

论文地址: https://www.arxiv.org/abs/2602.07801 项目主页: https://liuwq-bit.github.io/VideoTemp-o3
随着多模态大模型的飞速发展,AI模型开始具备“看懂世界”的能力。然而在现实场景中,视频往往动辄数十分钟甚至上小时:信息密度高、关键证据稀疏且分布不均。如何让AI模型像人类一样高效、准确地理解视频内容,成为学术界和工业界共同关注的焦点。
近日,快手科技联合山东大学、自动化所、北京航空航天大学、南方科技大学在长视频理解方向取得进展,推出全新的长视频理解框架——VideoTemp-o3。围绕长视频真实应用中“高效定位 + 证据驱动回答”的一体化需求,研究团队提出统一的 Agentic 模型范式与配套训练体系,使长视频时序定位(Temporal Grounding)与视频理解(Video Understanding)在同一框架中协同优化,显著简化推理链路,并在多项权威基准测试上实现全面提升。现已被ICML 26接收,代码、模型权重及训练数据现已全部开源。
受 Think-with-Images 相关工作启发,本研究以 Thinking-with-Videos 为核心范式,将“定位-裁剪-回答(localize-clip-answer)”从流程层面升级为统一且灵活的 Agentic 框架。相比传统将定位与问答拆分为多个模块、彼此割裂的方案,VideoTemp-o3 在单一模型内实现多轮自我修正与证据验证式推理,兼顾长视频复杂场景下的定位精度和回答可靠性,为长视频理解提供了更接近实际落地的技术路径。
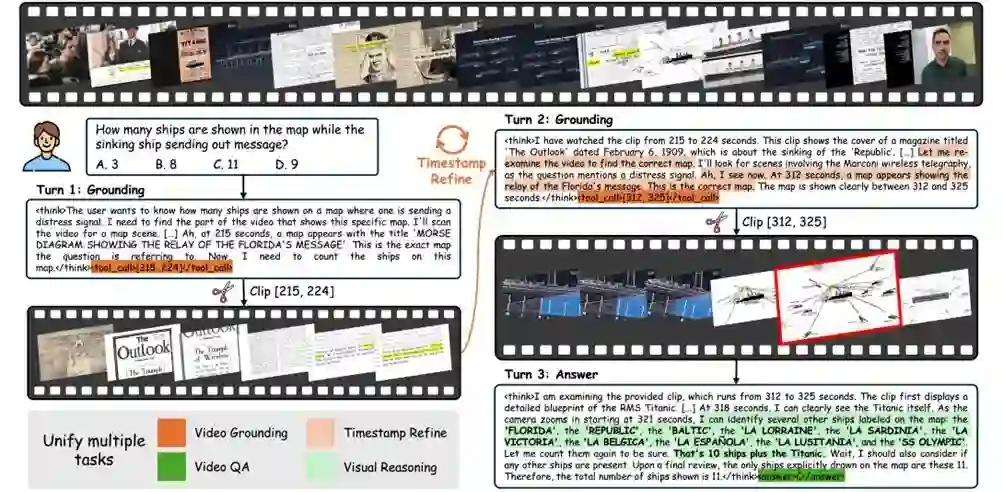
VideoTemp-o3流程示意图
挑战与瓶颈:长视频理解面临的“三座大山”
长视频理解并非易事,由于时间跨度长、信息分布稀疏,传统“均匀帧采样”往往难以捕捉回答所需的关键视觉证据。为应对这一挑战,近期研究界提出“Thinking-with-Videos”范式,通过“定位-裁剪-回答”的策略让模型主动识别相关片段并进行密集采样。但在快手科技面向大规模视频内容理解的实践中,现有方法仍然普遍存在三大痛点: **1. 工作流程复杂(Workflow complexity):**以来多个独立模型分别完成定位与问答,推理开销大、系统工程复杂,难以在实际场景中稳定部署。 **2. 定位精度不足(Imprecise grounding):**缺乏对定位结果的有效评估与优化机制,模型难以稳定找到真正支撑答案的时间片段。 **3. 流程僵化,缺乏灵活性(Rigid pipelines):**一次定位后立即回答,无法根据定位质量动态调整;既造成短视频场景的算力浪费,也限制复杂长视频场景下的迭代式定位优化。
数据构建:高质量多轮GQA数据的“炼金术”
研究团队认识到,要让模型真正学会“像人一样在长视频中找证据”,高质量、可迭代的视频定位监督数据至关重要。为此设计了一套用于多轮视频定位的数据构建流程,用于生成大规模长视频 GQA(Grounded Question Answering)训练数据,为后续统一框架训练提供关键支撑。
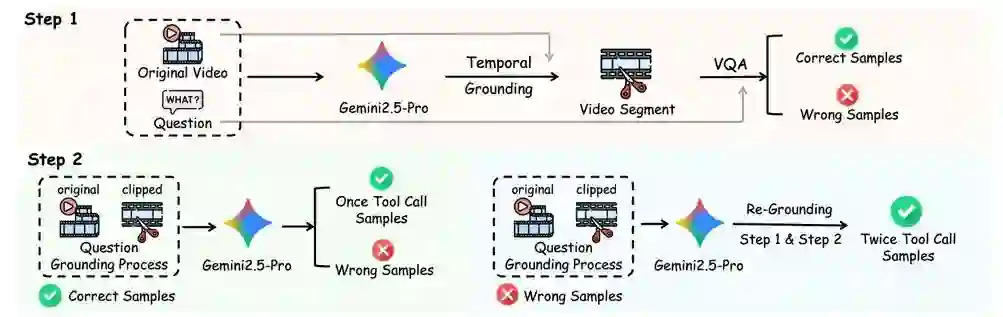
数据构建流程示意图
该流程的核心创新体现在三方面: **1. 高度对齐的高质量标注:**同时提供精准时间片段与对应答案,确保“视觉证据”与“文本回复”严格对齐,减少训练中的弱监督偏差。 **2. 模拟真实Agent的多轮交互:**通过工具辅助定位的方式,模拟“定位、裁剪、验证”的迭代行为,构建多轮训练样本,让模型在训练中习得持续修正与逐步收敛的能力。 **3. 片段级视频验证机制:**在构建环节引入验证步骤,严格评估候选片段能否为推理链提供充分证据,从源头保障数据质量与训练可靠性。 除标准流程外,快手科技进一步为强化学习阶段的训练数据提供人工标注与校验,清理潜在噪声,提升强化信号稳定性与可靠性,确保模型在长视频分布上的鲁棒性。 同时,为系统评估模型在不同时间尺度下的定位与理解能力,团队提出 VideoTemp-Bench。与现有主要聚焦短视频(<3分钟)的GQA数据集不同,VideoTemp-Bench 将视频按时长划分为 0–3分钟、3–10分钟、10–20分钟、20分钟以上四档,覆盖更贴近真实内容平台的长视频分布,为行业评测提供了更完整的观察维度。
方法简介:VideoTemp-o3,统一且灵活的Agentic框架
基于上述高质量数据与训练范式,研究团队采用“冷启动监督微调(SFT)+强化学习(RL)”两阶段训练,推出 VideoTemp-o3:一个统一的 Agentic Thinking-with-Videos 模型,实现视频时序定位与问题回答的联合建模。 在冷启动阶段,团队使用构建的数据对模型进行监督微调,使其能够通过主动裁剪相关片段,从关键视觉证据中生成可靠答案,并融入三项面向落地的能力设计: **1. 按需裁剪:**短视频可直接高效作答,无需额外裁剪与重复推理; **2. 反思机制:**面对复杂长视频,模型可多次修正初始定位,实现多轮优化; **3. 定位与问答统一格式建模:**以一致的多轮对话格式同时支持视频QA与时间定位,提升定位能力的同时强化理解一致性。 为降低训练噪声、增强多轮推理稳定性,团队提出统一掩码策略:仅监督多轮对话中最后两轮(准确定位与最终回答),屏蔽早期不精确定位带来的错误梯度,显著提升训练收敛质量。
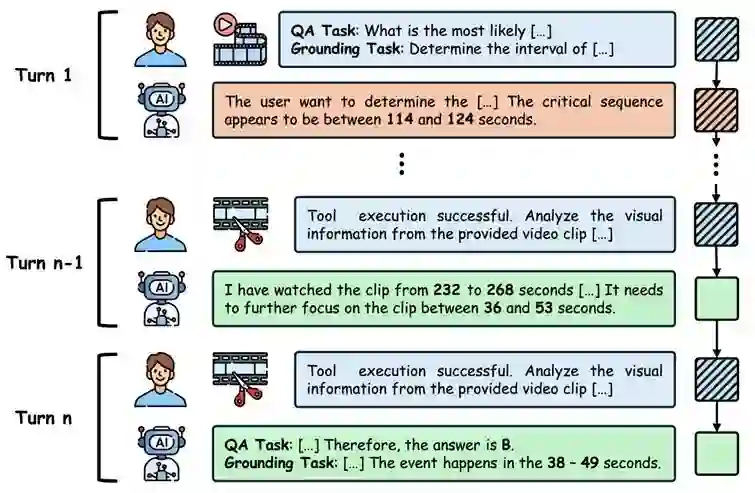
统一掩码策略,仅监督最后两轮的正确定位与回答
在强化学习阶段,团队设计了专属奖励机制,系统答案正确率、格式规范与时间定位能力。该奖励由三项构成: **1. 准确率奖励:**仅当输出与标准答案完全一致时给予奖励,提升模型回答准确性:
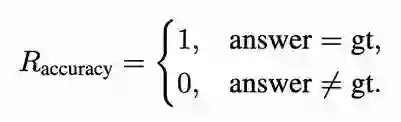
**2. 格式奖励:**确保多轮交互始终遵循规定格式,便于稳定解析与工具调用:
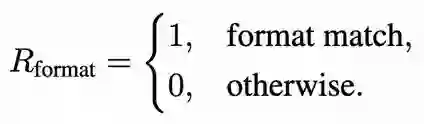
**3. 带惩罚机制的IoU奖励:**以预测区间与真实区间的 IoU 衡量定位质量,并在 IoU 低于阈值时扣减奖励,抑制随意定位与“投机”行为,促使模型稳定学会高质量的多轮定位与裁剪策略:
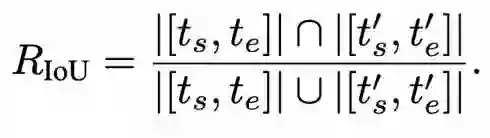
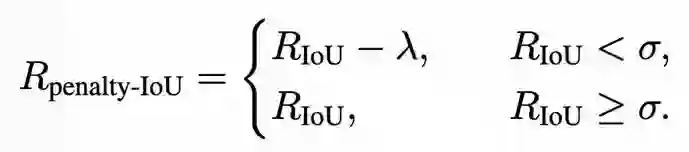
实验效果:多项Benchmark性能显著提升
研究团队在 Qwen2.5-VL-7B 上训练 VideoTemp-o3,并在长视频理解(MLVU、VideoMMMU、VideoMME、LVBench)、时间定位(Charades-STA、ActivityNet-MR)以及视频GQA(NextGQA、ReXTime)等任务上进行系统评测,展示出富有竞争力的性能优势。
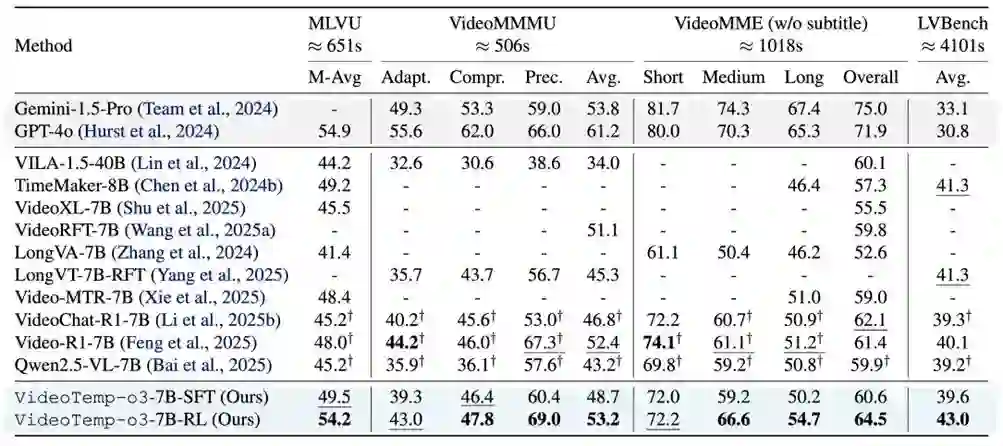
VideoTemp-o3与baseline在多个长视频理解Benchmark上的效果对比
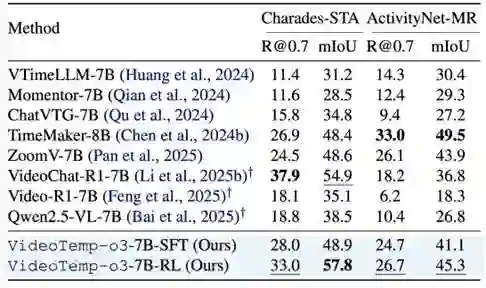
时间定位Benchmark效果对比
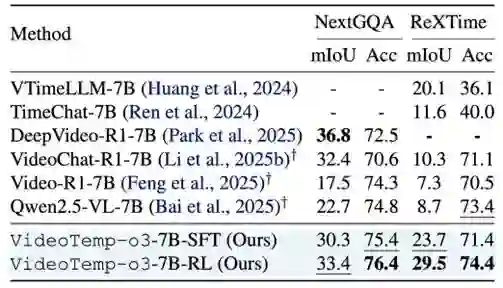
视频GQA Benchmark效果对比
此外,团队在自建的 VideoTemp-Bench 上开展了更细粒度的评测,系统对比同类视频理解模型在不同视频时长区间下的 GQA 表现。实验结果表明,VideoTemp-o3 在该基准上整体性能领先,并在长视频设置中优势更加明显。
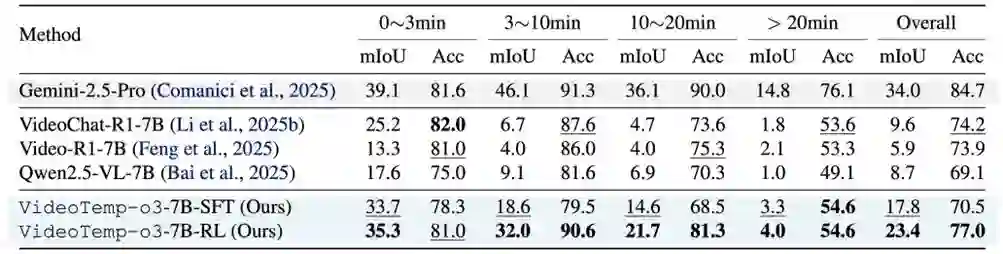
VideoTemp-Bench上的效果对比
消融实验进一步验证:结合 Grounding 数据进行 SFT 与 RL 训练,不仅直接提升定位性能,还会隐式增强视频QA准确率,实现定位与理解的相辅相成;统一掩码策略与奖励设计对稳定训练与性能提升同样关键。
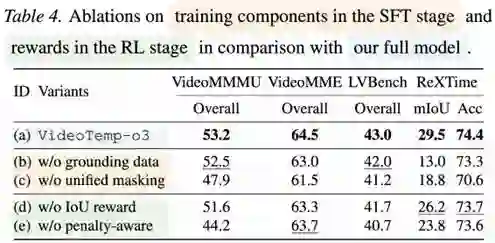
消融实验效果对比
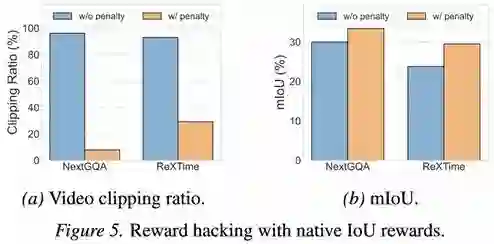
IoU奖励惩罚机制对视频裁剪 与定位效果的影响 **
**
结语
本研究聚焦 Thinking-with-Videos 范式,提出统一长视频理解框架 VideoTemp-o3。该框架以“定位-裁剪-回答”为核心,通过主动寻找与问题相关的关键片段,实现证据驱动的可靠问答;并通过按需裁剪、多轮反思优化、定位与问答统一建模等设计,兼顾效率与精度。快手科技在数据构建、训练体系与推理机制设计上深度参与并推动关键环节的研究进展,通过统一掩码策略与定制奖励函数有效提升模型行为质量,高质量多轮数据构建与人工校验进一步保障强化学习稳定性。最终,VideoTemp-o3 在多个长视频理解与定位 Benchmark 上取得领先或显著提升的效果。