
导读
多模态大模型的发展曾长期沿着两条相对独立的路线推进:一条关注理解,目标是让模型看懂图像、回答问题并完成跨模态推理;另一条关注生成,目标是合成图像、视频、音频或三维内容。前者偏好高层语义表示,后者需要保存纹理、布局和像素细节。两类系统各自快速进化,却也形成了模型、数据、训练目标和评估体系上的长期分裂。
CVPR 2026 教程 The Road to Convergence: Evolution of Unified Multimodal Models 讨论的正是这条“收敛之路”:如何在一个统一框架中同时完成理解、推理与生成,如何设计跨模态表示,如何组织训练与后训练,以及怎样从孤立基准走向真正统一的评估。教程由 William & Mary、Google DeepMind、北京大学和威斯康星大学麦迪逊分校的研究者共同组织,完整幻灯片共 103 页。 这篇文章按照教程原始五部分路线整理:先回顾从分化到统一的历史动因,再分析当前主流建模与表示方案,随后梳理六项前沿能力,进一步讨论理解与生成如何互相促进,最后落到视频、三维、世界模型和具身智能等开放方向。
教程基本信息
- 教程名称 The Road to Convergence: Evolution of Unified Multimodal Models
- 中文名称 走向收敛:统一多模态模型的演进
- 教程页面 https://rollingsu.github.io/umm-tutorial.github.io/
- 官方日程 https://cvpr.thecvf.com/Conferences/2026/Tutorials
讲者与组织团队
Jindong Wang
Jindong Wang,William & Mary 助理教授,曾任微软亚洲研究院高级研究员,研究覆盖迁移学习、基础模型与统一多模态模型,并具有 IJCAI、WSDM、KDD、AAAI 和 CVPR 等会议教程经验。
Hao Chen
Hao Chen,Google DeepMind 研究科学家,博士毕业于卡内基梅隆大学,研究聚焦面向可靠基础模型的数据中心方法,包括预训练数据缺陷、灾难性继承和多模态泛化。
Jiakui Hu
Jiakui Hu,北京大学博士生,研究方向包括统一模型、计算成像和视觉基础模型中的归纳偏置,在 ICCV、CVPR、ICLR、ICML、AAAI 等会议发表工作。
Zhaolong Su
Zhaolong Su,William & Mary 博士生,研究统一多模态模型、世界模型和物理人工智能,相关工作包括 CVPR 2026 的 UniGame 与 WWW 2026 的 FedUMM。
Sharon Li
Sharon Li,威斯康星大学麦迪逊分校副教授,主要研究可靠与安全人工智能系统,担任本教程顾问。
教程路线
教程幻灯片给出的内容安排如下:
-
第一部分:过去——从分化走向统一,30 分钟
-
第二部分:当前之一——统一模型的目标、建模与未来,55 分钟
-
休息,15 分钟
-
第三部分:当前之二——前沿亮点与趋势,45 分钟
-
第四部分:超越统一,25 分钟
-
第五部分:未来与开放讨论,25 分钟

Part 1 Past / 从分化走向统一
两条长期独立的技术路线
多模态理解的典型任务包括图像描述、视觉问答、视觉定位、关系推理和验证。模型需要从图像中抽取具有语义判别力的表示,并把视觉信息映射到语言空间。CLIP、BLIP、Flamingo 等工作代表了理解路线不断扩展的过程:从图文对齐到视觉语言预训练,再到利用大语言模型完成开放式多模态交互。 多模态生成则关注从文本或其他条件生成图像、视频和音频。扩散模型通过逐步去噪得到高质量连续信号,自回归模型则把视觉内容离散化后按序列预测。两条路线的目标函数不同:理解追求语义抽象和跨模态对齐,生成追求可重建性、纹理细节与感知质量。 这种分化并非偶然。一个适合分类和检索的视觉向量,往往主动丢弃背景纹理和像素级细节;一个适合图像重建的潜在编码,却未必能形成清晰的概念边界。统一模型必须处理的第一个根本矛盾,正是语义压缩与视觉保真之间的冲突。
为什么流水线系统不够
最直接的“统一”方式,是把理解模型、语言模型和生成模型串成流水线。例如先由视觉语言模型理解输入,再让语言模型重写提示词,最后调用扩散模型生成输出。这种系统能完成复合任务,但每个接口都会造成信息损失:视觉内容被压缩成文字描述,语言计划无法保存全部空间细节,生成器也无法直接访问原始理解状态。 教程用多轮编辑说明这一问题。用户希望在连续对话中保持角色身份、构图和风格,只修改局部属性。流水线需要多次把图像转成语言、再把语言转回图像,容易在每一步丢失细节。真正的统一模型则共享隐藏状态,让理解和生成在同一上下文中直接交换信息。
统一带来的任务解锁
当输入与输出都可以是文本、图像、视频、音频或三维内容时,任务不再被固定成“图像到文本”或“文本到图像”。系统可以完成多轮图像编辑、交错图文创作、视觉推理后生成、生成结果自检,以及根据多模态反馈持续修改。 更长远的目标是认知层统一:模型不仅调用多个外部工具,而是在共享内部状态中感知、推理、生成与行动。教程借用“我无法创造的东西,我也无法真正理解”这一判断,强调生成能力可能成为检验理解深度的一种方式。
Part 2 Present I / 统一模型的目标与建模
统一模型究竟要统一什么
教程给出两个直接目标。第一是交错式文本—视觉建模:模型能够处理任意顺序的文本与视觉输入,并生成同样交错的输出。第二是统一理解、推理与生成任务:同一个模型不再为问答、编辑和生成维护彼此割裂的通道。 所谓统一,不只是把模型放进同一个产品界面,也不只是共享部分参数。更严格的判断标准包括:模态是否进入同一个序列或状态空间,理解与生成是否共享主干表示,训练目标能否共同优化,以及新任务是否能够通过组合已有能力自然出现。
三类建模主线
教程把文本和视觉的联合建模概括为三种主线:
- 扩散式统一模型:文本和视觉都通过扩散或掩码恢复过程建模。
- 自回归统一模型:把文本与视觉表示成令牌序列,使用统一的下一令牌预测。
- 自回归与扩散结合:语言、语义规划或离散视觉结构由自回归模型处理,最终像素生成交给扩散解码器。
图3:文本与视觉联合建模的主要排列组合。教程围绕扩散、自回归以及自回归与扩散结合的路线,比较视觉表示、生成目标和跨模态连接方式。来源:CVPR 2026 教程幻灯片第34页。
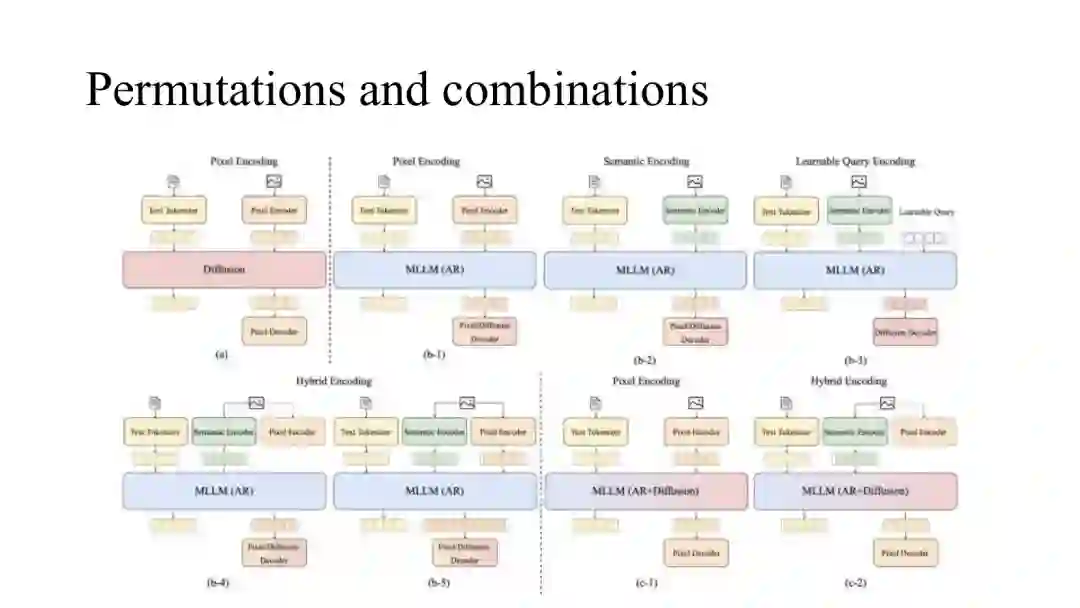 图3:文本与视觉联合建模的主要排列组合。教程围绕扩散、自回归以及自回归与扩散结合的路线,比较视觉表示、生成目标和跨模态连接方式。来源:CVPR 2026 教程幻灯片第34页。
图3:文本与视觉联合建模的主要排列组合。教程围绕扩散、自回归以及自回归与扩散结合的路线,比较视觉表示、生成目标和跨模态连接方式。来源:CVPR 2026 教程幻灯片第34页。扩散路线
扩散模型擅长连续空间中的高质量图像生成,也可以扩展到离散文本或多模态序列。其优点是生成质量高、训练目标稳定,并且能够通过条件控制处理复杂视觉分布。 教程同时指出三项局限。其一,离散或令牌空间的图像扩散在生成质量上仍可能弱于成熟的连续空间模型。其二,扩散过程较难自然支持灵活的交错多模态生成。其三,文本、视觉与混合序列的统一训练和推理基础设施仍不如自回归生态成熟。
自回归路线与视觉编码
自回归模型的优势是天然兼容大语言模型:只要把视觉压缩成令牌,就可以使用同一 Transformer 完成条件建模、上下文学习和序列生成。但视觉令牌如何构造,决定了模型究竟更擅长“看懂”还是“画好”。
# 重建导向编码
第一种方案使用 VQ-VAE、VAE 或其他图像重建编码器。它能保存颜色、纹理和空间细节,适合高保真生成,也便于将图像变成离散令牌进行自回归预测。问题是表示缺乏高层语义抽象,与文本空间的对齐能力较弱。
# 语义导向编码
第二种方案使用 CLIP、DINO 等语义编码器,或者针对语言对齐目标微调视觉编码器。它更适合理解、检索和推理,却会抑制精确重建所需的局部细节。教程引用统一分词器研究说明,单一视觉编码器同时承担理解和生成时,两个目标可能发生明显冲突。
# 可学习查询编码
第三种方案使用一组可学习查询从视觉特征中抽取固定数量的令牌。查询可以在训练中自适应选择信息,使视觉令牌更适合语言模型。但如果查询失败或容量不足,信息会在进入主干模型前丢失;而且生成仍可能被处理成理解表示之上的下游任务,并未真正消除表示分层。
# 混合编码
第四种方案同时保留重建表示与语义表示。伪混合方案让两套表示共享自回归主干但保持不同编码通道;联合混合方案则尝试在分词器或视觉编码阶段直接融合两类目标。它能缓解理解与生成的单边偏置,但会带来表示不匹配和优化冲突。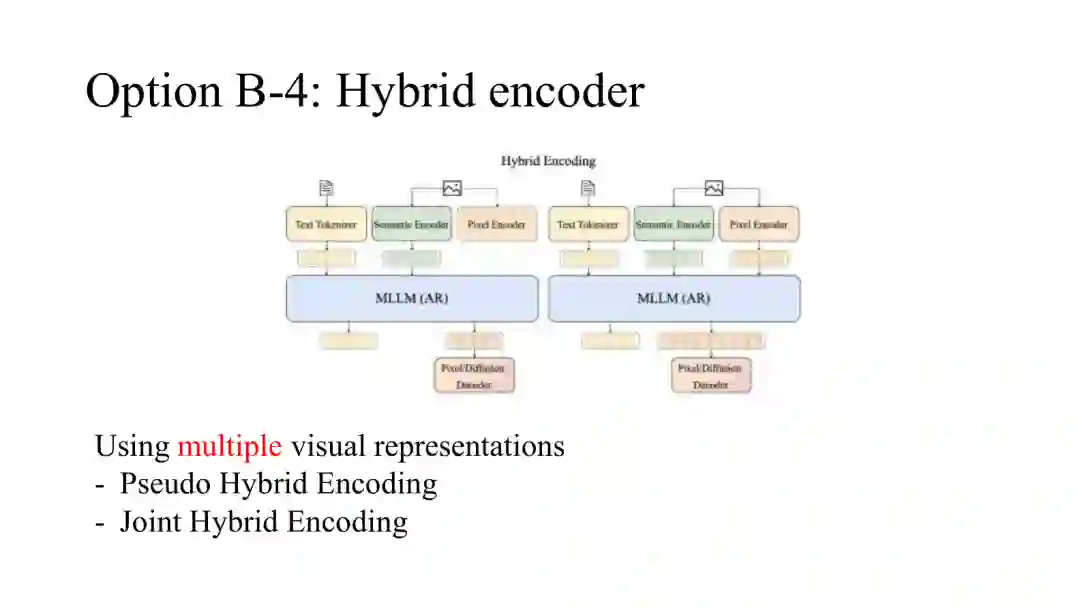
自回归与扩散结合
混合路线让自回归模型负责文本、语义、布局或视觉令牌的长程建模,再使用扩散模型生成最终像素。它利用了语言模型的推理与指令跟随能力,也保留扩散模型的高保真生成优势,因此成为当前统一多模态模型中的重要设计。 但混合路线仍有冗余编码与解码过程。模型可能先把图像压缩成语义或重建令牌,再经过主干网络,最后重新转入扩散潜空间。教程据此提出关键问题:什么样的视觉表示才真正适合统一多模态建模?理想表示应同时服务语义理解、可控生成、交错序列和高效训练,而不需要多套互相转换的编码器。
Part 3 Present II / 前沿亮点与趋势
教程把当前前沿从“如何共享一个模型”进一步推向“统一之后能够出现什么新能力”,归纳出六条趋势。
趋势一:无瓶颈视觉表示
传统统一模型通常依赖视觉编码器或 VAE 把图像压缩为令牌,这一步既降低计算量,也形成信息瓶颈。近期工作尝试移除固定视觉编码器,让原生图像块直接进入模型,或在生成像素前要求解码器先预测语义视觉表示。 完全去掉编码器虽然减少了人为瓶颈,却也可能失去视觉结构先验。教程展示的折中思路是:保留原生视觉输入,同时通过中间表示预测向模型施加结构约束,使模型既能访问细节,又能学习可迁移的语义组织。
趋势二:交错式任意模态生成
旧范式通常输出单一模态,例如文本生成图像或图像生成文本。新模型希望支持文本、图像、视频、音频和三维内容的任意组合输入与交错输出。 这一变化要求模型统一处理序列边界、模态位置、生成顺序和跨模态条件依赖。难点不只是增加更多解码头,而是让不同模态共享一个持续上下文:前面生成的图像会成为后续文本推理的依据,后续音频又可能反向约束下一帧视频。
趋势三:推理中心生成
传统图像生成通常从提示词直接采样结果。推理中心生成则在输出前显式经历分析、规划和验证,例如先理解空间关系、规划构图、检查文字与对象约束,再产生图像。 这种范式把生成从一次条件映射变成可检查的决策过程。测试时扩展不再只意味着增加采样次数,也可以增加推理轨迹、候选比较、自我验证和迭代修正。对于复杂编辑、带文字图像和物理约束场景,这种中间过程尤其重要。
趋势四:原生多模态认知统一
模块化系统常通过“视觉模型加语言模型加生成器”组合能力。原生多模态路线则希望模型从底层开始就以多模态形式学习概念、关系和行动,不再把视觉简单翻译成文字后推理。 教程展示的代表方向包括原生多模态链式思维,以及通过视觉状态、遮罩、编辑过程和生成结果共同表达推理。核心判断是:某些空间、几何和外观知识难以被纯文本充分承载,真正的多模态推理应允许中间思维本身包含视觉内容。
趋势五:后训练与统一奖励模型
统一模型的后训练不能只优化回答质量,也要同时覆盖理解正确性、生成保真度、编辑遵循度、安全性和跨模态一致性。教程介绍 UniGame 的自对抗后训练思路:让统一模型生成对抗样例或困难样本,再利用自身或外部反馈改进策略。 统一奖励模型则尝试用一个评价框架同时判断理解与生成。它需要处理文本偏好、视觉质量、条件遵循和事实一致性等不同信号。DPO、GRPO 等后训练方法可以扩展到多模态场景,但奖励是否可靠、不同目标如何加权,仍是关键问题。
趋势六:统一与混合模态评估
如果一个模型被称为统一模型,只在图像问答和文本到图像两个独立排行榜上取得高分还不够。评估需要覆盖混合模态任务、交错输出,以及推理、生成和验证的连续过程。
Part 4 Beyond Unified / 超越形式上的统一
理解帮助生成
更强的视觉理解能够提升生成中的对象关系、文字渲染、空间布局和指令遵循。统一模型不必仅依靠扩散过程从统计共现中恢复图像,而可以利用语义推理明确判断“应该生成什么、对象如何关联、哪些约束必须保持”。
生成帮助理解
反向关系同样重要。生成训练要求模型保留更丰富的视觉细节,因此可能改善理解任务中对材质、几何、遮挡和局部结构的感知。教程展示了重建式自编码框架和三维多视图建模中的结果,强调生成目标可以成为理解表示的补充监督。
走向世界模型与智能编辑
当模型能够理解当前状态、生成可能的未来并比较不同结果时,它就开始接近世界模型。统一编辑也不再只是局部像素修改,而可以被视为通用任务:模型理解用户意图、识别需要保持与改变的因素、规划操作,再验证编辑后的语义与视觉一致性。 这里的“超越统一”,意味着研究重点从是否共享参数转向能力之间是否真正互相促进。一个更有价值的统一模型,应该让理解提升生成、让生成反哺理解,并在多轮交互中形成持续一致的内部状态。
Part 5 Future / 未来与开放问题
视频与三维
图像统一主要处理二维静态内容,视频和三维则引入时间、几何与结构。模型需要保持跨帧身份一致性、理解相机运动、恢复空间关系,并在更长上下文中预测状态变化。视觉令牌数量和训练成本也会急剧增长。
统一世界模型
教程把未来闭环概括为:观察环境、推断状态、模拟未来、规划动作,再根据新观察更新内部模型。统一世界模型不仅生成看起来合理的视频,还应保存可行动的状态,预测动作后果,并支持反事实模拟。
具身智能
当输出从文字和图像扩展到行动,统一模型需要把感知、语言、生成和控制连接起来。机器人可以根据视觉与语言理解任务,通过世界模型模拟不同动作,选择计划并在执行后重新观察。这将统一多模态模型从内容模型推向物理人工智能。
仍待解决的核心问题
- 表示问题:能否形成同时保留语义、纹理、几何和动态信息的统一视觉表示?
- 计算问题:交错长序列、视频和三维令牌如何在可接受成本下训练与推理?
- 优化问题:理解、生成、编辑与行动目标发生冲突时,如何实现稳定的联合训练?
- 数据问题:如何构建高质量、多模态交错、包含推理与反馈的数据,而不是简单拼接现有数据集?
- 后训练问题:统一奖励模型能否可靠判断跨模态事实、视觉质量与任务完成度?
- 评估问题:如何测量能力之间是否真正协同,而非仅把多个孤立分数放在一起?
- 安全问题:理解偏差、生成偏差和行动风险如何在统一模型中传播与放大?
推荐阅读
教程官网列出的代表性工作包括:
- Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities:统一理解与生成模型综述。
- On Fairness of Unified Multimodal Large Language Models for Image Generation:研究统一多模态模型图像生成中的公平性。
- Is Your (Reasoning) Multimodal Language Model Vulnerable toward Distractions?:分析推理型多模态语言模型对干扰的脆弱性。
- ImageFolder: Autoregressive Image Generation with Folded Tokens:研究折叠令牌的自回归图像生成。
- Masked Autoencoders Are Effective Tokenizers for Diffusion Models:讨论掩码自编码器作为扩散模型分词器。
- Understanding Multimodal LLMs Under Distribution Shifts: An Information-Theoretic Approach:从信息论角度研究分布变化下的多模态大模型。
- Open-Vocabulary Calibration for Vision–Language Models:研究视觉语言模型的开放词汇校准。
- UniGame: Turning a Unified Multimodal Model Into Its Own Adversary:通过自对抗机制进行统一模型后训练。
总结
这场教程传递的核心判断是:统一多模态模型的下一阶段,不是简单把理解模型和生成模型放到同一个系统中,而是重新设计表示、主干、训练目标、后训练和评估,让不同能力在共享状态中互相促进。 当前最清晰的技术主线包括三类建模范式、四类视觉编码策略和六项前沿能力。真正决定统一程度的,不是模型能够调用多少模态,而是它能否在理解、推理、生成、验证和行动之间保持信息连续,并在面对视频、三维和物理环境时形成可更新的世界状态。
资料链接
- 教程官网 https://rollingsu.github.io/umm-tutorial.github.io/
- CVPR 2026 官方教程列表 https://cvpr.thecvf.com/Conferences/2026/Tutorials
- 教程幻灯片 Unified Models CVPR 2026 Tutorial Slides