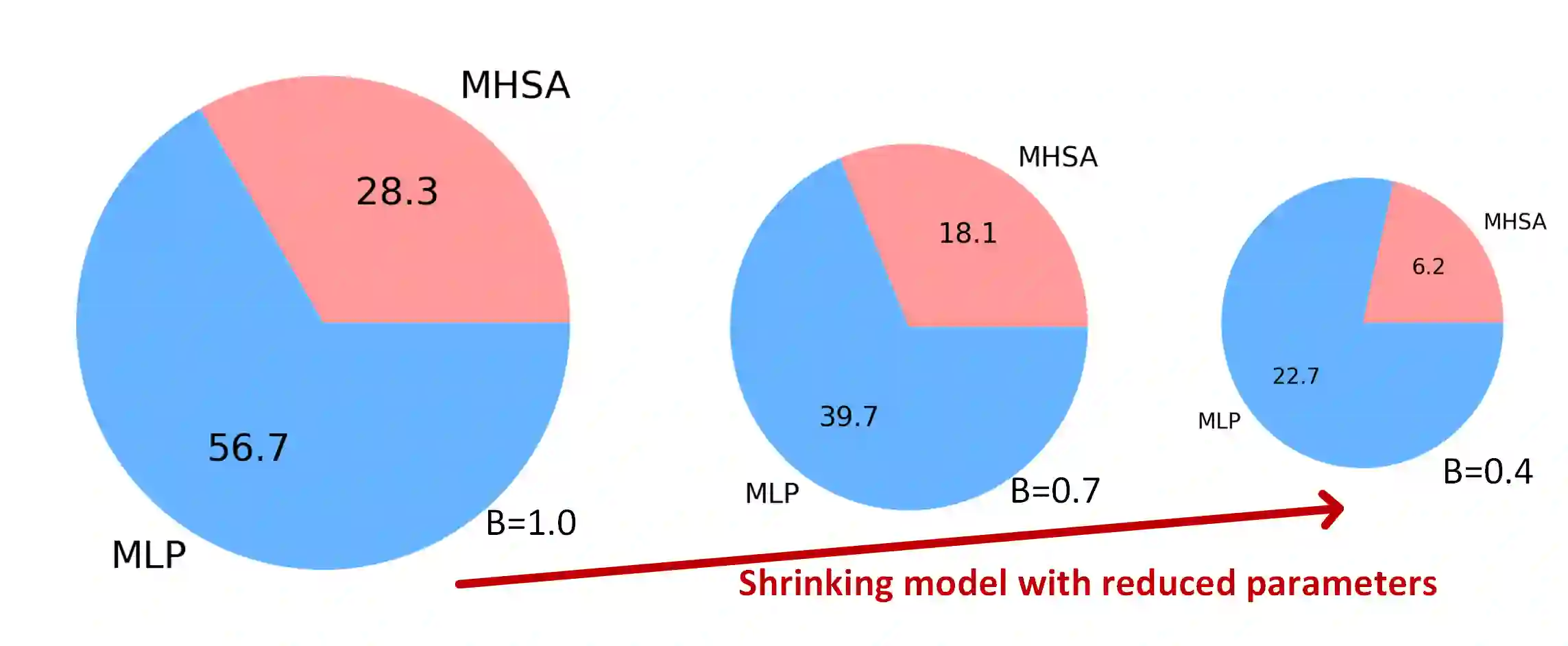
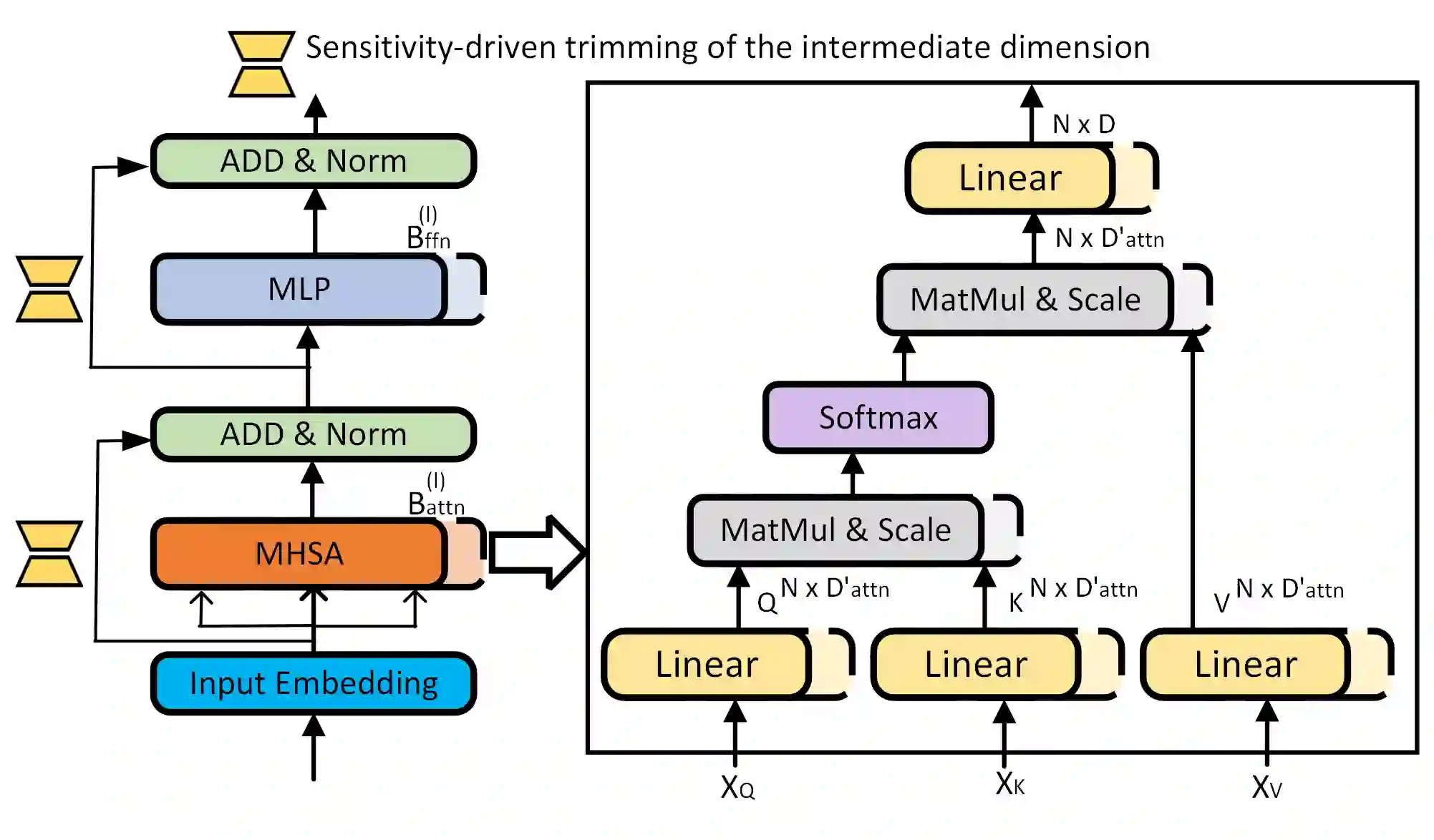
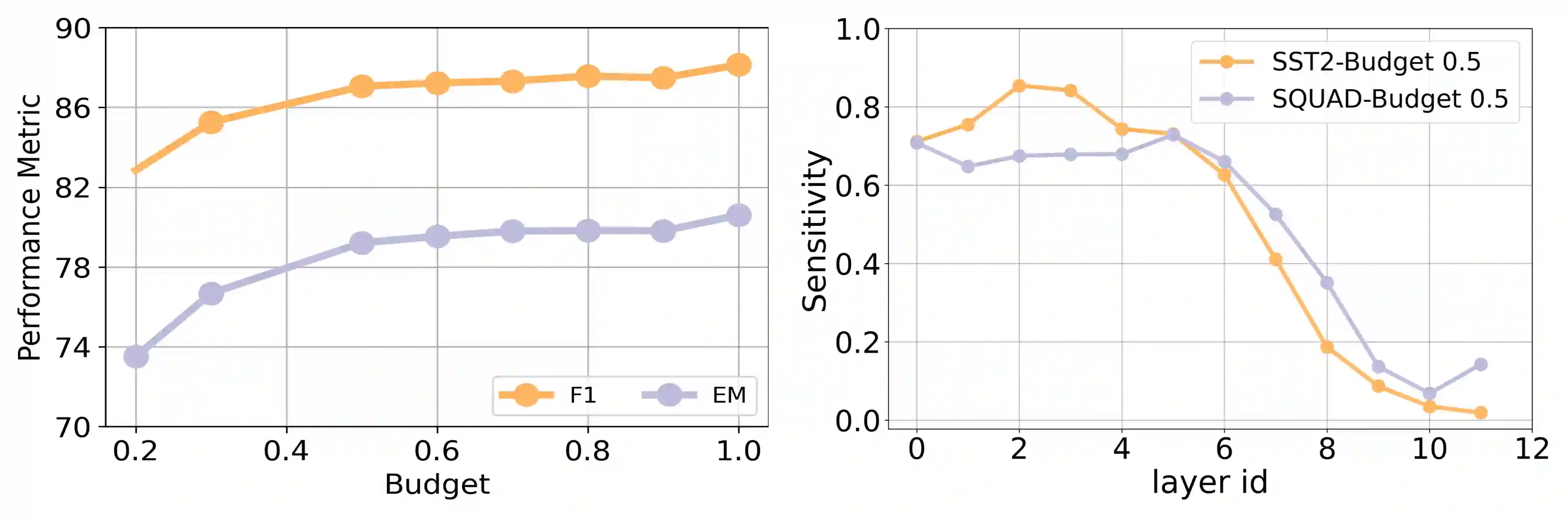
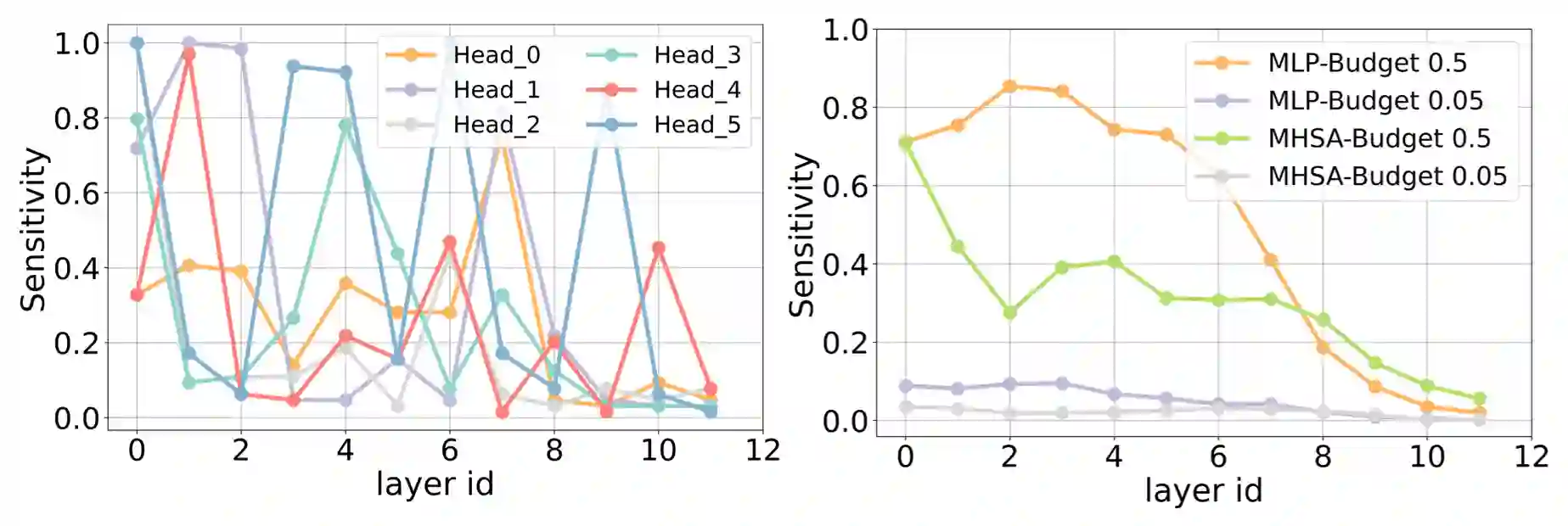
Large pre-trained language models have recently gained significant traction due to their improved performance on various down-stream tasks like text classification and question answering, requiring only few epochs of fine-tuning. However, their large model sizes often prohibit their applications on resource-constrained edge devices. Existing solutions of yielding parameter-efficient BERT models largely rely on compute-exhaustive training and fine-tuning. Moreover, they often rely on additional compute heavy models to mitigate the performance gap. In this paper, we present Sensi-BERT, a sensitivity driven efficient fine-tuning of BERT models that can take an off-the-shelf pre-trained BERT model and yield highly parameter-efficient models for downstream tasks. In particular, we perform sensitivity analysis to rank each individual parameter tensor, that then is used to trim them accordingly during fine-tuning for a given parameter or FLOPs budget. Our experiments show the efficacy of Sensi-BERT across different downstream tasks including MNLI, QQP, QNLI, SST-2 and SQuAD, showing better performance at similar or smaller parameter budget compared to various alternatives.
翻译:大规模预训练语言模型因其在文本分类、问答等下游任务中仅需少量微调轮次即可提升性能而受到广泛关注。然而,其庞大的模型规模往往阻碍其在资源受限的边缘设备上的应用。现有参数高效BERT模型的解决方案主要依赖计算密集型训练与微调,且常需额外的高计算量模型来弥补性能差距。本文提出Sensi-BERT,一种通过敏感性驱动的高效微调方法,可直接利用现成预训练BERT模型生成高参数效率的下游任务模型。具体而言,我们通过敏感性分析对每个参数张量进行排序,在给定参数或FLOPs预算下,利用排序结果在微调过程中进行相应裁剪。实验表明,Sensi-BERT在MNLI、QQP、QNLI、SST-2和SQuAD等多个下游任务中均展现出有效性,在相同或更小参数预算下相比多种替代方法取得了更优性能。