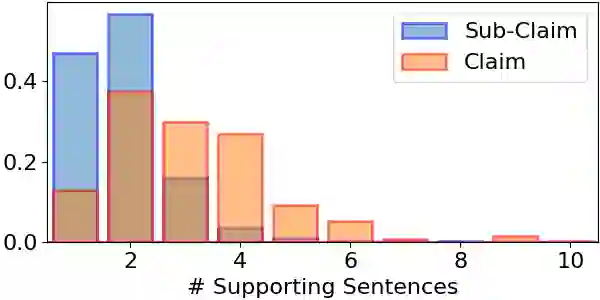
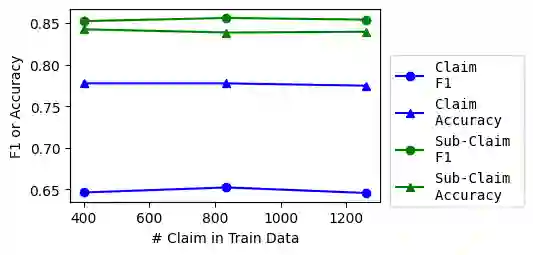
Models for textual entailment have increasingly been applied to settings like fact-checking, presupposition verification in question answering, and validating that generation models' outputs are faithful to a source. However, such applications are quite far from the settings that existing datasets are constructed in. We propose WiCE, a new textual entailment dataset centered around verifying claims in text, built on real-world claims and evidence in Wikipedia with fine-grained annotations. We collect sentences in Wikipedia that cite one or more webpages and annotate whether the content on those pages entails those sentences. Negative examples arise naturally, from slight misinterpretation of text to minor aspects of the sentence that are not attested in the evidence. Our annotations are over sub-sentence units of the hypothesis, decomposed automatically by GPT-3, each of which is labeled with a subset of evidence sentences from the source document. We show that real claims in our dataset involve challenging verification problems, and we benchmark existing approaches on this dataset. In addition, we show that reducing the complexity of claims by decomposing them by GPT-3 can improve entailment models' performance on various domains.
翻译:文本蕴含模型已越来越多地应用于事实核查、问答中的预设验证,以及验证生成模型的输出是否忠实于原文等场景。然而,这些应用场景与现有数据集的构建背景相去甚远。我们提出WiCE,这是一个以文本声明验证为核心的新文本蕴含数据集,基于维基百科中的真实声明与证据构建,并配有细粒度标注。我们从维基百科中收集引用了至少一个网页的句子,并标注这些网页内容是否蕴含这些句子。负例自然产生,涵盖从对文本的轻微误解到句子中未在证据中得到证实的细微方面。我们的标注针对假设的子句单元进行,这些子句由GPT-3自动分解,每个子句均标注来自源文档的证据句子子集。我们展示了数据集中的真实声明涉及具有挑战性的验证问题,并在该数据集上对现有方法进行了基准测试。此外,我们还证明了通过GPT-3分解声明以降低其复杂性,可以提升蕴含模型在多个领域的性能。