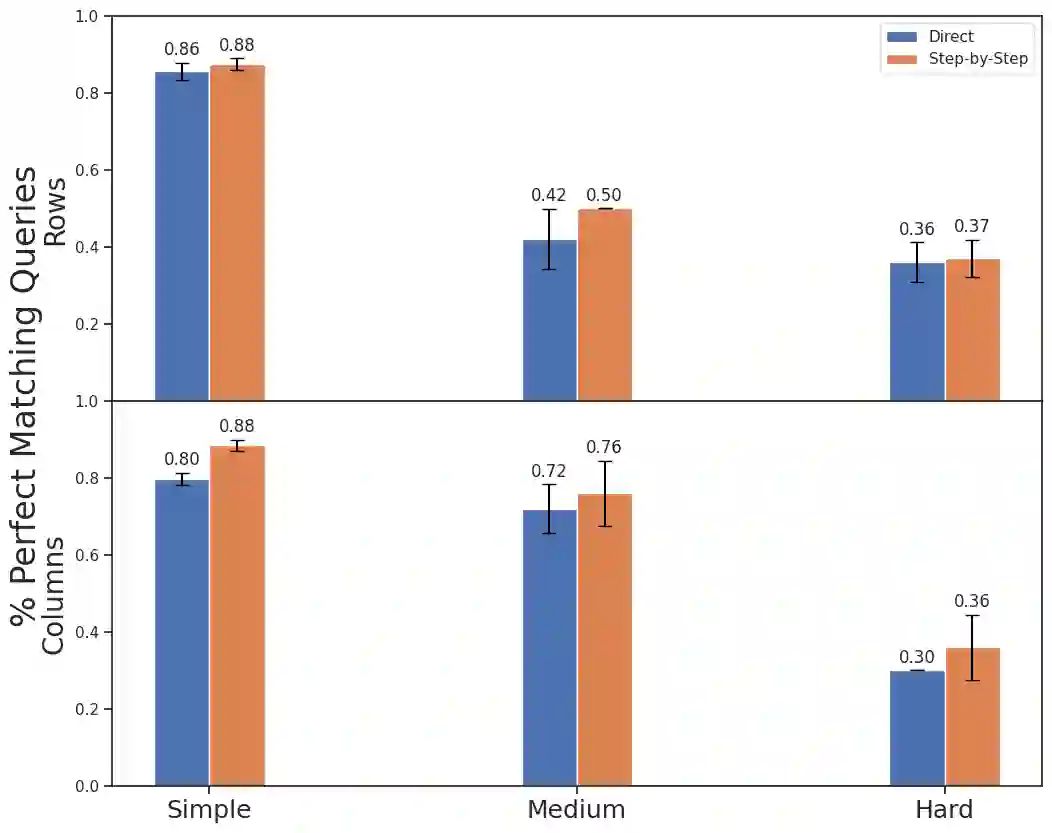
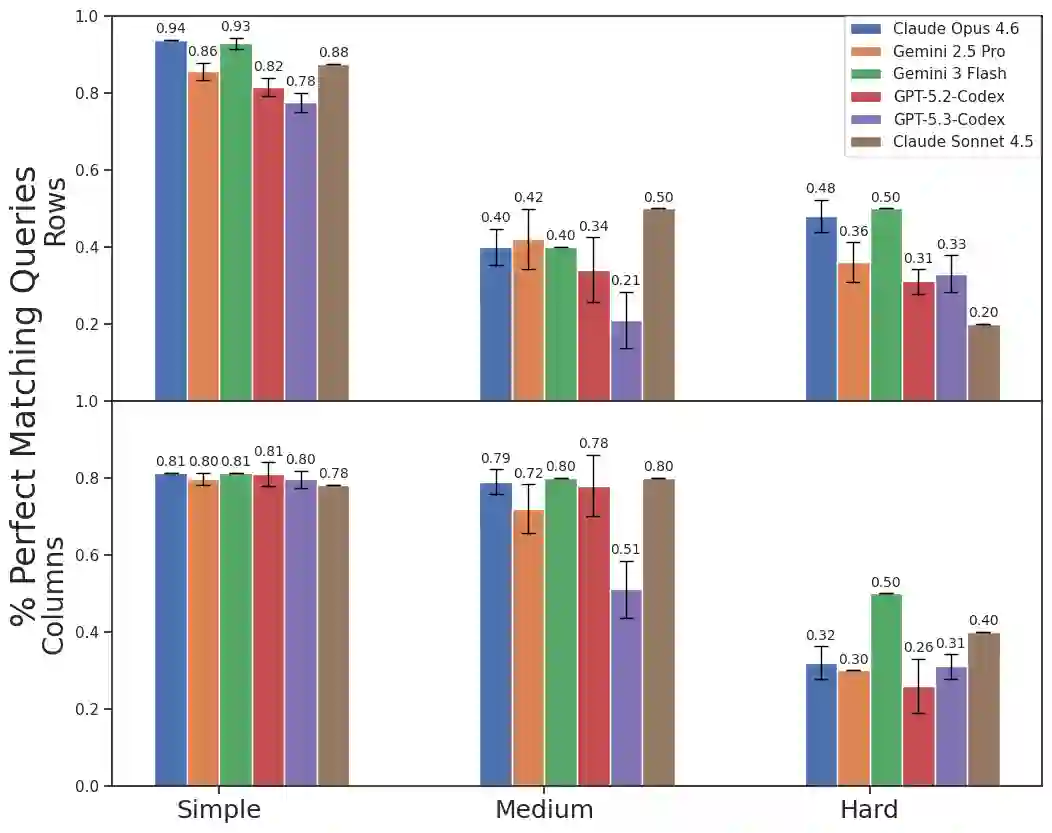
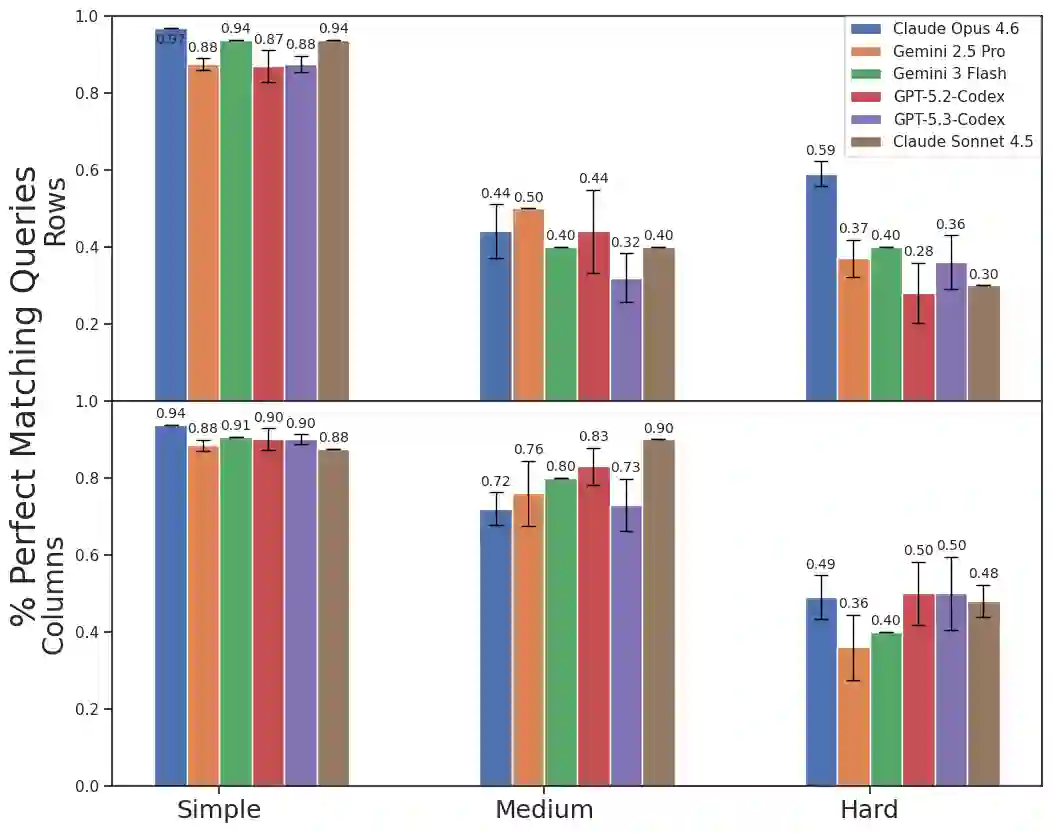
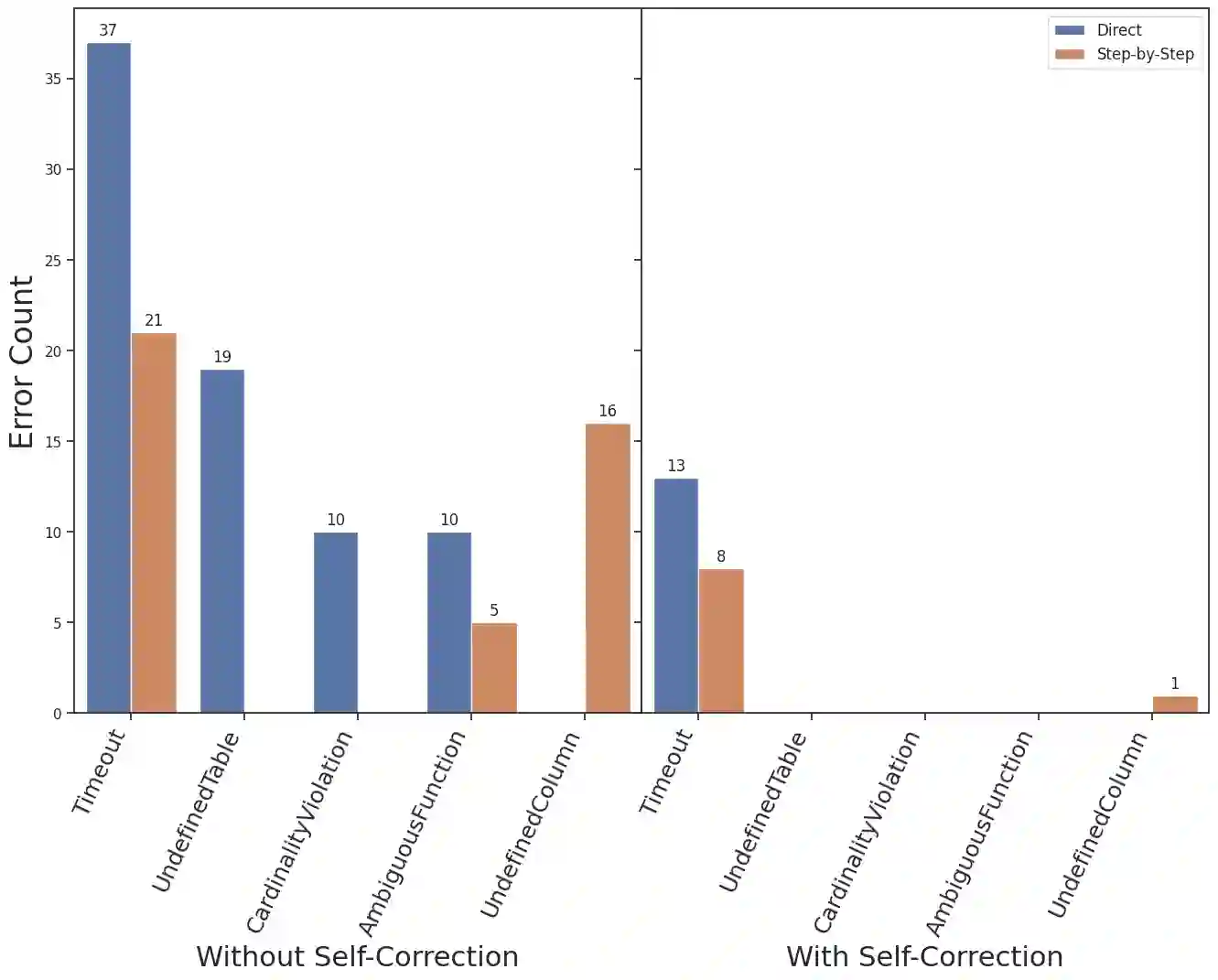
We develop a text-to-SQL (structured query language) system based on large language models (LLMs) using in-context learning and apply it to the Automatic Learning for the Rapid Classification of Events (ALeRCE) astronomical database. ALeRCE is a community broker for the Zwicky Transient Facility and the Vera C. Rubin Observatory. The system enables users to query the database in natural language (NL) and generates executable SQL queries. To develop and evaluate the system, we constructed a dataset of 110 NL/SQL pairs. We propose a step-by-step generation framework comprising four modules: schema linking, query classification, prompt decomposition, and self-correction. The performance of thirteen LLMs is evaluated using in-context learning and prompt engineering techniques. Text-to-SQL performance is assessed using the perfect-match (PM) rate for row identifiers (e.g., object identifiers) and column identifiers (i.e., column names). The proposed step-by-step framework consistently outperforms a direct-inference baseline, while the self-correction module consistently reduces execution errors. For Claude Opus 4.6, PM performance on row (column) identifiers is high for simple queries, reaching 0.97 (0.94), and decreases with query complexity to 0.44 (0.72) for medium queries and 0.59 (0.49) for hard queries. Among the thirteen evaluated models, the best-performing LLMs for the text-to-SQL task are Claude Opus 4.6, Gemini 2.5 Pro, Gemini 3 Flash, and GPT-5.2-Codex.
翻译:我们开发了一种基于大语言模型(LLMs)的文本转SQL(结构化查询语言)系统,采用上下文学习方法,并将其应用于ALeRCE(事件快速分类自动学习)天文数据库。ALeRCE是Zwicky暂现源巡天设施与Vera C. Rubin天文台的社区中介平台。该系统支持用户以自然语言查询数据库,并生成可执行的SQL查询语句。为开发评估该系统,我们构建了包含110对自然语言/SQL配对的数据集。提出包含四个模块的分步生成框架:模式链接、查询分类、提示分解与自我修正。采用上下文学习与提示工程技术对十三种大语言模型的性能进行评估。通过行标识符(如目标标识符)与列标识符(即列名)的完全匹配率衡量文本转SQL性能。所提出的分步框架在各方面均优于直接推理基线,而自我修正模块持续降低执行错误率。针对Claude Opus 4.6模型,简单查询的行(列)标识符完全匹配率达0.97(0.94),中等查询降至0.44(0.72),困难查询为0.59(0.49)。在十三种评估模型中,文本转SQL任务表现最佳的大语言模型为Claude Opus 4.6、Gemini 2.5 Pro、Gemini 3 Flash及GPT-5.2-Codex。