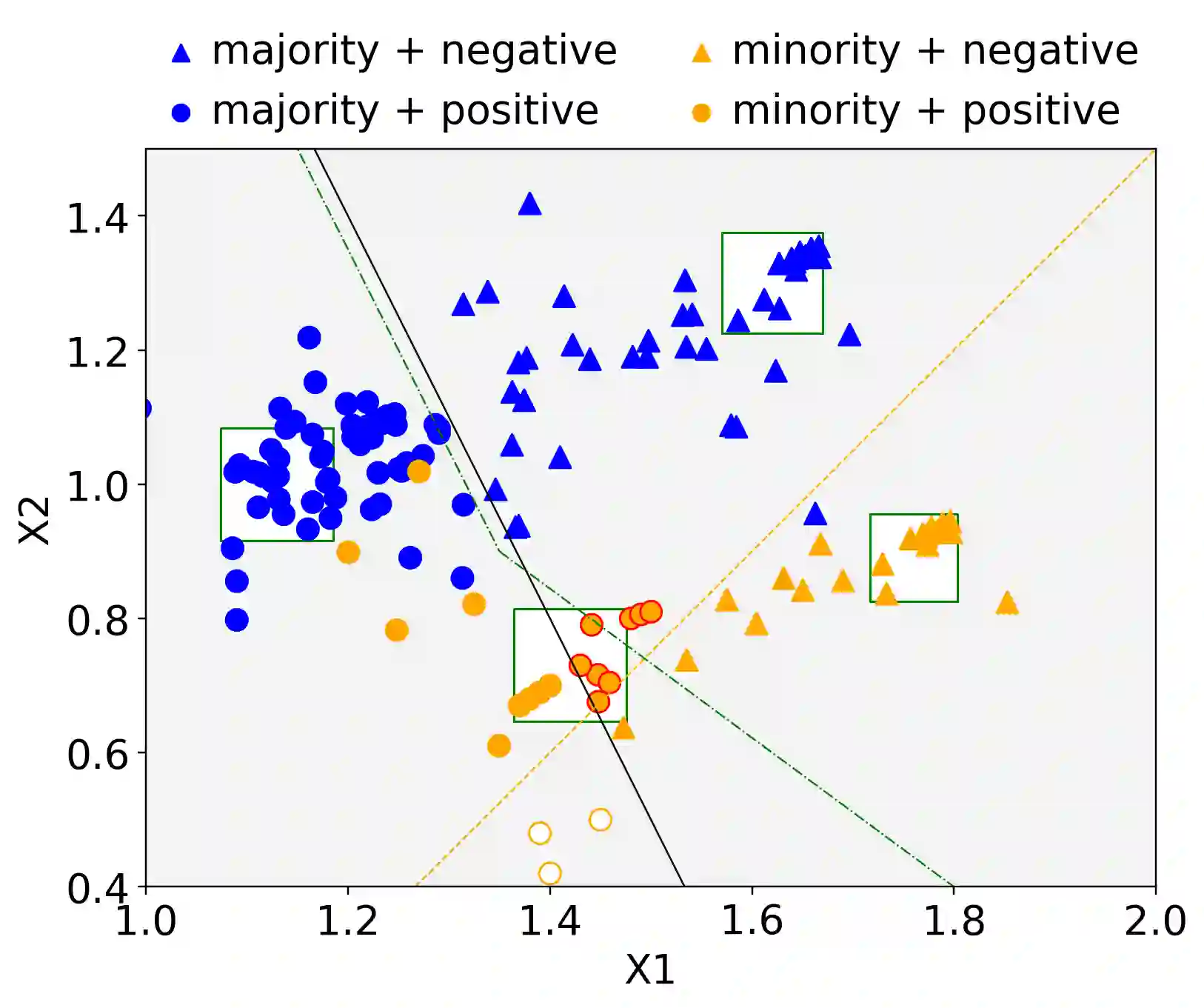
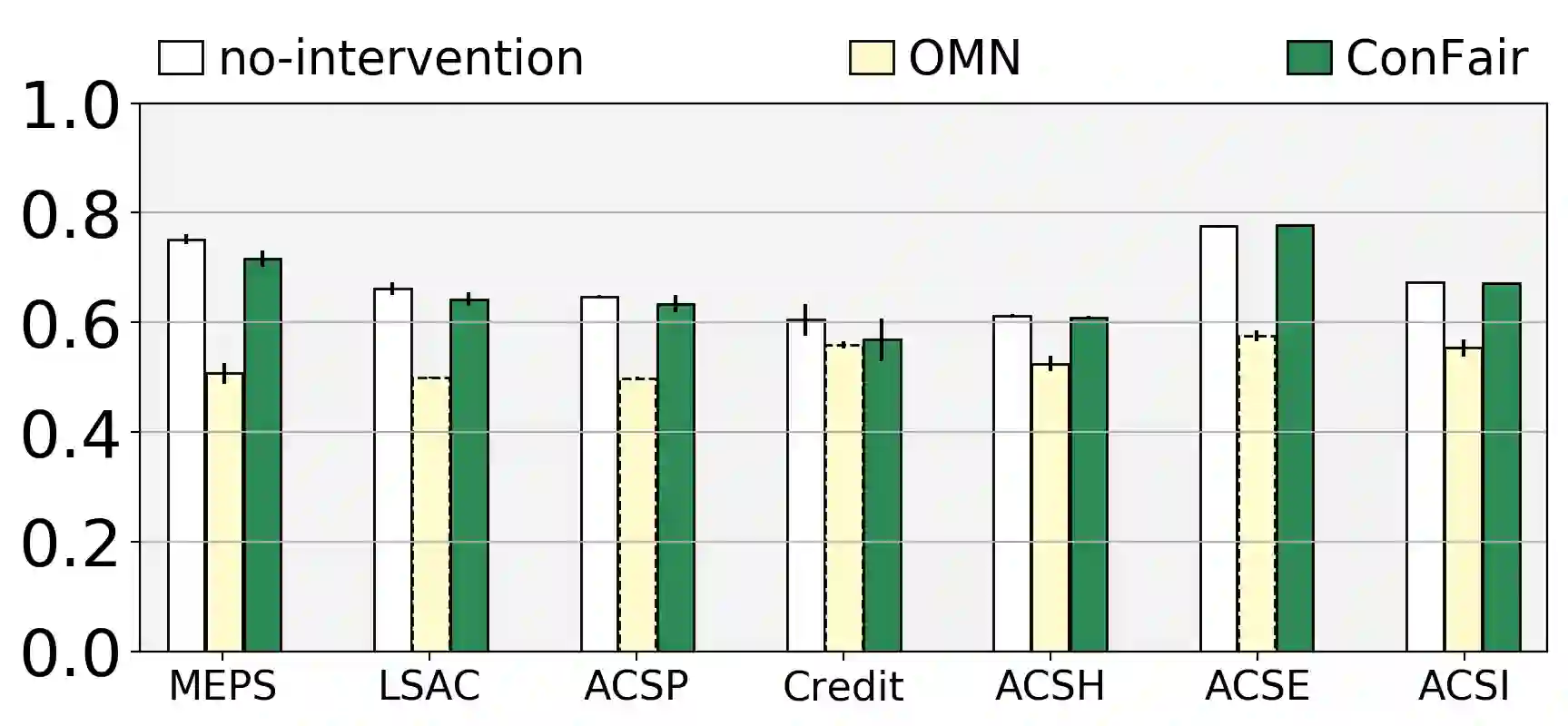
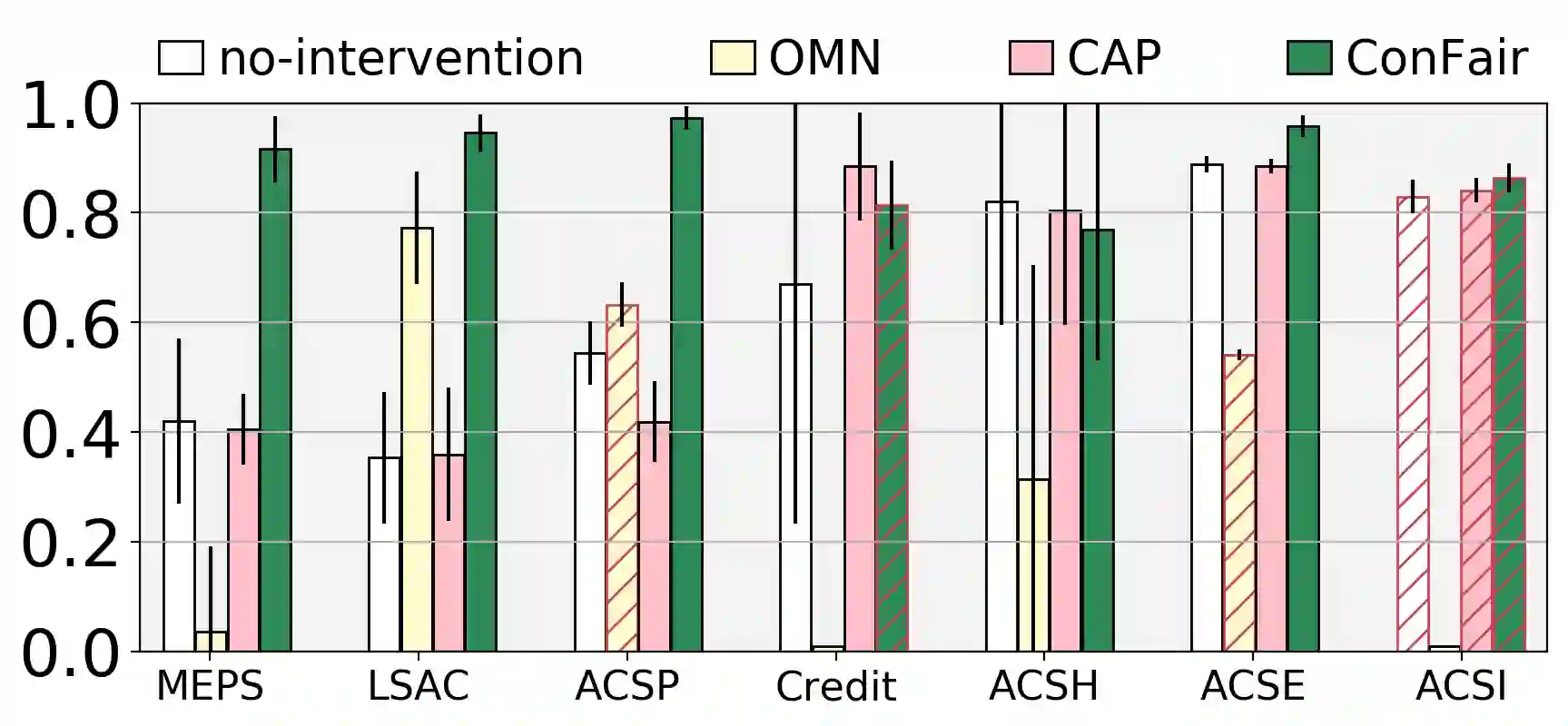
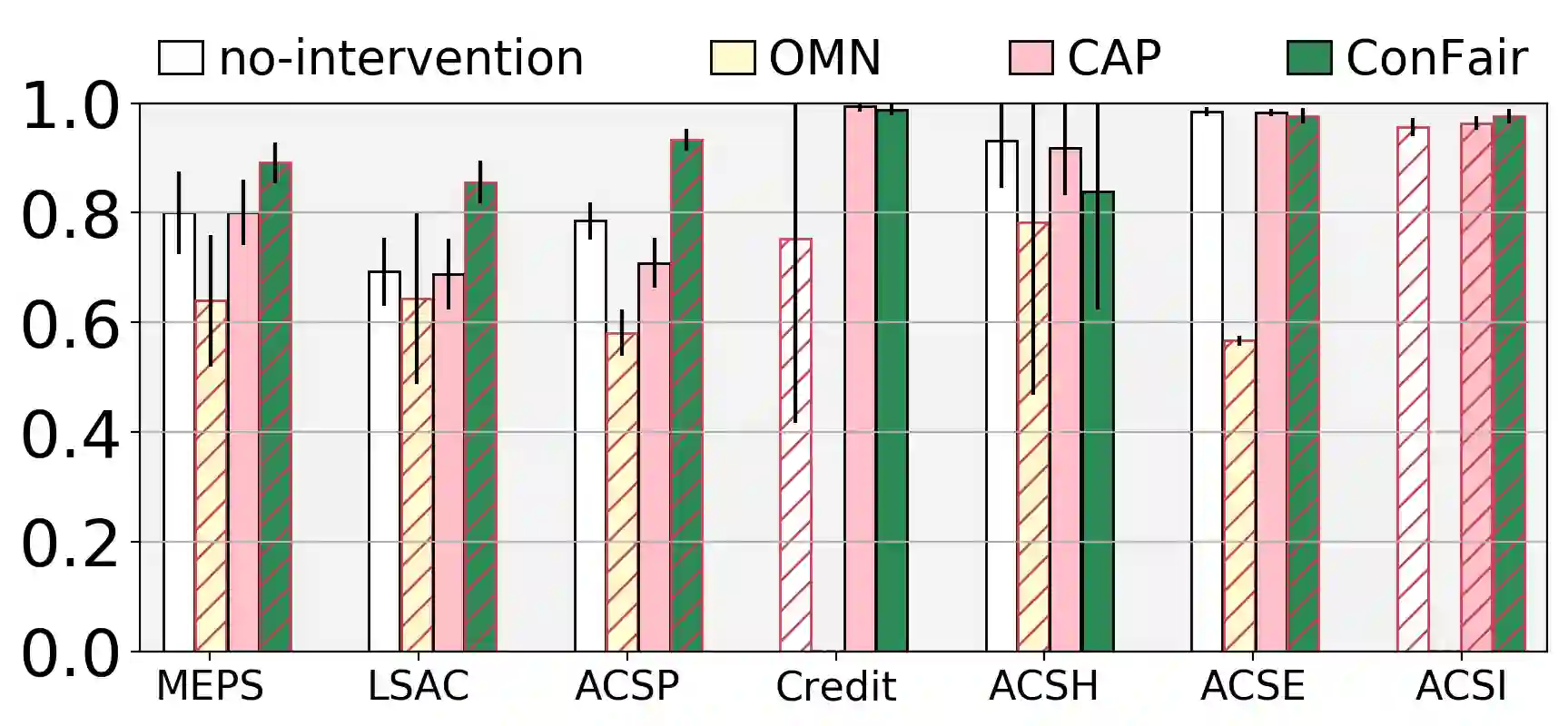
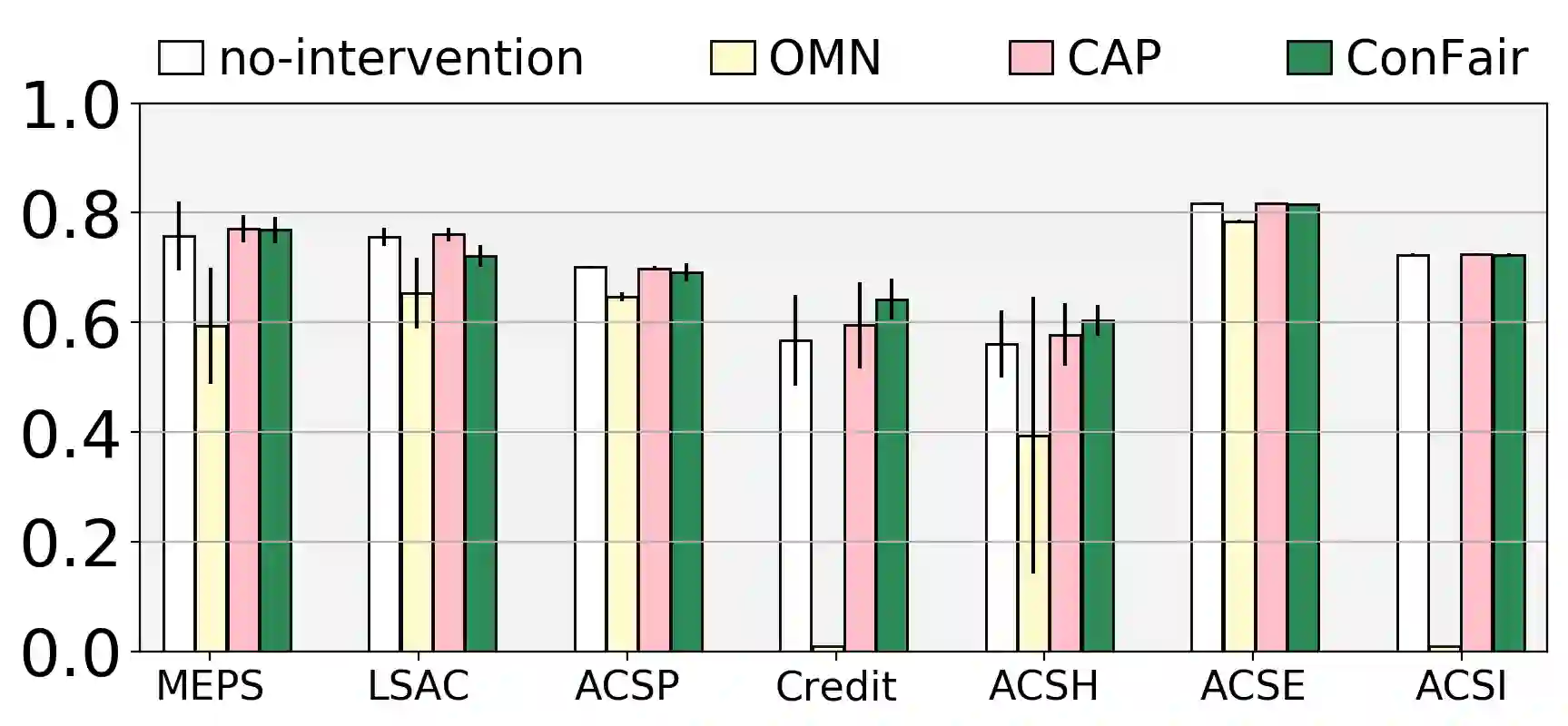
Machine Learning (ML) models are widely employed to drive many modern data systems. While they are undeniably powerful tools, ML models often demonstrate imbalanced performance and unfair behaviors. The root of this problem often lies in the fact that different subpopulations commonly display divergent trends: as a learning algorithm tries to identify trends in the data, it naturally favors the trends of the majority groups, leading to a model that performs poorly and unfairly for minority populations. Our goal is to improve the fairness and trustworthiness of ML models by applying only non-invasive interventions, i.e., without altering the data or the learning algorithm. We use a simple but key insight: the divergence of trends between different populations, and, consecutively, between a learned model and minority populations, is analogous to data drift, which indicates the poor conformance between parts of the data and the trained model. We explore two strategies (model-splitting and reweighing) to resolve this drift, aiming to improve the overall conformance of models to the underlying data. Both our methods introduce novel ways to employ the recently-proposed data profiling primitive of Conformance Constraints. Our experimental evaluation over 7 real-world datasets shows that both DifFair and ConFair improve the fairness of ML models.
翻译:机器学习(ML)模型被广泛用于驱动众多现代数据系统。尽管它们无疑是强大的工具,但ML模型常表现出性能失衡与不公平行为。这一问题的根源通常在于不同子群体普遍呈现趋势差异:当学习算法试图识别数据中的趋势时,它会天然地偏向多数群体的趋势,导致模型对少数群体性能低下且不公平。我们的目标是仅通过非侵入式干预(即不改变数据或学习算法)来提升ML模型的公平性与可信度。我们利用一个简单但关键的见解:不同群体之间的趋势差异,以及由此产生的已学习模型与少数群体之间的趋势差异,类似于数据漂移——这体现了数据部分与训练模型之间的低吻合度。我们探索了两种策略(模型拆分与重加权)来消除这种漂移,旨在提升模型对底层数据的整体吻合度。两种方法均引入了新方式,以应用近期提出的数据概要分析原语——一致性约束。我们在7个真实数据集上的实验评估表明,DifFair和ConFair均能改善ML模型的公平性。