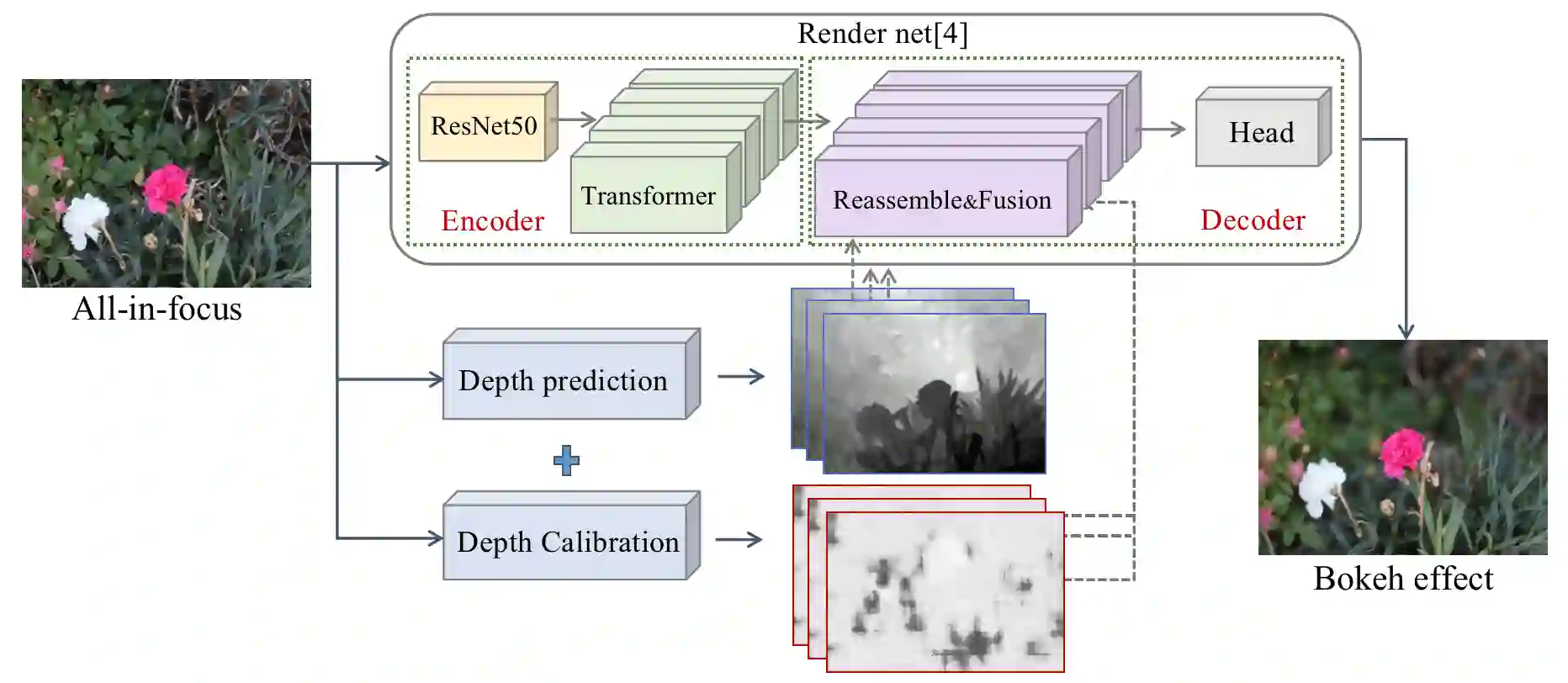
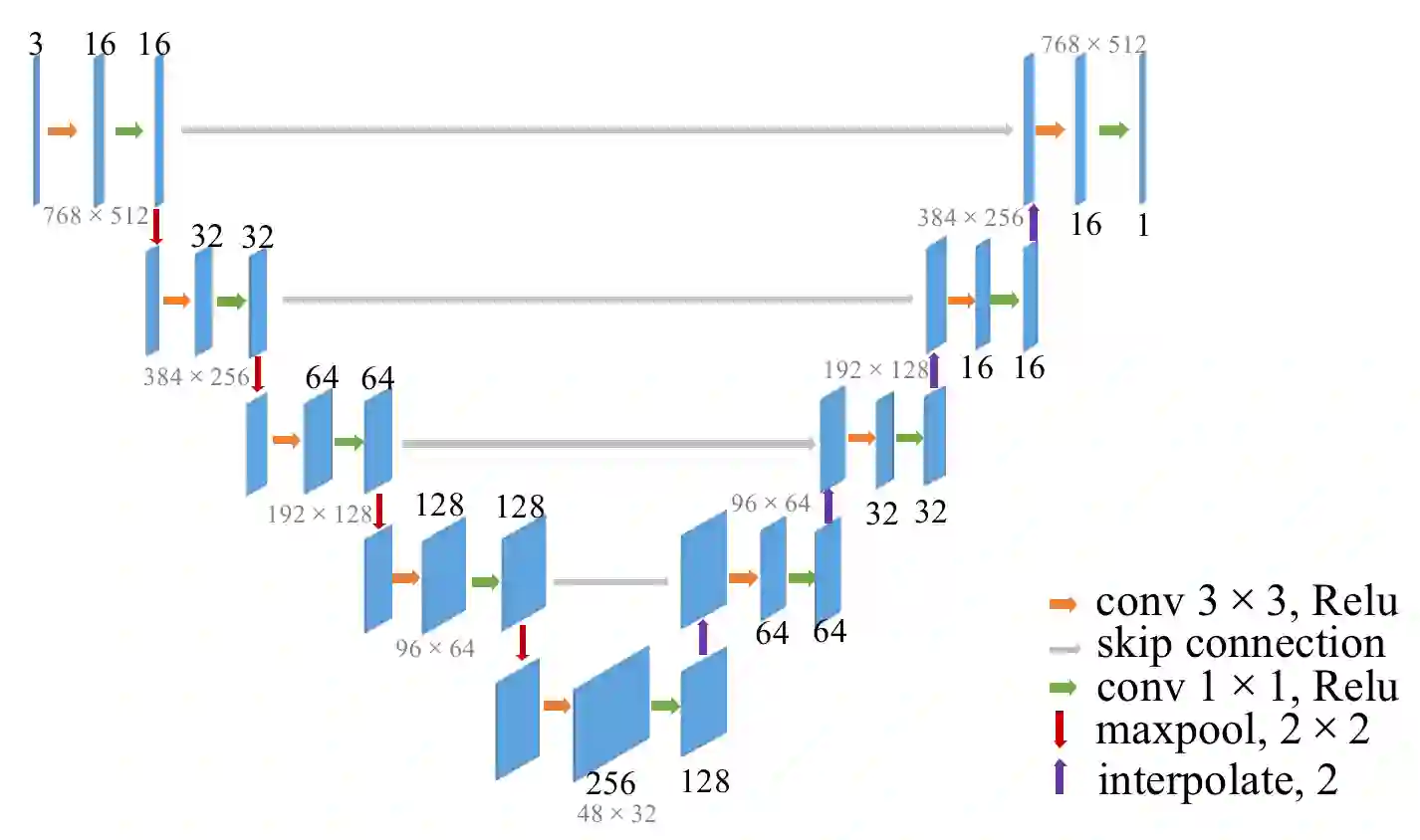
Bokeh rendering is a popular and effective technique used in photography to create an aesthetically pleasing effect. It is widely used to blur the background and highlight the subject in the foreground, thereby drawing the viewer's attention to the main focus of the image. In traditional digital single-lens reflex cameras (DSLRs), this effect is achieved through the use of a large aperture lens. This allows the camera to capture images with shallow depth-of-field, in which only a small area of the image is in sharp focus, while the rest of the image is blurred. However, the hardware embedded in mobile phones is typically much smaller and more limited than that found in DSLRs. Consequently, mobile phones are not able to capture natural shallow depth-of-field photos, which can be a significant limitation for mobile photography. To address this challenge, in this paper, we propose a novel method for bokeh rendering using the Vision Transformer, a recent and powerful deep learning architecture. Our approach employs an adaptive depth calibration network that acts as a confidence level to compensate for errors in monocular depth estimation. This network is used to supervise the rendering process in conjunction with depth information, allowing for the generation of high-quality bokeh images at high resolutions. Our experiments demonstrate that our proposed method outperforms state-of-the-art methods, achieving about 24.7% improvements on LPIPS and obtaining higher PSNR scores.
翻译:散景渲染是摄影中一种流行且有效的技术,用于创造美观的视觉效果。它被广泛用于模糊背景、突出前景主体,从而将观者注意力吸引到图像的主要焦点上。在传统数码单反相机中,这一效果通过使用大光圈镜头实现,使相机能够捕捉浅景深图像——仅有小范围区域清晰对焦,其余部分被虚化。然而,手机内置的硬件通常比单反相机更小且更受限,因此无法拍摄自然的浅景深照片,这成为手机摄影的一大局限。为解决这一挑战,本文提出了一种基于Vision Transformer(一种最新且强大的深度学习架构)的散景渲染新方法。我们采用自适应深度校准网络作为置信度指标,用于补偿单目深度估计中的误差。该网络与深度信息协同监督渲染过程,从而生成高分辨率的高质量散景图像。实验表明,我们的方法超越了现有最优技术,在LPIPS指标上取得约24.7%的提升,并获得了更高的PSNR分数。