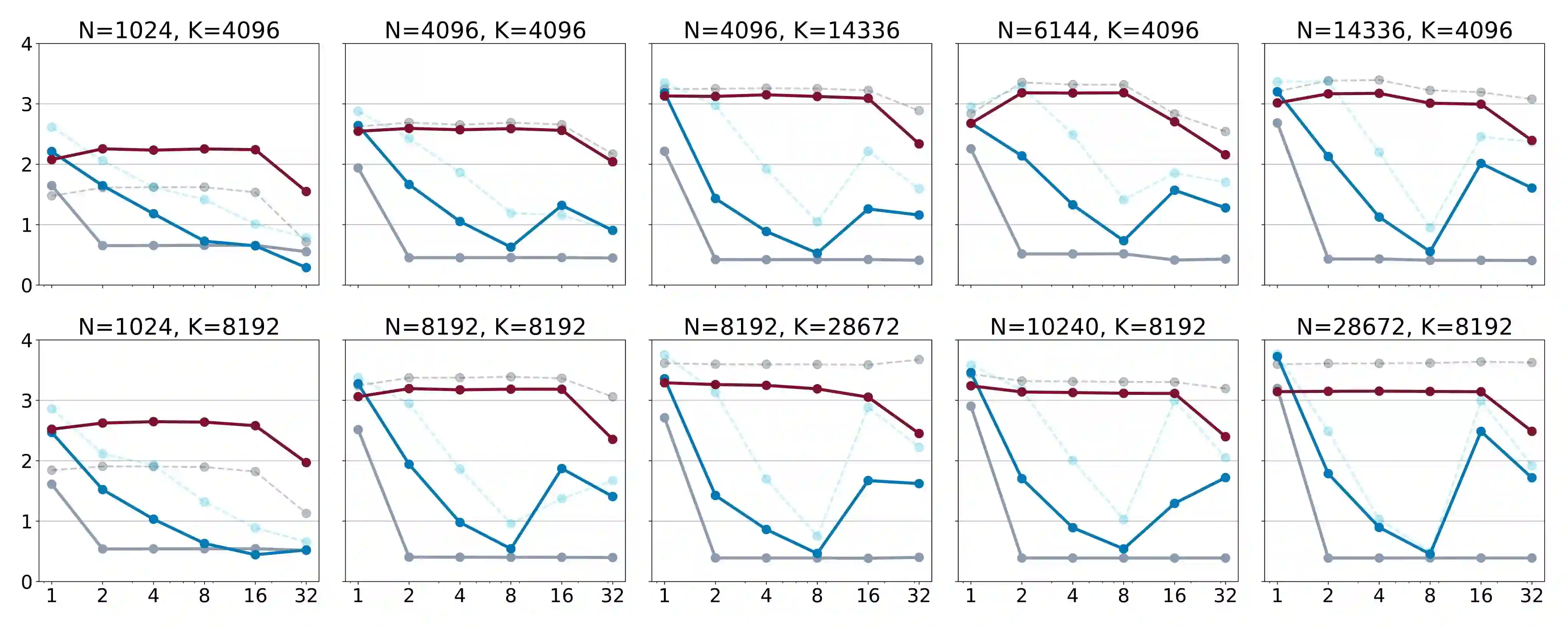
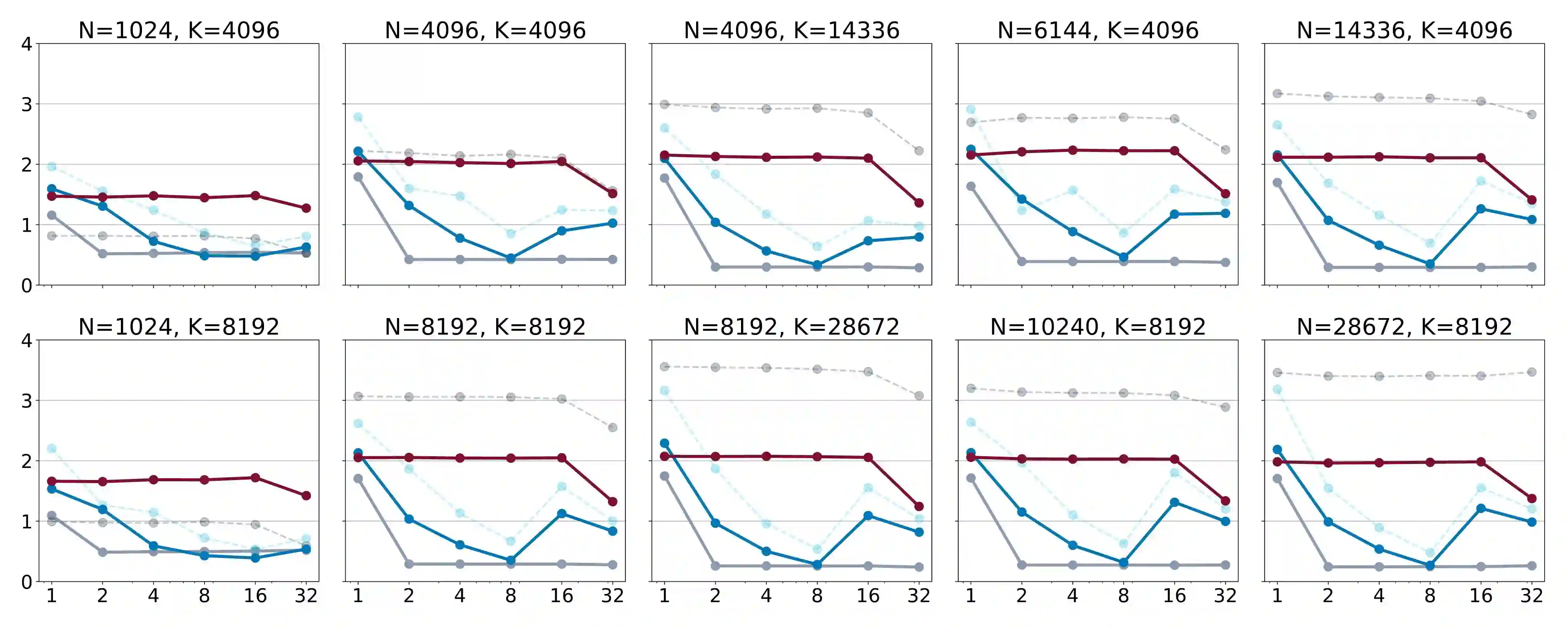
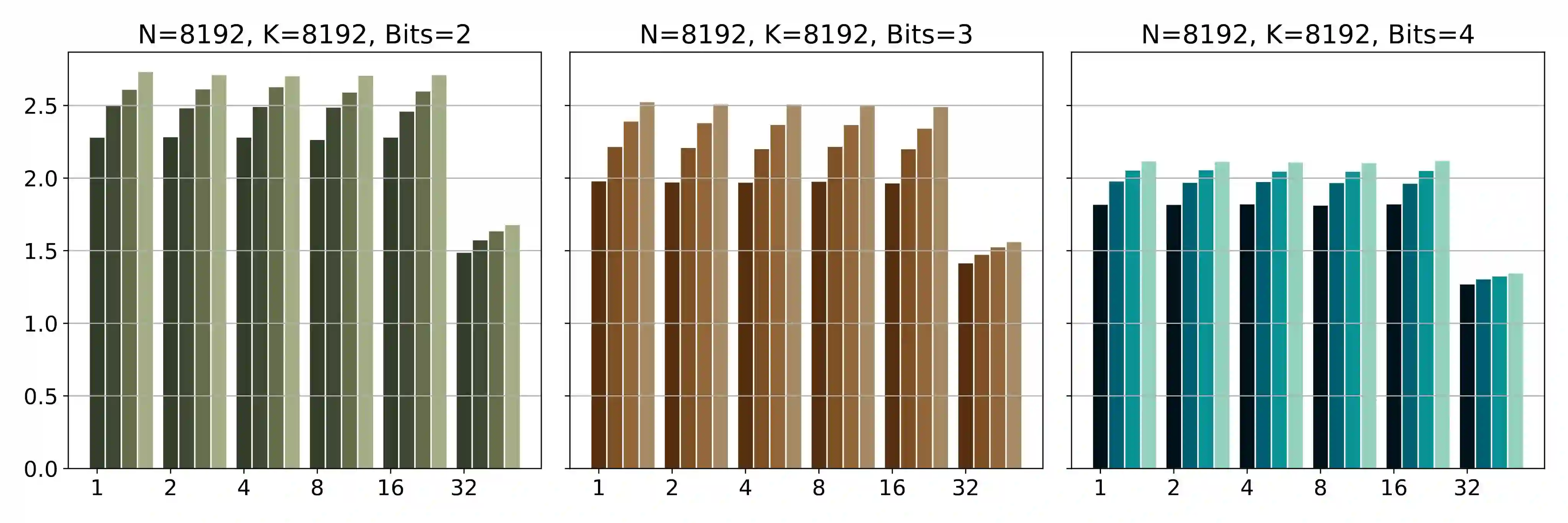
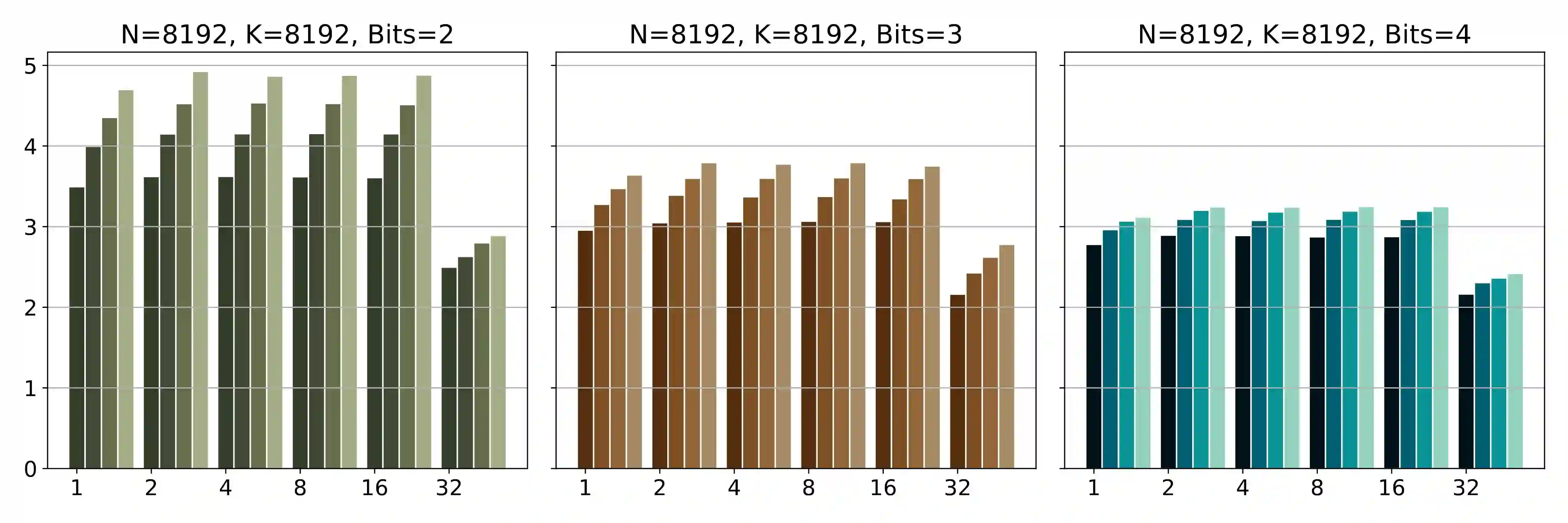
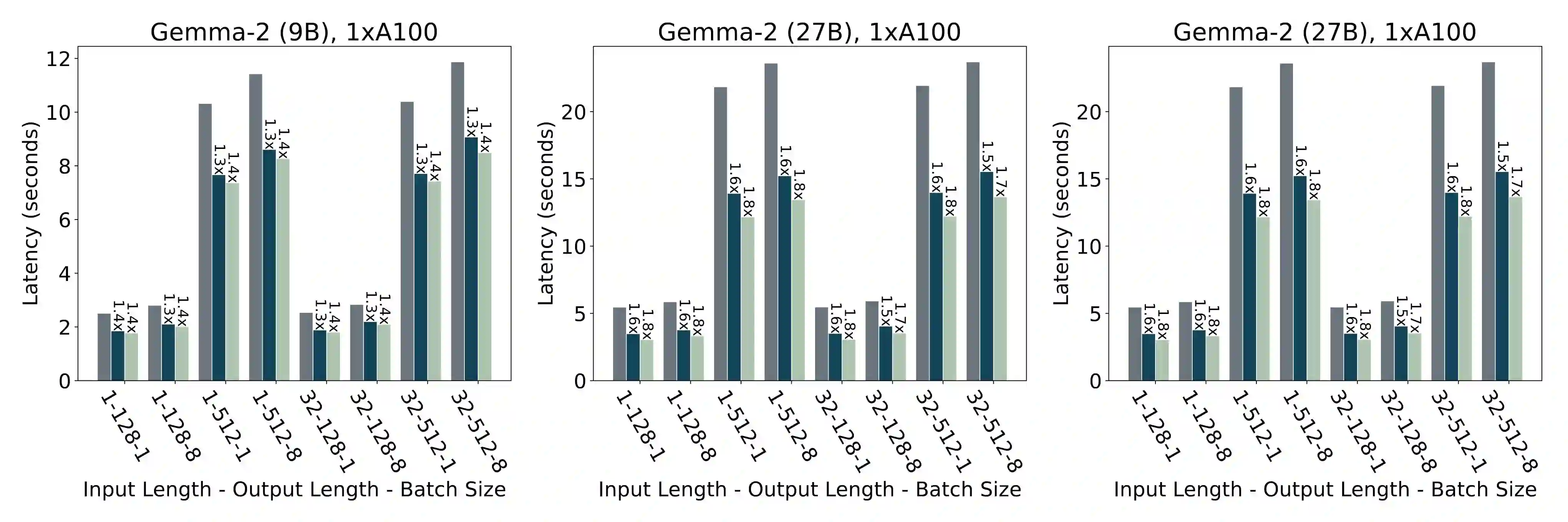
The deployment of large language models (LLMs) is often constrained by memory bandwidth, where the primary bottleneck is the cost of transferring model parameters from the GPU's global memory to its registers. When coupled with custom kernels that fuse the dequantization and matmul operations, weight-only quantization can thus enable faster inference by reducing the amount of memory movement. However, developing high-performance kernels for weight-quantized LLMs presents substantial challenges, especially when the weights are compressed to non-evenly-divisible bit widths (e.g., 3 bits) with non-uniform, lookup table (LUT) quantization. This paper describes FLUTE, a flexible lookup table engine for LUT-quantized LLMs, which uses offline restructuring of the quantized weight matrix to minimize bit manipulations associated with unpacking, and vectorization and duplication of the lookup table to mitigate shared memory bandwidth constraints. At batch sizes < 32 and quantization group size of 128 (typical in LLM inference), the FLUTE kernel can be 2-4x faster than existing GEMM kernels. As an application of FLUTE, we explore a simple extension to lookup table-based NormalFloat quantization and apply it to quantize LLaMA3 to various configurations, obtaining competitive quantization performance against strong baselines while obtaining an end-to-end throughput increase of 1.5 to 2 times.
翻译:大型语言模型(LLM)的部署常受限于内存带宽,其主要瓶颈在于将模型参数从GPU全局内存传输至寄存器的开销。当结合能够融合反量化与矩阵乘法运算的自定义内核时,仅对权重进行量化可通过减少内存移动量来实现更快的推理。然而,为权重量化LLM开发高性能内核面临巨大挑战,尤其是在权重被压缩至非均匀可整除的位宽(例如3比特)并采用非均匀查找表(LUT)量化方案时。本文介绍了FLUTE,一种面向LUT量化LLM的灵活查找表引擎。它通过对量化权重矩阵进行离线重构,以最小化与数据解包相关的比特操作;同时通过查找表的向量化与复制策略,缓解共享内存带宽限制。在批大小小于32且量化分组大小为128(LLM推理中的典型配置)时,FLUTE内核可比现有的通用矩阵乘法(GEMM)内核快2至4倍。作为FLUTE的应用,我们探索了对基于查找表的NormalFloat量化方案的简单扩展,并将其应用于LLaMA3模型的不同量化配置,在取得与强基线模型具有竞争力的量化性能的同时,实现了1.5至2倍的端到端吞吐量提升。