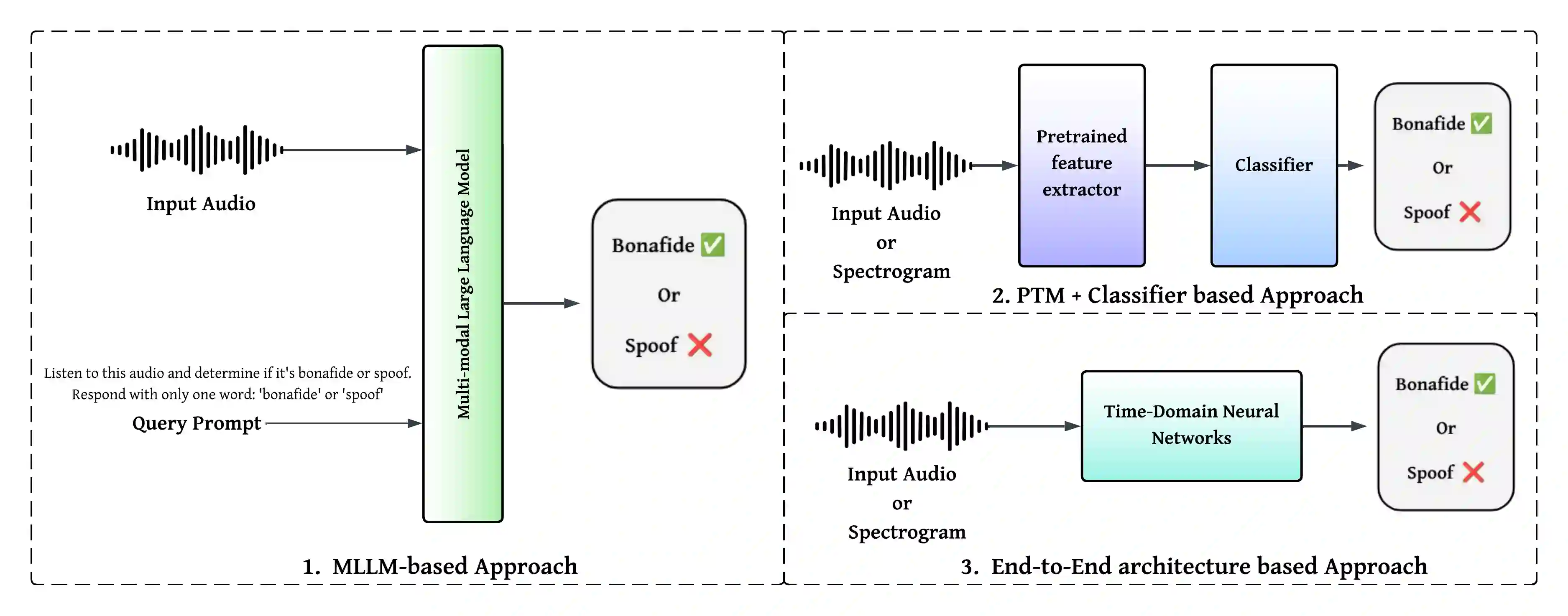
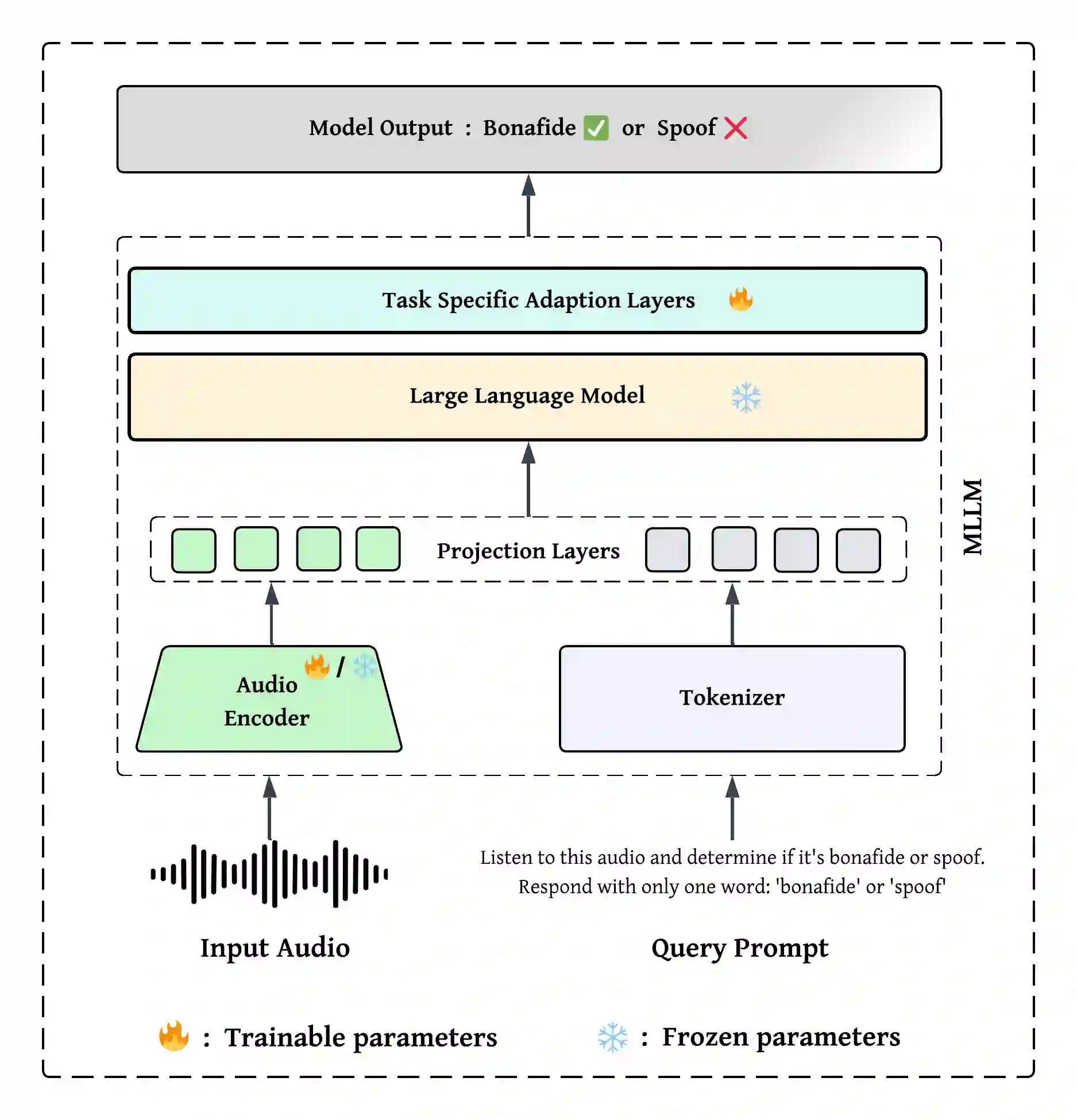
While Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have shown strong generalisation in detecting image and video deepfakes, their use for audio deepfake detection remains largely unexplored. In this work, we aim to explore the potential of MLLMs for audio deepfake detection. Combining audio inputs with a range of text prompts as queries to find out the viability of MLLMs to learn robust representations across modalities for audio deepfake detection. Therefore, we attempt to explore text-aware and context-rich, question-answer based prompts with binary decisions. We hypothesise that such a feature-guided reasoning will help in facilitating deeper multimodal understanding and enable robust feature learning for audio deepfake detection. We evaluate the performance of two MLLMs, Qwen2-Audio-7B-Instruct and SALMONN, in two evaluation modes: (a) zero-shot and (b) fine-tuned. Our experiments demonstrate that combining audio with a multi-prompt approach could be a viable way forward for audio deepfake detection. Our experiments show that the models perform poorly without task-specific training and struggle to generalise to out-of-domain data. However, they achieve good performance on in-domain data with minimal supervision, indicating promising potential for audio deepfake detection.
翻译:尽管视觉语言模型(VLMs)和多模态大语言模型(MLLMs)在检测图像和视频深度伪造方面展现出强大的泛化能力,但它们在音频深度伪造检测中的应用仍基本未被探索。本研究旨在探索MLLMs在音频深度伪造检测中的潜力。通过将音频输入与一系列文本提示作为查询相结合,以探究MLLMs能否学习跨模态的鲁棒表示用于音频深度伪造检测。因此,我们尝试探索基于文本感知、上下文丰富且带有二元决策的问答式提示。我们假设,这种特征引导的推理将有助于促进更深层次的多模态理解,并为音频深度伪造检测实现鲁棒的特征学习。我们评估了两种MLLMs——Qwen2-Audio-7B-Instruct和SALMONN——在两种评估模式下的性能:(a)零样本和(b)微调。我们的实验表明,将音频与多提示方法相结合可能是音频深度伪造检测的一条可行路径。实验结果显示,未经任务特定训练时模型表现不佳,且难以泛化到域外数据。然而,在最小监督下,它们能在域内数据上取得良好性能,这表明其在音频深度伪造检测中具有广阔的应用前景。