

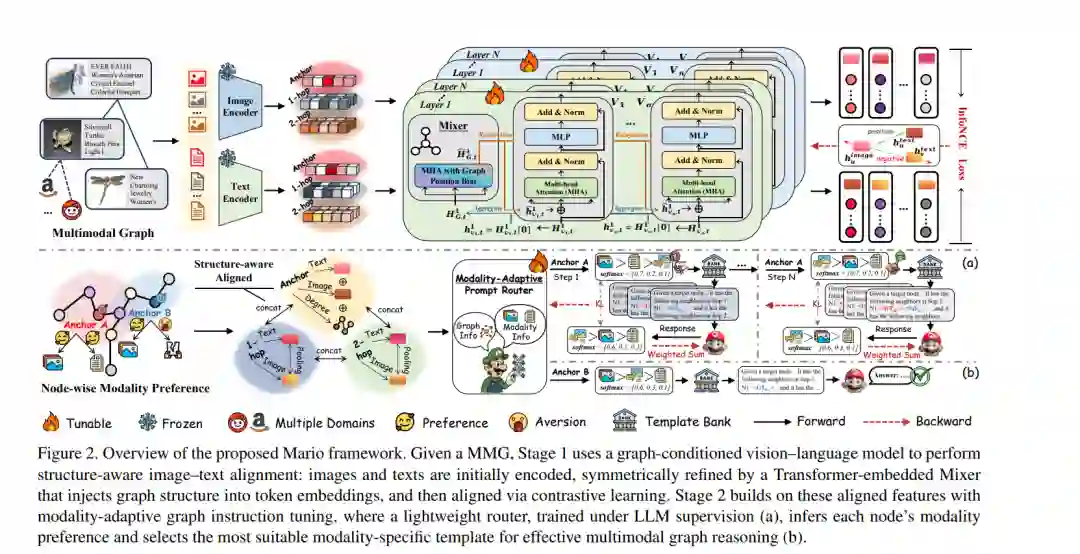
大语言模型(LLMs)的近期进展为多模态推理开辟了新途径。然而,现有方法大多仍依赖预训练的视觉-语言模型(VLMs)来孤立地对“图像-文本”对进行编码,忽略了现实世界多模态数据中天然存在的关联结构。这促使了对多模态图(Multimodal Graphs, MMGs)推理的研究——在这种图中,每个节点均具备文本和视觉属性,而边则提供结构化线索。 在保留图拓扑结构的同时,实现基于 LLM 的异构多模态信号推理面临两大核心挑战:解决跨模态一致性薄弱问题以及处理异构模态偏好。为应对这些挑战,我们提出了 Mario,这是一个能够同时解决上述难题并实现高效 MMG 推理的统一框架。 Mario 包含两个创新阶段: 1. 图条件化 VLM 设计:通过图拓扑引导的细粒度跨模态对比学习,协同优化文本与视觉特征。 1. 模态自适应图指令微调机制:将对齐的多模态特征组织为图感知指令视图(graph-aware instruction views),并利用可学习路由为每个节点及其邻域筛选出对 LLM 最具信息量的模态配置。
在多种 MMG 基准测试上的广泛实验表明,Mario 在节点分类和链路预测任务的监督学习及零样本(zero-shot)场景下,表现均持续优于现有的最先进图模型。相关代码将在 Mario 项目地址公开。
成为VIP会员查看完整内容
相关内容

最新内容
相关VIP内容
相关资讯