摘要——持续学习(Continual Learning, CL)已成为一种关键范式,旨在使大语言模型(LLMs)能够动态地适应不断演进的知识和顺序任务,同时缓解灾难性遗忘(Catastrophic Forgetting)——这是现代 LLM 固有静态预训练范式的一项重大缺陷。本综述全面概述了针对 LLM 量身定制的持续学习方法论,并围绕三个核心训练阶段进行构建:持续预训练、持续微调和持续对齐。除了基于重放、正则化和架构的传统方法分类外,本文还根据其独特的遗忘缓解机制对各类别进行了进一步细分,并对传统持续学习方法在 LLM 中的适应性及关键改进进行了严谨的对比分析。在此过程中,我们明确强调了 LLM 持续学习与传统机器学习之间的核心差异,特别是在规模、参数效率以及涌现能力方面。我们的分析涵盖了关键评估指标(包括遗忘率和知识迁移效率)以及用于评估持续学习性能的新兴基准。综述表明,尽管当前方法在特定领域取得了显著成果,但在跨多样化任务和时间尺度实现无缝知识整合方面,仍存在根本性的挑战。本系统性综述为不断发展的 LLM 适配研究做出了贡献,为研究人员和从业者理解语言模型终身学习的现状与未来机遇提供了一个结构化框架。 索引词——大语言模型,持续学习,自然语言处理,灾难性遗忘
自 Transformer 架构 [1] 问世以来,大量基于 Transformer 的预训练语言模型相继涌现并得到广泛应用,其中以 BERT [2]、GPT [3] 和 LLaMA [4] 等开创性工作为代表。通过在海量多样化语料库上进行大规模预训练,这些大语言模型(LLMs)展现出了“涌现能力”(Emergent Capabilities),这为**缩放法则(Scaling Law)**提供了直接的经验证据——即模型性能与泛化能力随参数量和训练数据规模的增加而系统性提升。因此,LLM 在广泛的自然语言处理(NLP)任务中达到了先进(State-of-the-art)水平,展现出强大的泛化能力、上下文学习能力和指令遵循能力,从而为现代 NLP 研究确立了变革性范式 [5]。
然而,LLM 的成功本质上受限于静态预训练范式,这与现实世界场景动态且不断演变的本质形成了鲜明对比。首先,现实世界的特征是永恒的变迁:新知识、新概念、新事件和新的语言用法层出不穷,这使得策划一个能够封装所有潜在信息的单一穷尽式数据集变得不可行。其次,严格的数据隐私法规和伦理约束限制了敏感或私有数据的采集,进一步削弱了预训练语料库的完整性与全面性。第三,在更新后的数据上对 LLM 进行重新预训练的成本极其高昂——模型与数据集的巨大规模带来了沉重的计算与财务负担,使得通过全量重训来实现频繁的知识更新变得不切实际。相比之下,人类大脑表现出卓越的增量学习能力:它能够获取新知识而不对先前技能产生灾难性遗忘,同时调整现有知识以适应新情况。受此生物智能启发,迫切需要大语言模型模拟此类能力——具体而言,即从新数据或任务中进行增量学习,保留预先获得的知识,并动态适应不断变化的现实场景。LLM 的静态预训练范式与现实世界知识的固有动态性之间的这种关键错位,使 LLM 持续学习成为了一个至关重要且高优先级的研究方向。
作为机器学习(ML)、计算机视觉(CV)和自然语言处理(NLP)领域 [6] 中成熟的范式,持续学习使神经网络能够顺序学习一系列领域语料或下游任务。对于 LLM 而言,它已成为以极低成本融入新知识并保留现有专业知识的一种极具前景的方案。实验证据 [7] 证实,将持续学习方法应用于预训练 LLM,不仅能更新其内部知识库,还能显著提升特定任务的性能。与从头开始训练相比,持续学习利用预先获得的知识大幅降低了计算开销并提高了训练效率,同时维持了先进的性能——这种效率与适配性的独特协同作用,为 LLM 在现实场景中的部署奠定了坚实基础,直接解决了动态知识演进中静态预训练所面临的核心挑战。
目前已有若干关于 LLM 持续学习(CL)的综述,但它们存在明显的局限性。具体而言,文献 [8] 将 LLM CL 划分为三个阶段(持续预训练、领域自适应预训练、持续微调),并分析了跨领域(如医疗、法律、金融)的方法及核心挑战(如语言漂移、内容漂移),但缺乏基于底层机制的 CL 方法细粒度分类。类似地,文献 [9] 虽然也采用了三阶段划分,但侧重于应用场景而非方法论类型或灾难性遗忘缓解机制。尽管文献 [10] 对 LLM CL 进行了细粒度的方法论分析,但既未将 CL 过程划分为不同的训练阶段,也未专门聚焦于 LLM,而是涵盖了更广泛的生成式 AI 模型(如多模态模型、扩散模型)。
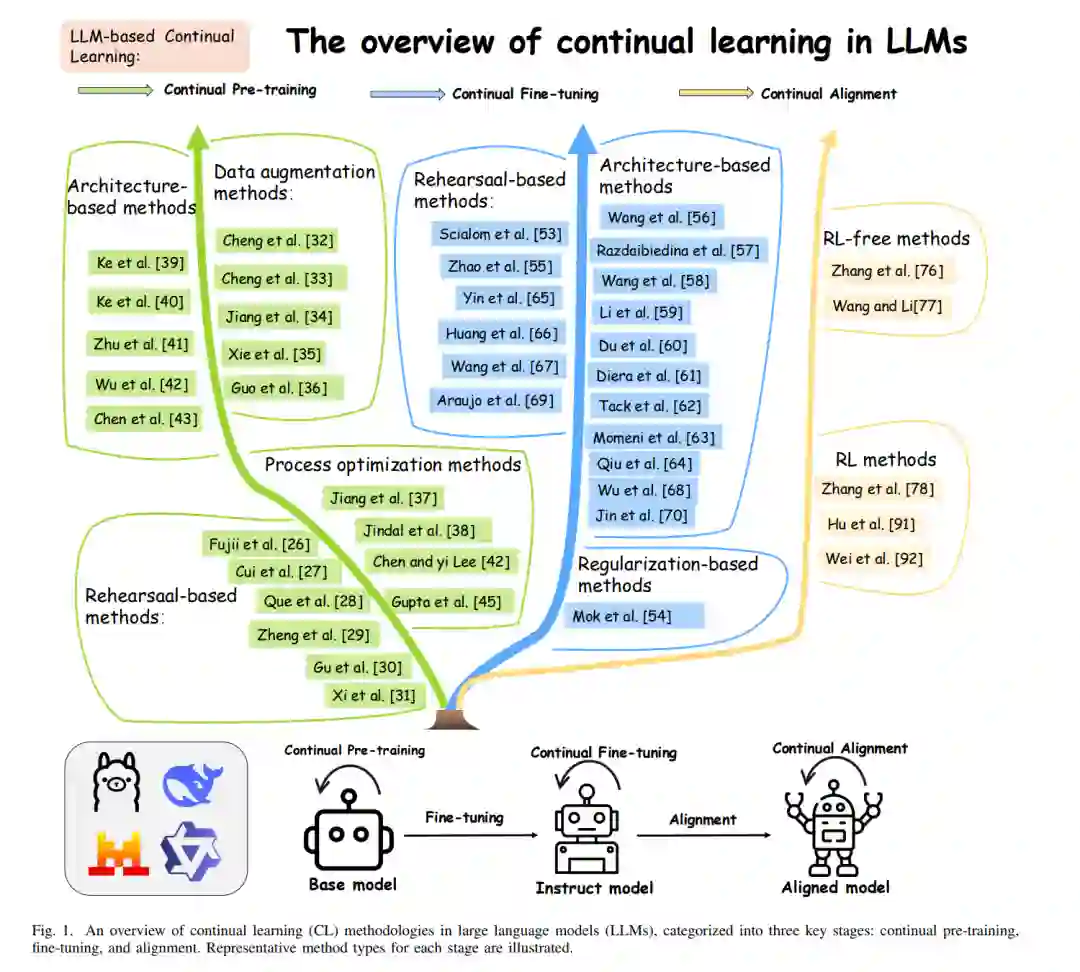
与这些工作不同,本综述专精于大语言模型的持续学习。我们围绕三个专用阶段——持续预训练、持续微调和持续对齐——展开讨论,并系统性地评述了每个阶段的前沿方法论。除了传统持续学习的标准分类(即基于重放、基于正则化和基于架构的方法)之外,我们还根据缓解灾难性遗忘的独特机制,对每个类别下的方法进行了进一步细分,并对针对 LLM 量身定制的同类传统 CL 方法的适配性及关键改进进行了深入的对比分析。通过这些工作,我们旨在加深对 LLM 高效持续学习部署的理解,为未来的研究方向提供启示,并解决 CL 与 LLM 融合过程中的关键挑战。