尽管视频-语言建模已取得显著进展,但幻觉问题仍是视频大语言模型(Vid-LLMs)面临的持久挑战。幻觉是指模型输出内容看似合理,实则与输入视频内容相矛盾的现象。本综述对 Vid-LLMs 中的幻觉现象进行了全面分析,并提出了一种系统性的分类体系,将其归纳为两大核心类型:动态扭曲(Dynamic Distortion)与内容编造(Content Fabrication),且每类下均包含两个子类及代表性案例。 基于该分类体系,我们回顾了幻觉评估与缓解方面的最新进展,涵盖了核心基准测试、评价指标及干预策略。我们进一步分析了动态扭曲与内容编造的根源,指出其通常源于时序表征能力受限以及视觉定位(Visual Grounding)不足。基于上述见解,本文提出了若干极具前景的未来研究方向,包括开发动作感知视觉编码器以及集成反事实学习技术。本综述通过整合分散的研究进展,旨在促进对 Vid-LLMs 幻觉问题的系统性理解,为构建稳健且可靠的视频-语言系统奠定基础。
1 引言
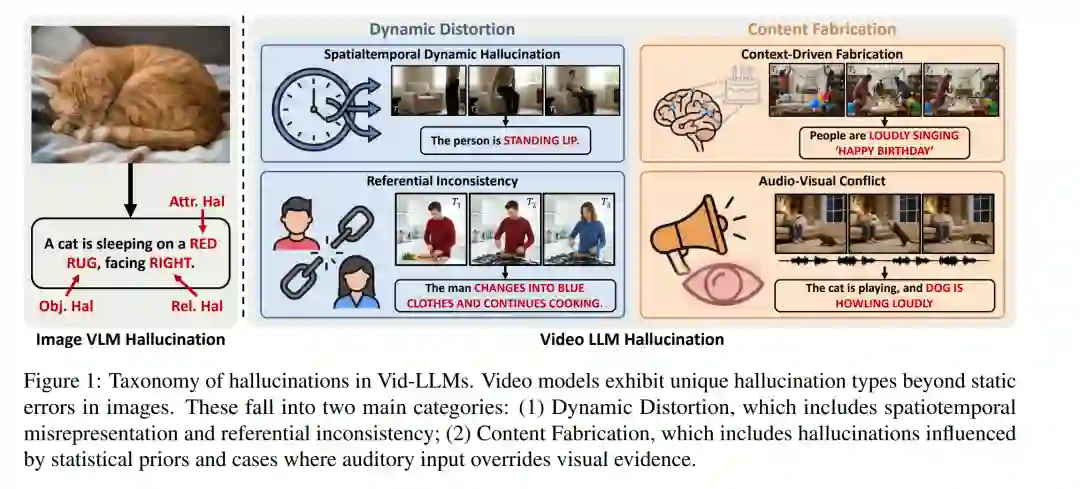
视频大语言模型(Vid-LLMs)将视觉-语言系统的能力从静态图像扩展到了时序连贯的视频输入,从而实现了动作识别、时序推理及音视频理解等任务 (Zhang et al., 2023a; Maaz et al., 2024; Li et al., 2023a; Lin et al., 2024; Wang et al., 2024a; Fu et al., 2024)。尽管近期取得了显著进展,这些模型仍易受**幻觉(Hallucinations)**的影响,即生成看似合理且连贯、实则与视频实际内容相矛盾的输出。在具身智能(Embodied AI, Wu et al., 2023)和自动驾驶(Chen et al., 2024)等安全至关重要的领域,这一问题带来了严重的可靠性与安全风险。虽然基于图像的视觉-语言模型(VLMs)中的幻觉问题已有广泛综述 (Liu et al., 2024a; Lan et al., 2024),但视频固有的时序结构、运动动力学以及音视频整合的复杂性,使得这些见解难以直接应用于视频领域。
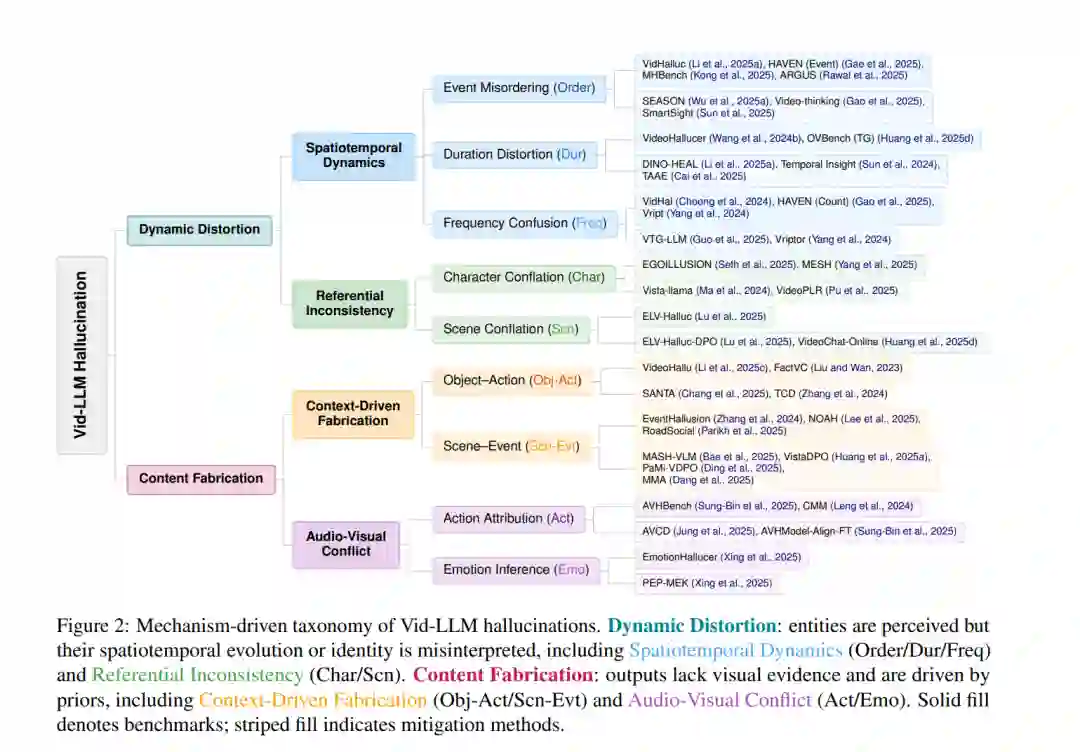
为了填补这一空白,本综述提出了一种针对视频特性且由机制驱动的分类体系,将幻觉分为两大主要类型:动态扭曲(Dynamic Distortion),即模型错误地表述了实体与场景的时空演变或引用一致性(Referential Consistency);以及内容编造(Content Fabrication),即输出受到先验知识的影响或被音频模态主导。基于该分类体系,我们回顾了 Vid-LLMs 幻觉评估与缓解方面的最新进展,重点关注核心基准测试、评价指标及干预策略。 动态扭曲包括时空动力学中的幻觉,例如事件顺序错误 (Li et al., 2025a; Wu et al., 2025a; Sun et al., 2025)、时长估计不准 (Wang et al., 2024b; Huang et al., 2025d; Sun et al., 2024) 和频率计数错误 (Gao et al., 2025; Choong et al., 2024);同时也包括引用不一致现象,即模型混淆了不同的角色 (Seth et al., 2025; Yang et al., 2025) 或场景 (Lu et al., 2025; Ma et al., 2024; Pu et al., 2025)。 内容编造则包括上下文驱动型幻觉,即常见的“物体-动作” (Chang et al., 2025; Li et al., 2025c) 或“场景-事件” (Bae et al., 2025; Zhang et al., 2024; Ding et al., 2025) 共现模式导致了无根据的推断;以及音视频冲突,即强势的听觉线索掩盖了视觉证据,导致幻觉动作 (Sung-Bin et al., 2025; Jung et al., 2025) 或情绪状态 (Xing et al., 2025) 的产生。 进一步分析揭示了动态扭曲与内容编造的底层机制。动态扭曲通常源于时序编码受限导致细粒度运动线索缺失 (Zhao et al., 2025; Liu et al., 2024b),并在长视频中因长期记忆不足 (Bae et al., 2025) 和时序定位(Temporal Localization)能力较差 (Wu et al., 2025a) 而进一步加剧。相比之下,内容编造源于视觉定位(Visual Grounding)不足 (Lee et al., 2025),导致预训练先验 (Li et al., 2025c) 或主导音频信号 (Leng et al., 2024) 覆盖了视觉证据。 鉴于这些潜在机制,极具前景的研究方向包括开发动作感知架构 (Wu et al., 2025b) 以保留细粒度时序特征,从而强化视觉感知与时序推理之间的对齐。此外,解离视觉证据与先验知识的反事实训练策略 (Huang et al., 2025c) 为缓解内容编造提供了一种原则性方法,鼓励模型更忠实地基于视觉输入进行预测。 与现有综述的比较。 幻觉问题在 LLM 和基于图像的 VLM 中已得到深入研究 (Zhang et al., 2023c; Huang et al., 2025b; Liu et al., 2024a; Lan et al., 2024)。虽然部分多模态大模型(MLLM)幻觉综述 (Sahoo et al., 2024; Bai et al., 2024) 在提及其他模态时涉及了视频,但其对视频幻觉的讨论仍停留在表面,仅简要提及基准测试和缓解策略,缺乏结构性或因果性分析。相比之下,本综述首次提出了由机制驱动的 Vid-LLMs 幻觉分类体系。我们提出了一个分层分类框架(图 2),对现有文献进行了更广泛、更详尽的综述,并分析了幻觉的底层诱因。基于此分析,我们勾勒了与诱因分析、基准覆盖和缓解策略紧密结合的未来方向,为构建抗幻觉的 Vid-LLMs 提供了连贯的路线图。 如第 2 节所述,视频的时序性与多模态特性带来了超越静态图像设置的挑战。为应对这些挑战,我们提出了一种由机制驱动的视频特有动态级幻觉分类体系。该体系依据可观察到的失效模式(Failure Modes)而非输入属性(如音频、长度或体裁)进行分类;我们将后者视为影响幻觉严重程度的调节因子。 这种设计基于以下观察:相似的失效模式(如动态关系错误或先验驱动的内容补全)会跨越不同的输入设置而出现;如果将输入属性作为主要分类轴,将会把结构上相同的失效模式割裂开来,从而阻碍不同设置间的可比性。本分类体系精准捕捉了时序推理与跨模态对齐中的失效,并将幻觉归纳为动态扭曲(Dynamic Distortion)与内容编造(Content Fabrication),每一大类下各设两个子类及代表性案例(见图 2)。该体系为后续的评估与针对性缓解策略(详见第 4 节与第 5 节)提供了统一的基础。