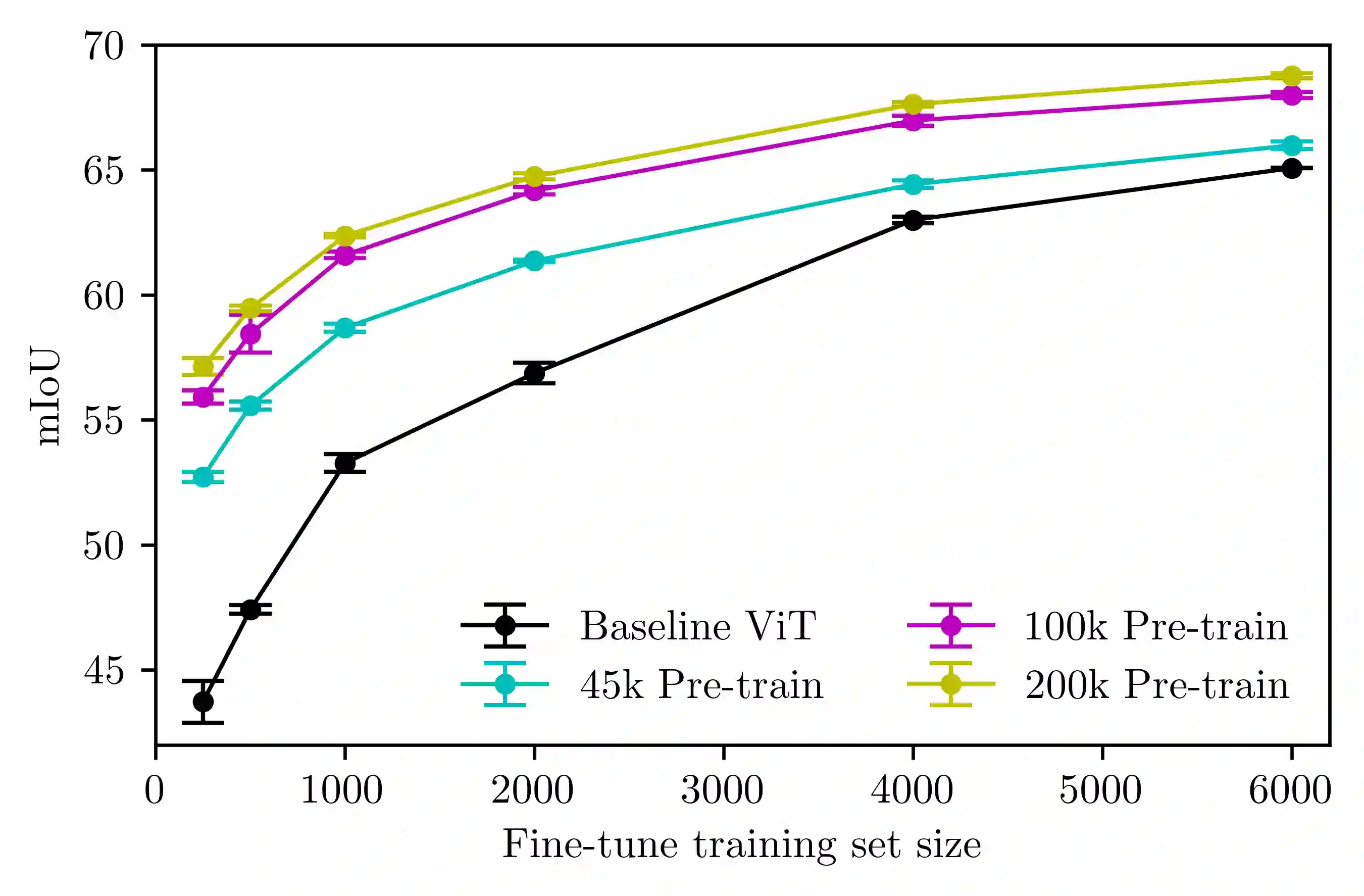
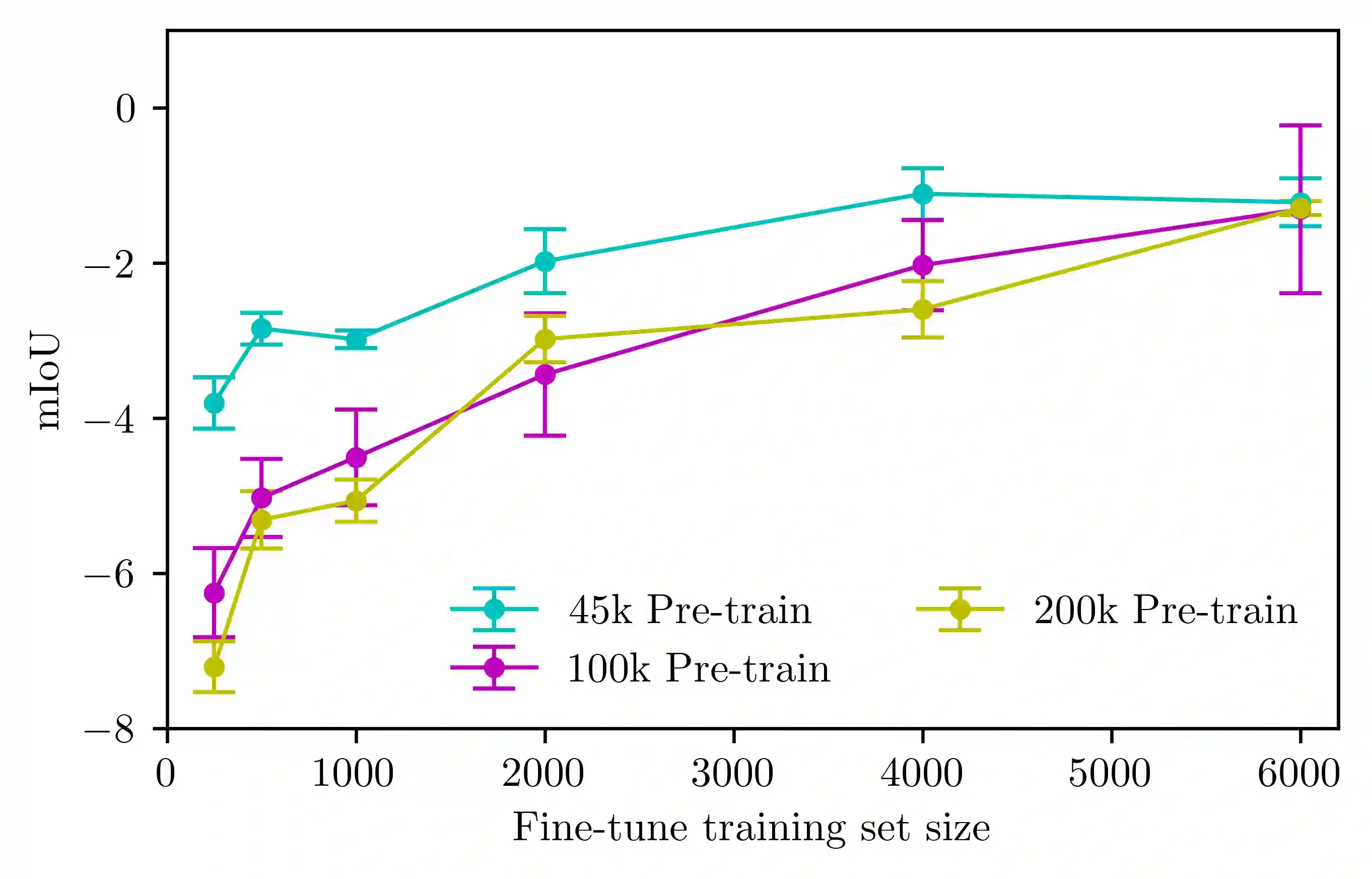
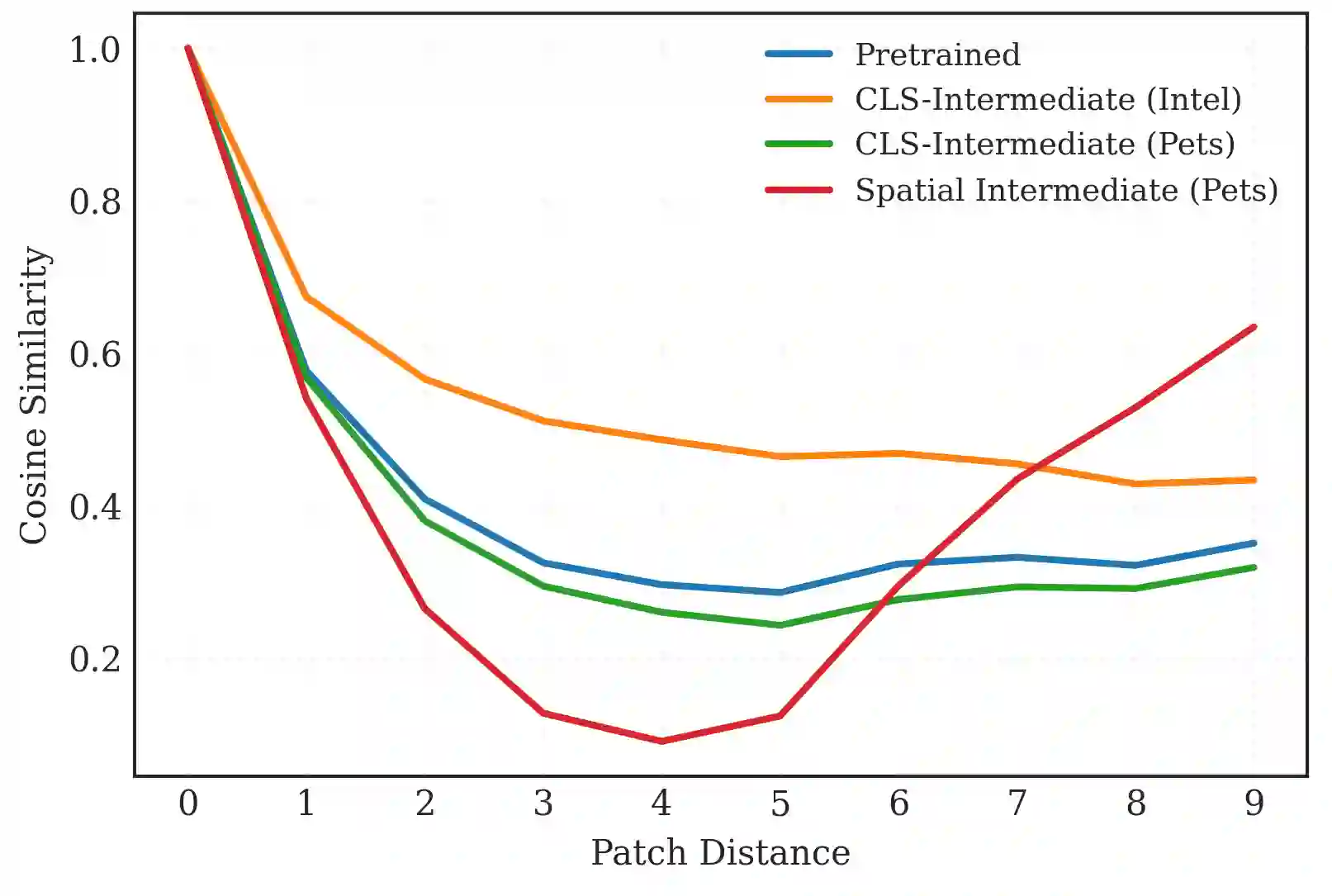
Transformer-based architectures have become a dominant paradigm in vision and language, but their success is often attributed to large model capacity and massive training data. In this work, we examine how self-supervised pre-training, intermediate fine-tuning, and downstream fine-tuning interact in a low-capacity regime, using a 5M-parameter Vision Transformer for semantic segmentation. Across multiple data scales, we find that masked image modeling pre-training and downstream fine-tuning reliably improve performance, but with clear diminishing returns as supervision increases. In contrast, inserting an intermediate classification fine-tuning stage consistently degrades downstream performance, with the largest drops occurring precisely where pre-training is most effective. Through an analysis of patch-level representation geometry, we show that classification-based intermediate supervision actively interferes with representations learned during pre-training by collapsing spatial structure critical for dense prediction. These results indicate that, in small models, the geometry of supervision matters more than the number of training stages: misaligned intermediate objectives can negate the benefits of pre-training rather than amplify them.
翻译:Transformer架构已成为视觉与语言领域的主导范式,但其成功常被归因于大模型容量与海量训练数据。本研究通过使用500万参数的Vision Transformer进行语义分割任务,探究了在有限容量条件下自监督预训练、中间微调与下游微调三者间的相互作用。在多个数据规模下,我们发现掩码图像建模预训练与下游微调能稳定提升模型性能,但随着监督信号的增强均呈现明显的收益递减趋势。与此相反,插入中间分类微调阶段会持续损害下游性能,且性能下降最显著的区间恰恰出现在预训练最有效的场景。通过对块级表示几何结构的分析,我们证明基于分类的中间监督会通过破坏密集预测所需的关键空间结构,主动干扰预训练阶段学习到的表示。这些结果表明:在小模型中,监督信号的几何特性比训练阶段的数量更为重要——未对齐的中间目标可能抵消而非增强预训练带来的优势。