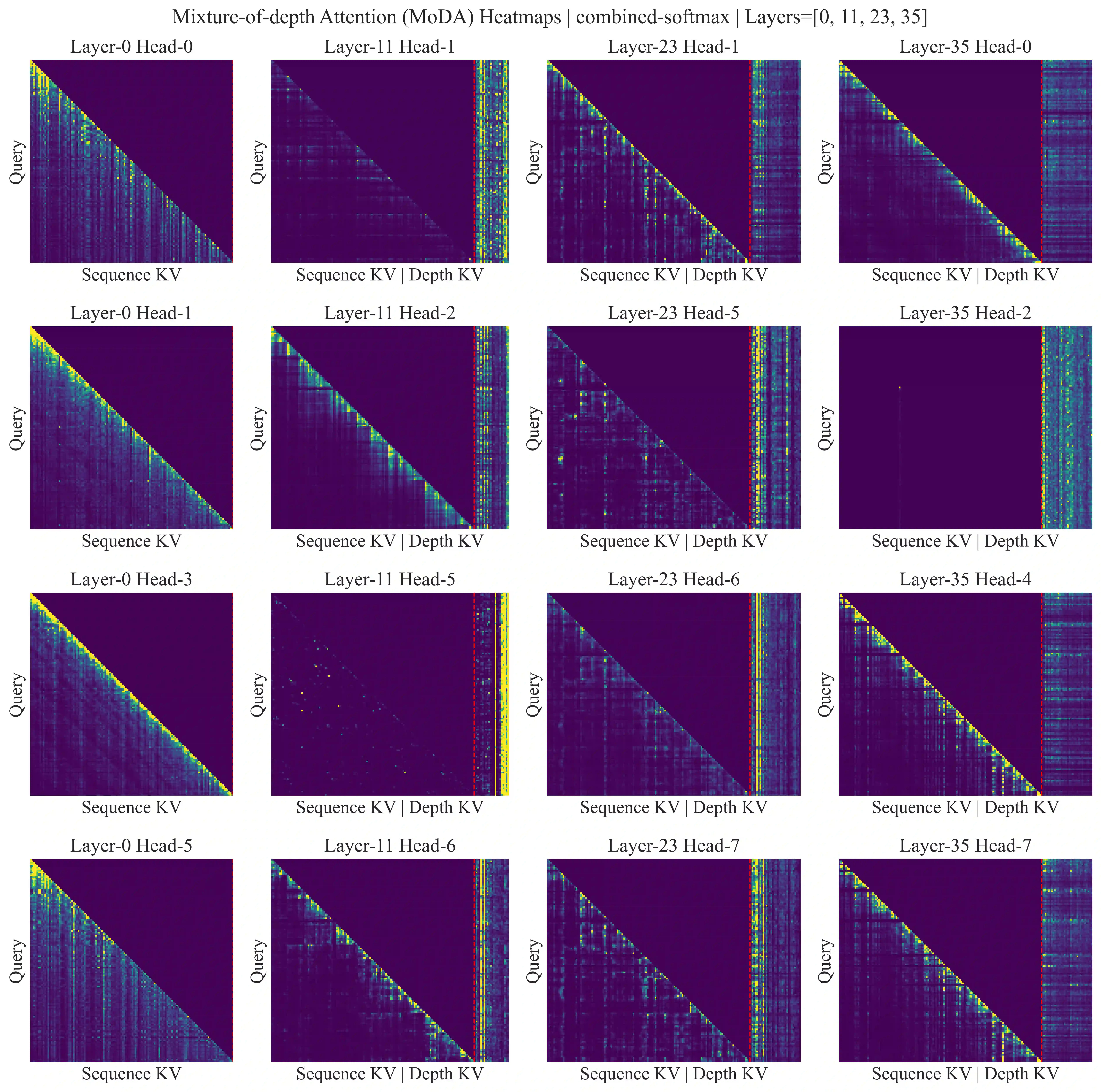
Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
翻译:增加深度是驱动大语言模型(LLM)发展的关键因素。然而,随着大语言模型变得更深,它们常常遭受信号退化问题:在浅层形成的具有信息量的特征,会因重复的残差更新而逐渐被稀释,使得这些特征在更深层中更难被恢复。我们提出了深度混合注意力机制(MoDA),该机制允许每个注意力头同时关注当前层的序列键值对以及来自前面各层的深度键值对。我们进一步描述了一种硬件高效的MoDA算法,该算法解决了非连续内存访问模式的问题,在序列长度为64K时达到了FlashAttention-2 97.3%的效率。在15亿参数模型上的实验表明,MoDA始终优于强基线模型。值得注意的是,它在10个验证基准测试中平均困惑度降低了0.2,在10个下游任务上平均性能提升了2.11%,而计算开销仅增加了微不足道的3.7% FLOPs。我们还发现,将MoDA与后归一化结合使用,比将其与前归一化结合能获得更好的性能。这些结果表明,MoDA是一种有前景的深度扩展基础组件。代码发布于 https://github.com/hustvl/MoDA。