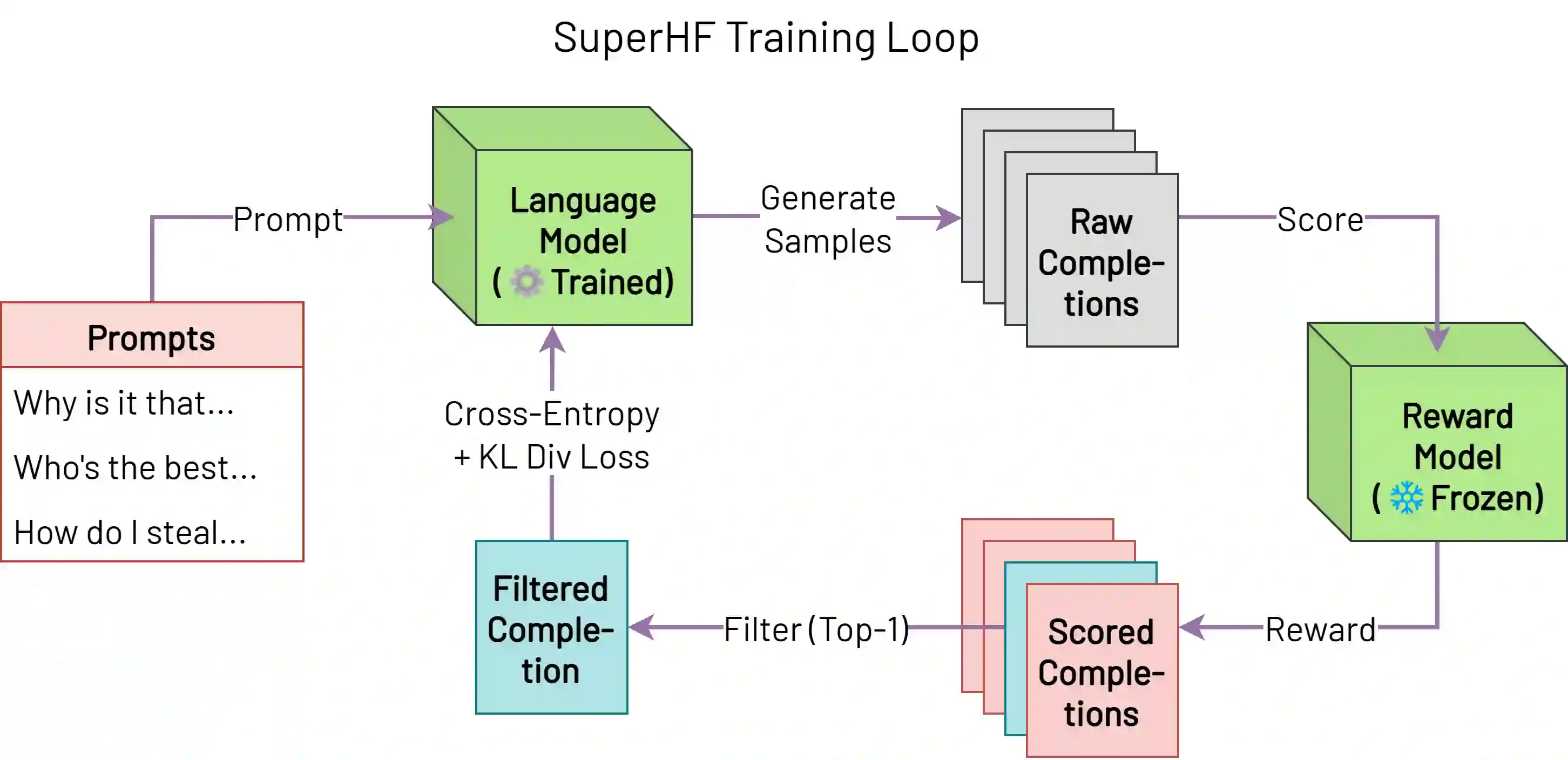
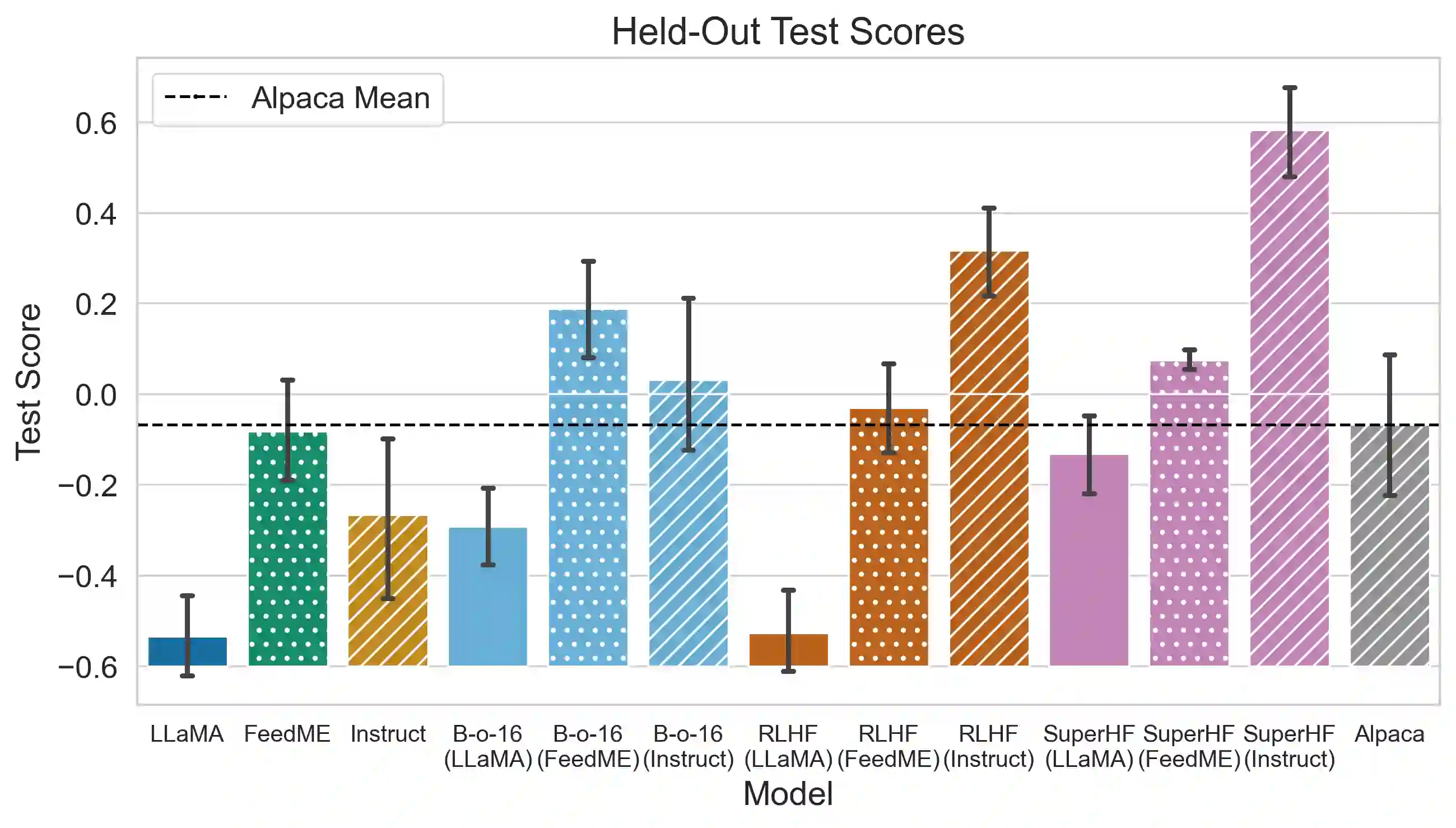
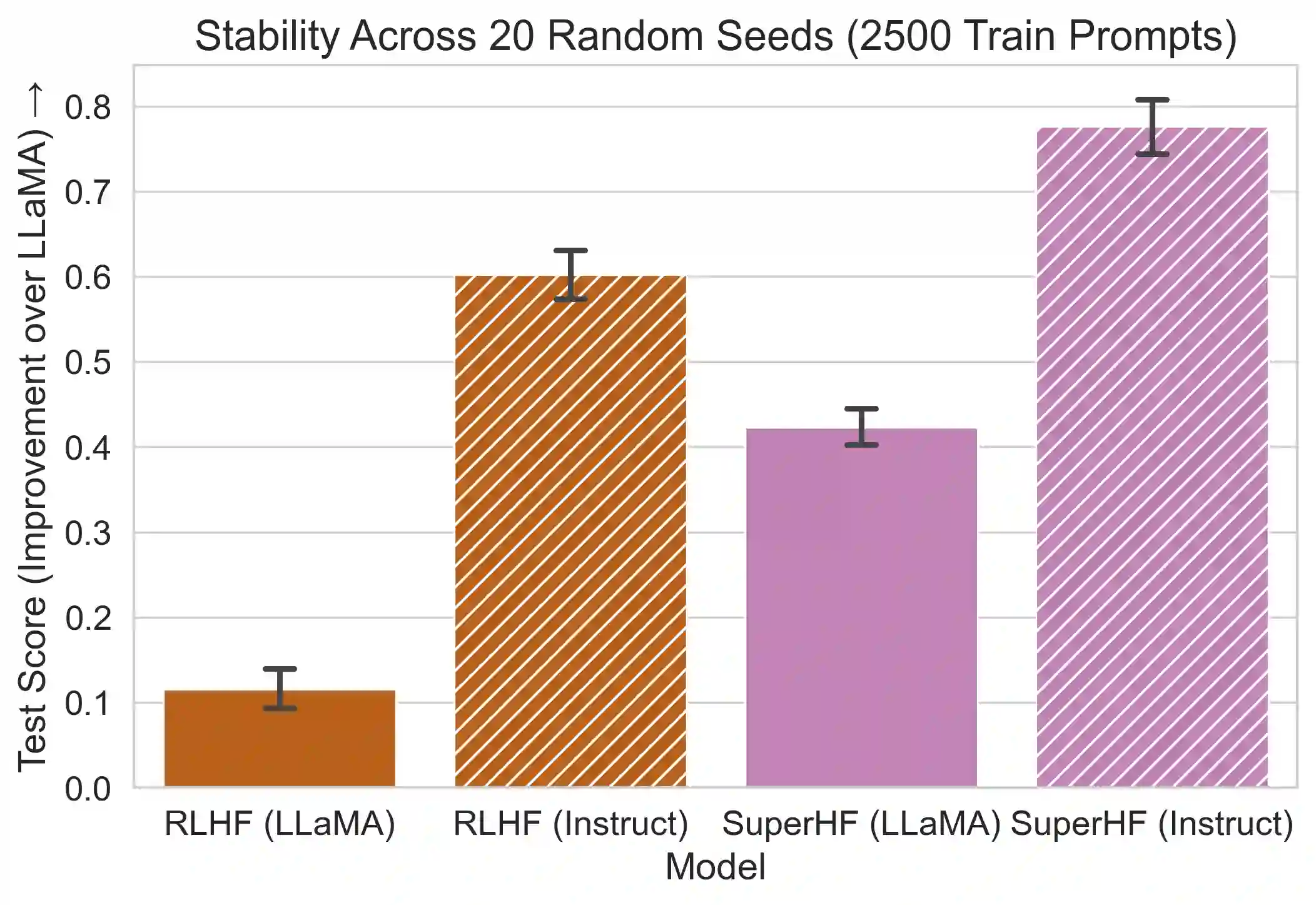
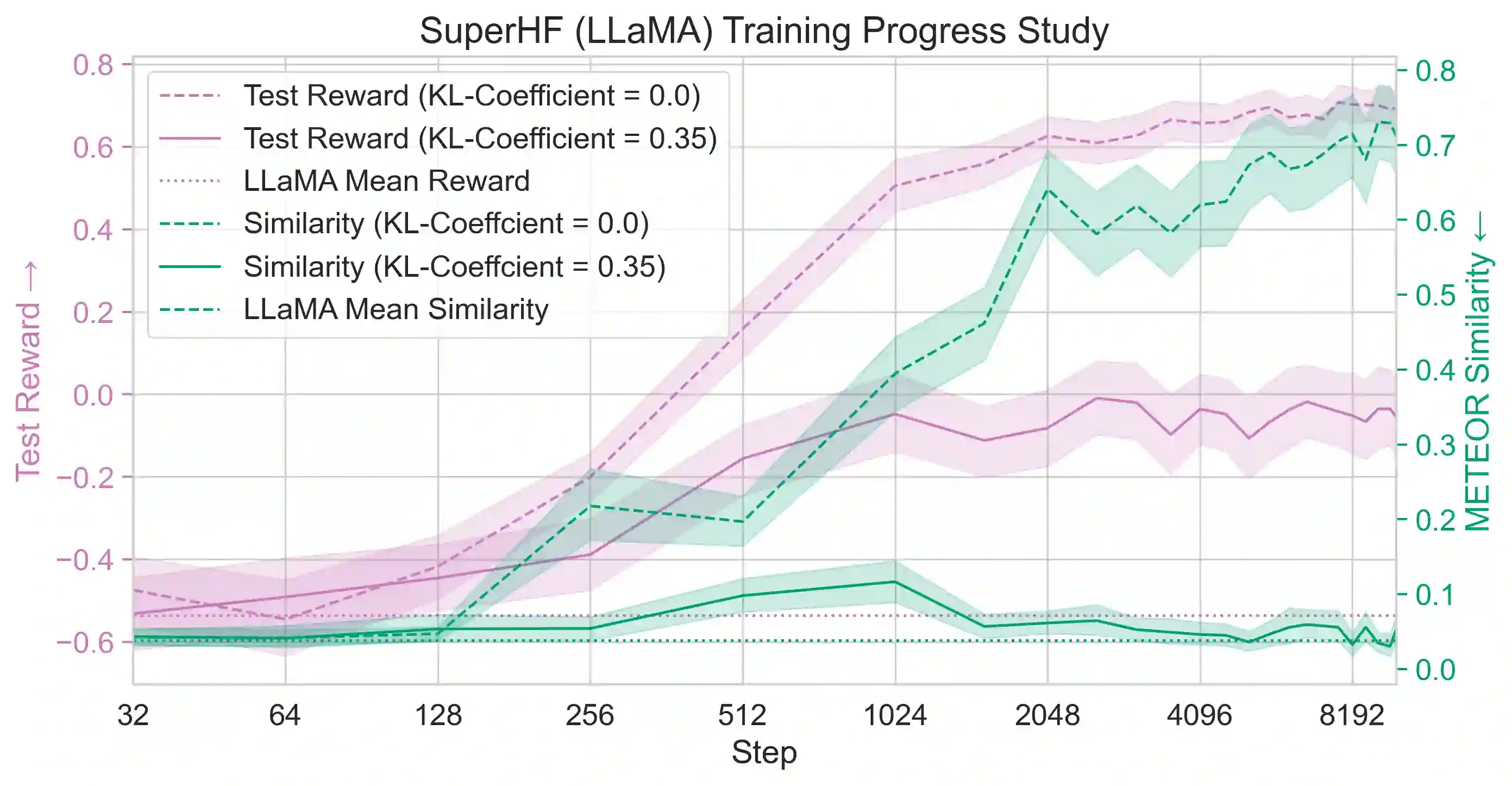
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
翻译:虽然大型语言模型展现出卓越能力,但在安全性、与人类价值观的一致性以及训练稳定性方面仍存在挑战。本文聚焦于两种主流的模型对齐方法:监督式微调(SFT)和基于人类反馈的强化学习(RLHF)。SFT简单稳健,驱动着众多开源模型;而RLHF虽被ChatGPT等顶级模型采用,却存在训练不稳定和易受奖励破解影响的缺陷。我们提出新型方法——监督式人类反馈迭代学习(SuperHF),旨在融合两者优势。我们的双重假设是:RLHF中使用的奖励模型对高效数据利用和模型泛化至关重要,而PPO算法可能并非必要且会加剧不稳定问题。SuperHF用简单的监督损失和KL散度先验替代PPO,通过在线学习机制反复采样模型输出批次并经由奖励模型筛选,自主生成训练数据。我们将奖励优化问题分解为三个核心要素:稳健优化训练奖励本身、通过新型METEOR相似度指标抑制因奖励模型破解导致的性能退化、保持下游评估的优异表现。实验结果表明,SuperHF在训练目标上超越基于PPO的RLHF,能轻松实现高奖励与低奖励破解的平衡优化,改善下游校准性能,并在基于GPT-4的定性评估中表现持平,同时实现难度显著降低,凸显其作为竞争性语言模型对齐技术的潜力。