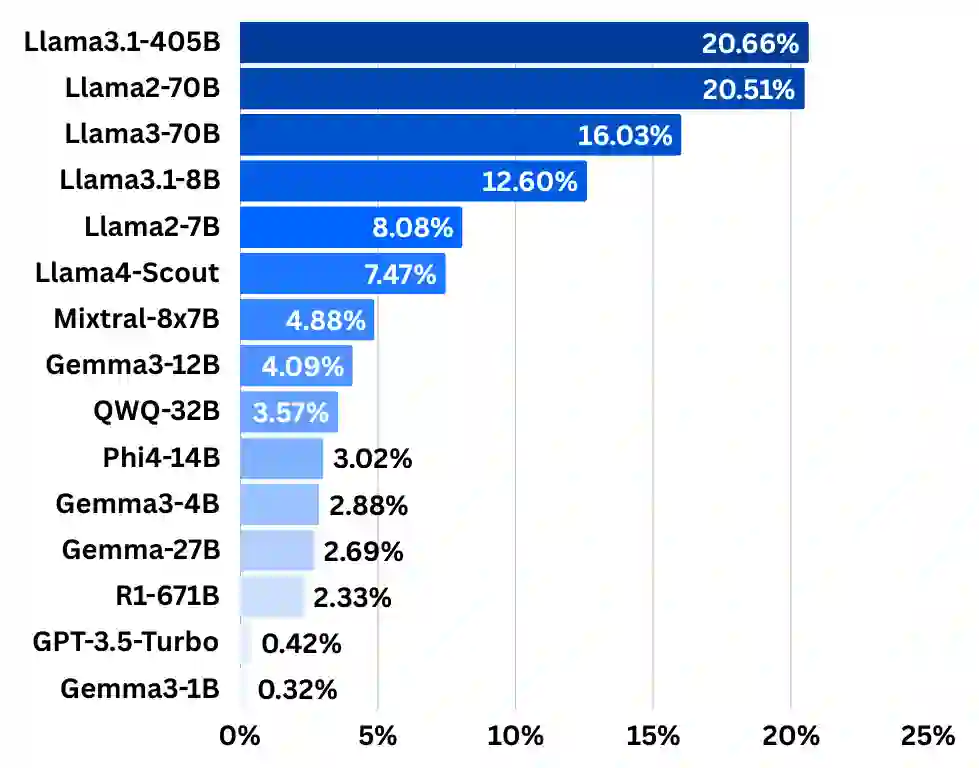
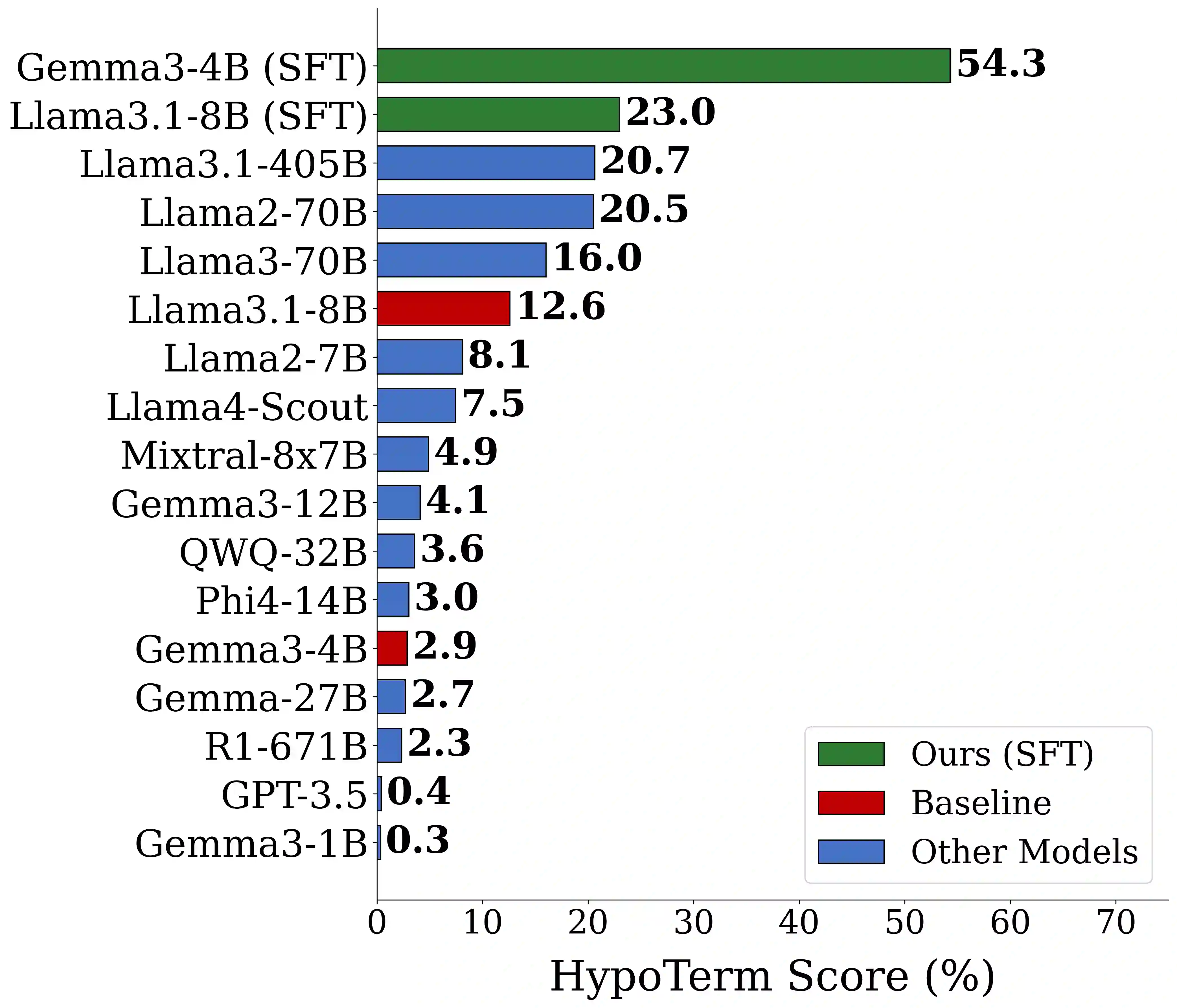
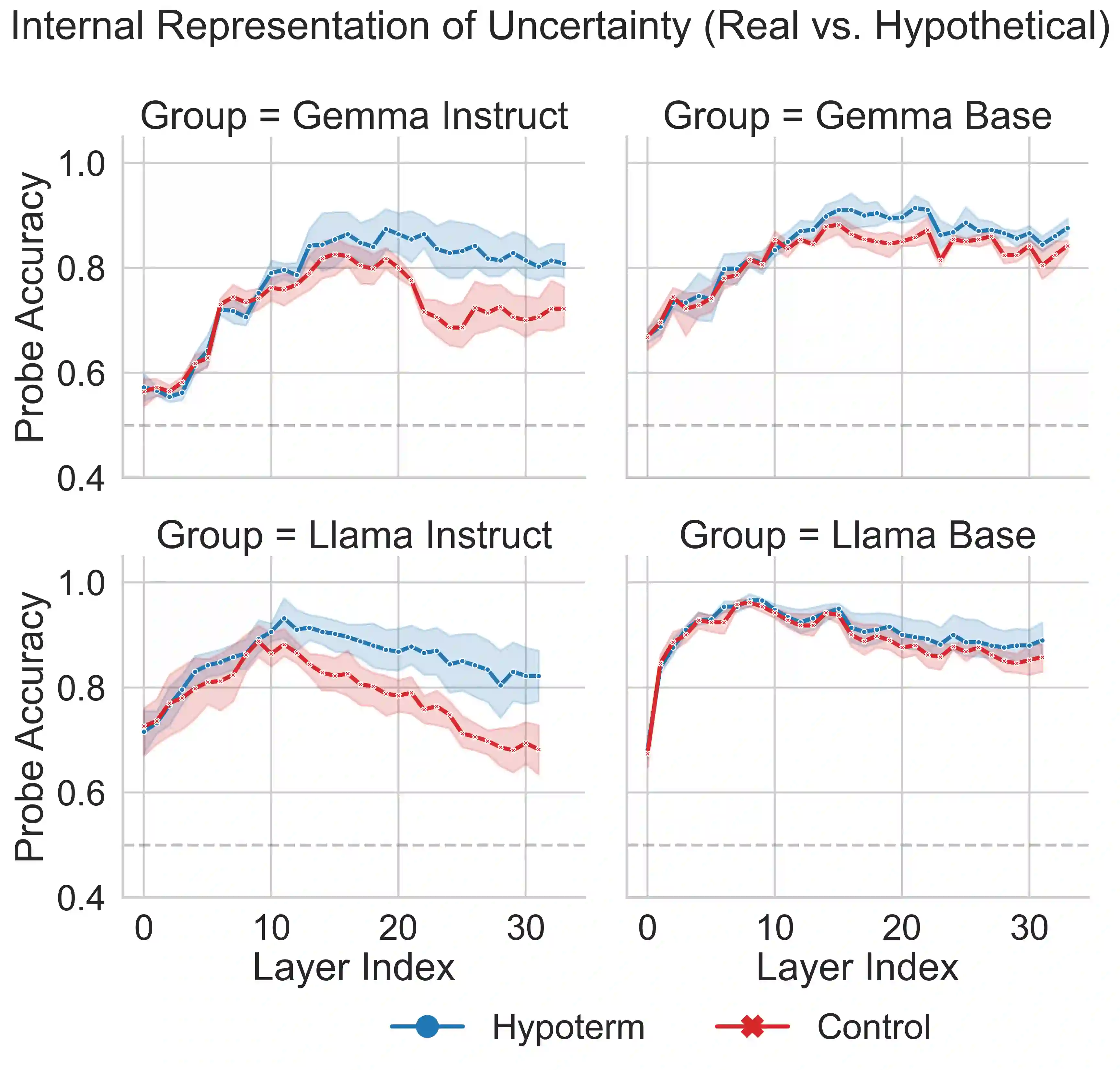
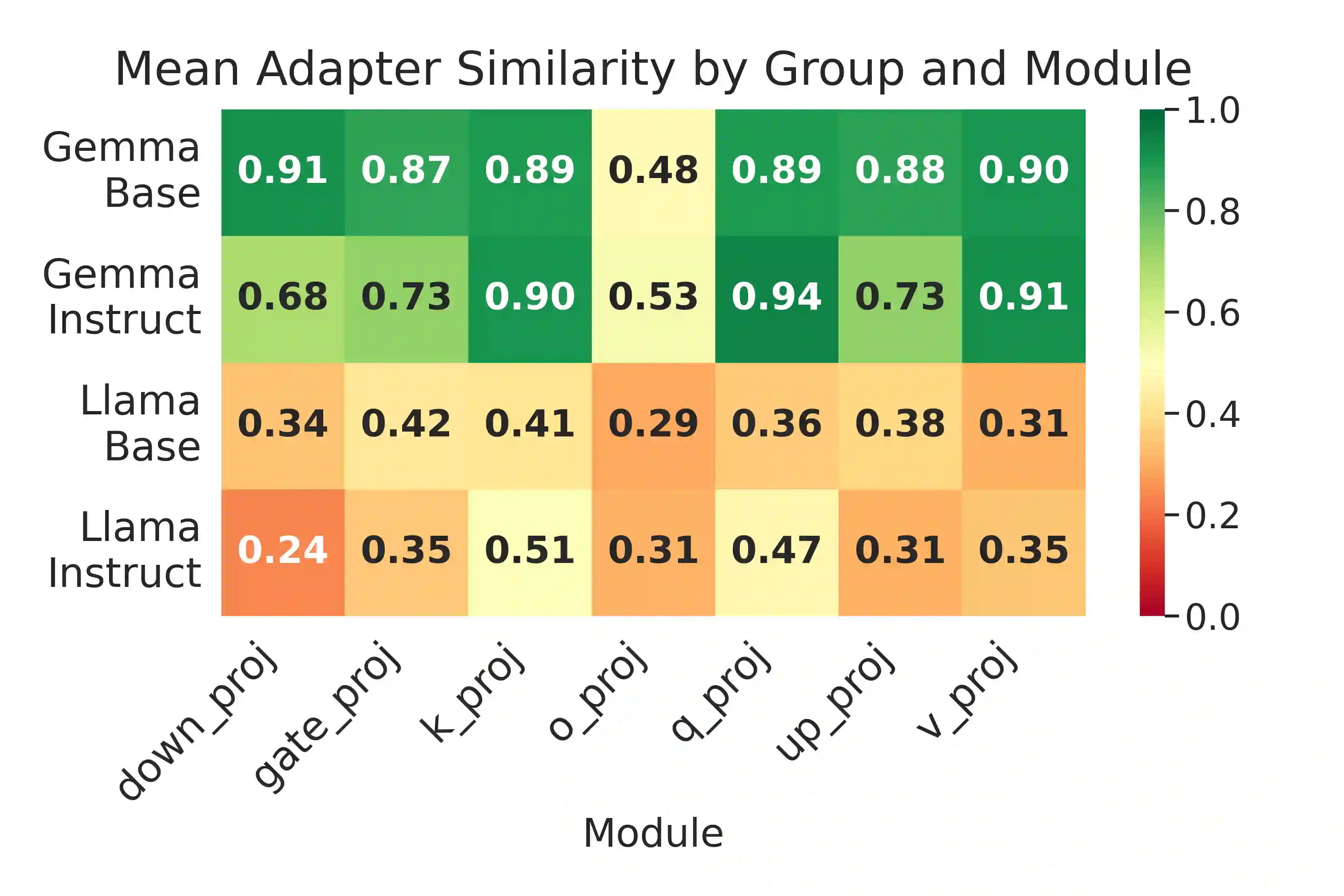
Large language models (LLMs) often hallucinate, producing fluent but false information, partly because supervised fine-tuning (SFT) implicitly rewards always responding. We introduce $\textit{HypoTermInstruct}$, an SFT dataset (31,487 responses for 11,151 questions) designed to teach models epistemological humility-the ability to recognize the limits of their own knowledge and admit uncertainty. This is achieved through questions about non-existent "hypothetical" terms. We also release $\textit{HypoTermQA-Enhanced}$, a benchmark for hallucination tendency strengthened through multiple validations. We conducted 800 controlled LoRA SFT runs across $\textit{Llama3.1-8B}$ and $\textit{Gemma3-4B}$ (base and instruct), testing 100 fine-tuning configurations with paired controls. Our results demonstrate that replacing generic instruction data with $\textit{HypoTermInstruct}$ significantly improves the HypoTerm Score (median increases of 0.19% to 25.91%) and FactScore (+0.39% to +0.86%), while maintaining stable performance on MMLU (minimal decreases of 0.26% to 0.35%). Our work demonstrates that targeted, high-quality SFT data teaching meta-cognitive skills can effectively reduce hallucination without preference/RL pipelines, providing mechanistic insights and a practical path toward more reliable AI systems.
翻译:大型语言模型(LLMs)经常产生幻觉,即生成流畅但错误的信息,部分原因在于监督微调(SFT)过程隐式地奖励模型总是给出回答。我们引入了 $\textit{HypoTermInstruct}$,这是一个SFT数据集(包含针对11,151个问题的31,487个回答),旨在教导模型具备认知谦逊——即识别自身知识局限并承认不确定性的能力。这是通过询问关于不存在的“假设性”术语的问题来实现的。我们还发布了 $\textit{HypoTermQA-Enhanced}$,这是一个通过多重验证强化的、用于评估幻觉倾向的基准。我们在 $\textit{Llama3.1-8B}$ 和 $\textit{Gemma3-4B}$(基础版和指令版)上进行了总计800次受控的LoRA SFT实验,测试了100种微调配置及其配对对照组。我们的结果表明,用 $\textit{HypoTermInstruct}$ 替换通用的指令数据,能显著提升HypoTerm分数(中位数提升0.19%至25.91%)和FactScore(提升+0.39%至+0.86%),同时在MMLU基准上保持稳定的性能(仅出现0.26%至0.35%的最小降幅)。我们的工作表明,用于教授元认知技能的、定向的高质量SFT数据,无需偏好/强化学习(RL)流程即可有效减少幻觉,这为构建更可靠的AI系统提供了机制性见解和一条实用路径。