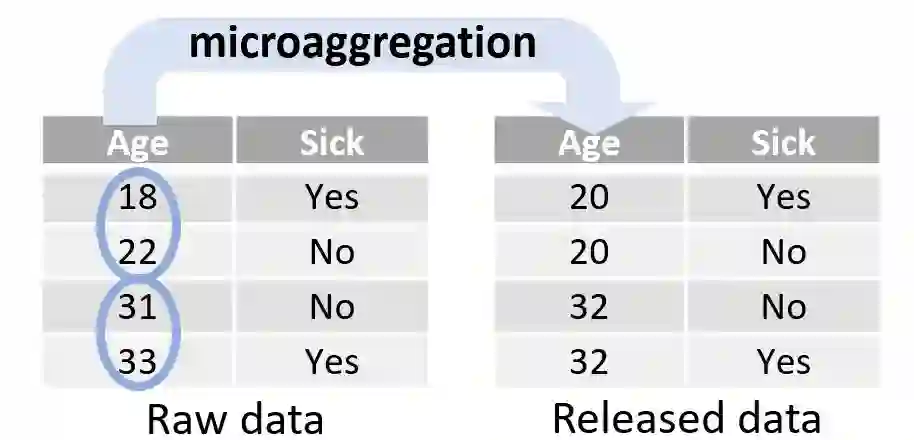
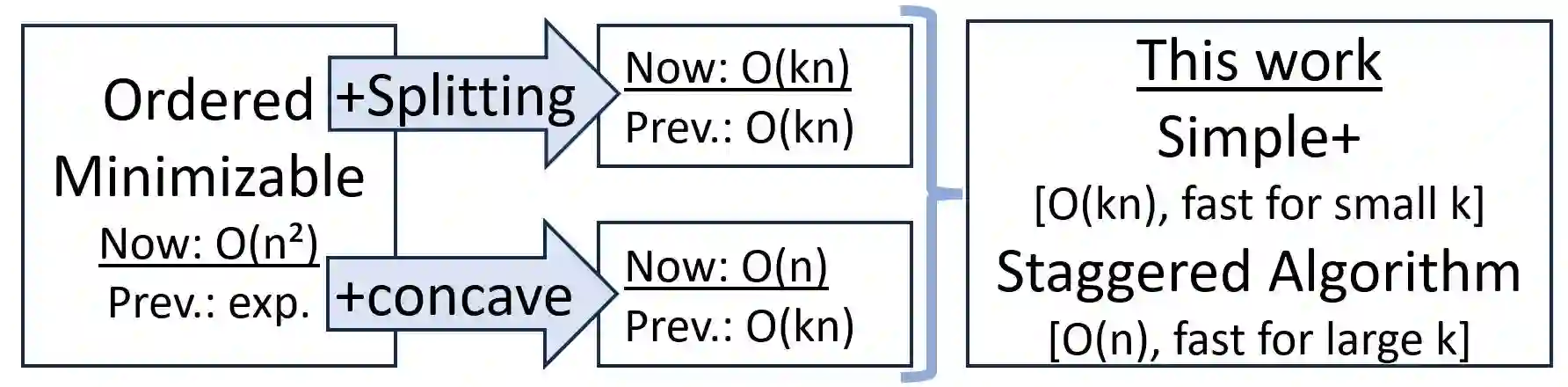
Microaggregation is a method to coarsen a dataset, by optimally clustering data points in groups of at least $k$ points, thereby providing a $k$-anonymity type disclosure guarantee for each point in the dataset. Previous algorithms for univariate microaggregation had a $O(k n)$ time complexity. By rephrasing microaggregation as an instance of the concave least weight subsequence problem, in this work we provide improved algorithms that provide an optimal univariate microaggregation on sorted data in $O(n)$ time and space. We further show that our algorithms work not only for sum of squares cost functions, as typically considered, but seamlessly extend to many other cost functions used for univariate microaggregation tasks. In experiments we show that the presented algorithms lead to real world performance improvements.
翻译:微聚集是一种通过将数据点最优聚类为至少包含$k$个点的组来粗化数据集的方法,从而为数据集中的每个点提供$k$匿名类型的披露保护。先前的单变量微聚集算法具有$O(k n)$的时间复杂度。通过将微聚集重新表述为凹最小权重子序列问题的一个实例,本文提出了改进算法,能够在$O(n)$时间和空间内实现排序数据上的最优单变量微聚集。我们进一步证明,该算法不仅适用于通常考虑的平方和代价函数,还能无缝扩展到单变量微聚集任务中使用的其他多种代价函数。实验表明,所提算法在实际应用中显著提升了性能。