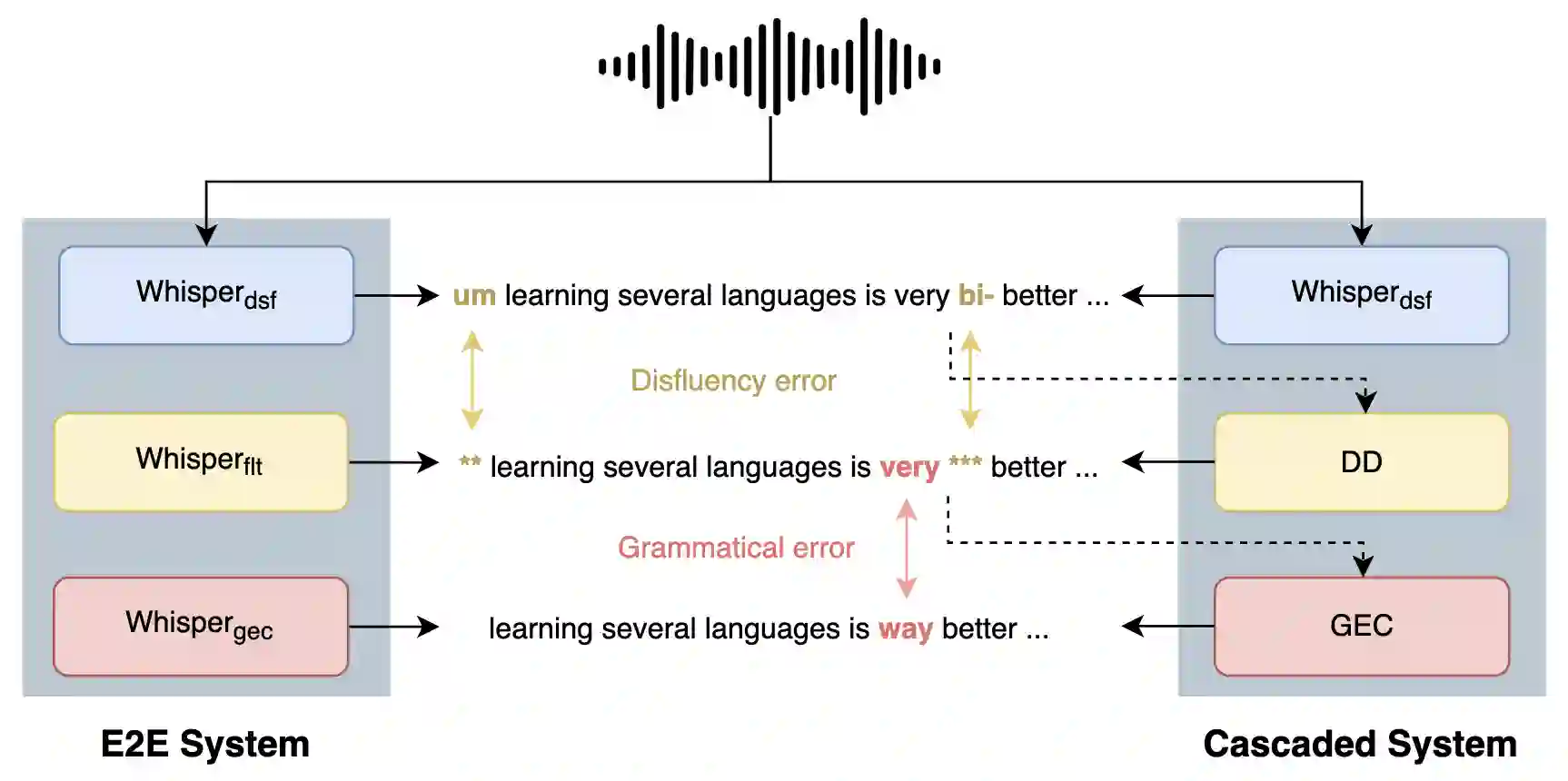
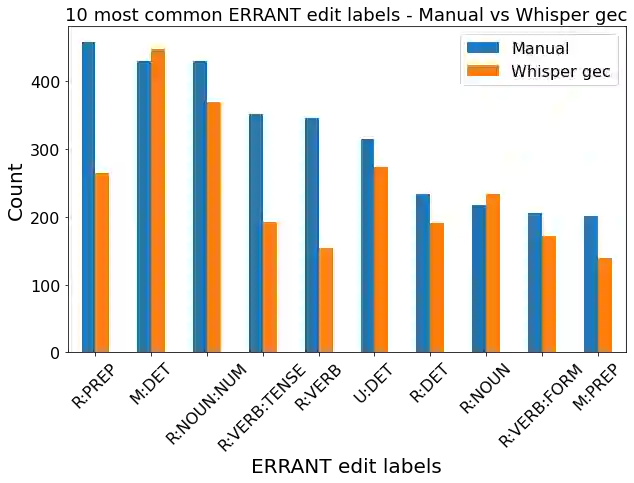
Grammatical feedback is crucial for L2 learners, teachers, and testers. Spoken grammatical error correction (GEC) aims to supply feedback to L2 learners on their use of grammar when speaking. This process usually relies on a cascaded pipeline comprising an ASR system, disfluency removal, and GEC, with the associated concern of propagating errors between these individual modules. In this paper, we introduce an alternative "end-to-end" approach to spoken GEC, exploiting a speech recognition foundation model, Whisper. This foundation model can be used to replace the whole framework or part of it, e.g., ASR and disfluency removal. These end-to-end approaches are compared to more standard cascaded approaches on the data obtained from a free-speaking spoken language assessment test, Linguaskill. Results demonstrate that end-to-end spoken GEC is possible within this architecture, but the lack of available data limits current performance compared to a system using large quantities of text-based GEC data. Conversely, end-to-end disfluency detection and removal, which is easier for the attention-based Whisper to learn, does outperform cascaded approaches. Additionally, the paper discusses the challenges of providing feedback to candidates when using end-to-end systems for spoken GEC.
翻译:语法反馈对第二语言学习者、教师及测试者至关重要。口语语法错误纠正旨在为第二语言学习者在口语表达中的语法使用提供反馈。传统方法通常依赖由自动语音识别(ASR)系统、非流利性移除和语法错误纠正组成的级联流水线,但这存在各模块间错误传播的问题。本文提出一种替代性的“端到端”口语语法错误纠正方法,利用语音识别基础模型Whisper。该基础模型可替代整个框架或部分模块(如ASR和非流利性移除)。我们将这些端到端方法与更标准的级联方法在自由口语语言评估测试Linguaskill的数据上进行对比。结果表明,端到端口语语法错误纠正在此架构下具备可行性,但当前可用数据的不足限制了其性能,使其不及使用大量文本语法错误纠正数据的系统。相反,基于注意力的Whisper更易学习的端到端非流利性检测与移除方法,其性能确实优于级联方法。此外,本文还探讨了使用端到端系统为考生提供语法错误纠正反馈时所面临的挑战。