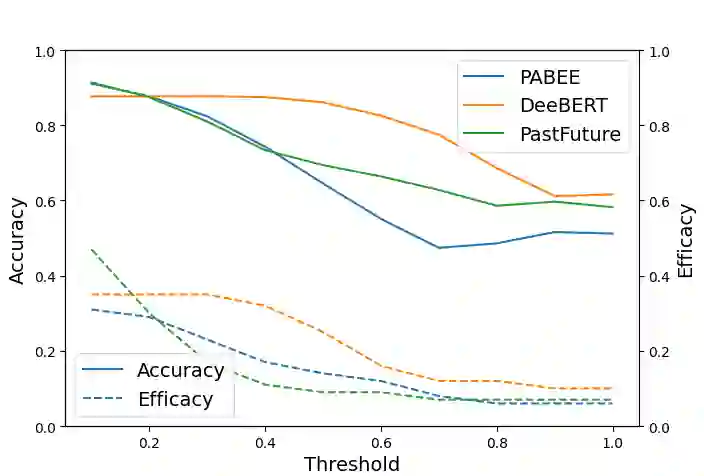
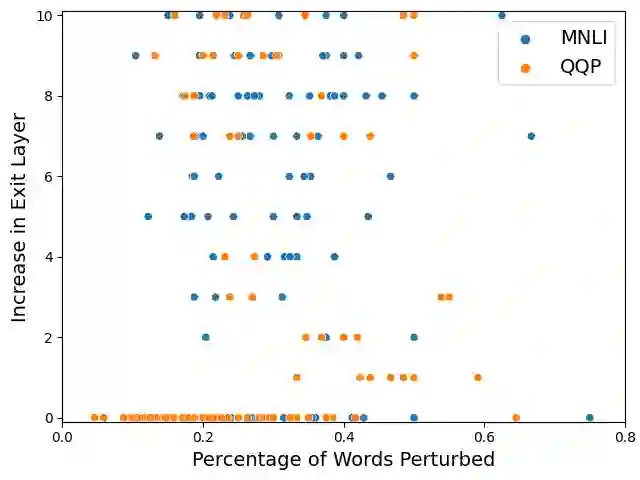
In this paper, we systematically evaluate the robustness of multi-exit language models against adversarial slowdown. To audit their robustness, we design a slowdown attack that generates natural adversarial text bypassing early-exit points. We use the resulting WAFFLE attack as a vehicle to conduct a comprehensive evaluation of three multi-exit mechanisms with the GLUE benchmark against adversarial slowdown. We then show our attack significantly reduces the computational savings provided by the three methods in both white-box and black-box settings. The more complex a mechanism is, the more vulnerable it is to adversarial slowdown. We also perform a linguistic analysis of the perturbed text inputs, identifying common perturbation patterns that our attack generates, and comparing them with standard adversarial text attacks. Moreover, we show that adversarial training is ineffective in defeating our slowdown attack, but input sanitization with a conversational model, e.g., ChatGPT, can remove perturbations effectively. This result suggests that future work is needed for developing efficient yet robust multi-exit models. Our code is available at: https://github.com/ztcoalson/WAFFLE
翻译:本文系统评估了多出口语言模型在对抗性减速下的鲁棒性。为检验其鲁棒性,我们设计了一种减速攻击,通过生成绕过早期出口点的自然对抗文本来实现。我们以所提出的WAFFLE攻击作为工具,结合GLUE基准对三种多出口机制在对抗性减速下的表现进行了全面评估。研究表明,该攻击在白盒与黑盒场景下均显著降低了三种方法所带来的计算节省。机制越复杂,其对对抗性减速的脆弱性越高。此外,我们对扰动文本输入进行了语言学分析,识别出攻击生成的常见扰动模式,并将其与标准对抗文本攻击进行对比。进一步实验表明,对抗训练无法有效抵御我们的减速攻击,但通过对话模型(如ChatGPT)进行输入净化可有效消除扰动。这一结果表明,未来需针对开发高效且鲁棒的多出口模型开展深入研究。我们的代码开源于:https://github.com/ztcoalson/WAFFLE