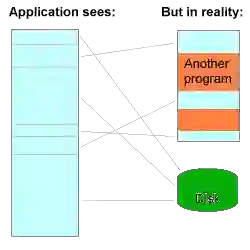
Virtual-to-physical address translation is a critical performance bottleneck in paging-based virtual memory systems. The Translation Lookaside Buffer (TLB) accelerates address translation by caching frequently accessed mappings, but TLB misses lead to costly page walks. Hardware and software techniques address this challenge. Hardware approaches enhance TLB reach through system-level support, while software optimizations include TLB prefetching, replacement policies, superpages, and page size adjustments. Prefetching Page Table Entries (PTEs) for future accesses reduces bottlenecks but may incur overhead from incorrect predictions. Integrating an Agile TLB Prefetcher (ATP) with SBFP optimizes performance by leveraging page table locality and dynamically identifying essential free PTEs during page walks. Predictive replacement policies further improve TLB performance. Traditional LRU replacement is limited to near-instant references, while advanced policies like SRRIP, GHRP, SHiP, SDBP, and CHiRP enhance performance by targeting specific inefficiencies. CHiRP, tailored for L2 TLBs, surpasses other policies by leveraging control flow history to detect dead blocks, utilizing L2 TLB entries for learning instead of sampling. These integrated techniques collectively address key challenges in virtual memory management.
翻译:虚拟到物理地址的转换是基于分页的虚拟内存系统中的关键性能瓶颈。转换后备缓冲器(TLB)通过缓存频繁访问的地址映射来加速地址转换,但TLB未命中会导致昂贵的页表遍历。硬件和软件技术共同应对这一挑战。硬件方法通过系统级支持扩展TLB覆盖范围,而软件优化则包括TLB预取、替换策略、大页及页大小调整等方案。针对未来访问的页表项(PTE)预取可减少瓶颈,但可能因错误预测产生额外开销。通过结合页表局部性并利用页表遍历过程动态识别关键空闲PTE,敏捷TLB预取器(ATP)与SBFP的集成优化了系统性能。预测性替换策略进一步提升了TLB效率。传统LRU替换仅适用于近即时引用场景,而SRRIP、GHRP、SHiP、SDBP及CHiRP等高级策略通过针对性优化改善了特定性能缺陷。专为L2 TLB设计的CHiRP策略通过利用控制流历史检测失效块,并直接使用L2 TLB条目进行学习(而非采样),超越了其他策略。这些集成技术共同解决了虚拟内存管理的核心挑战。